ĪĪĪĪį┌Ų¾śIĪóīWąŻ║═Ė„ŅÉĘ■äš╠ß╣®╔╠Ą─ėŗ╦Ńųąą─Į©įOųąŻ¼öĄō■ÄņĄ─┤ŅĮ©Š▀ėąųžę¬Ą─Ąž╬╗ĪŻČ°×ķ┴╦ØMūŃæ¬ė├Ą─ąĶŪ¾Ż¼ąĶę¬▓╗öÓĄž╠ßĖ▀║═Ė³ą┬ė▓╝■įO╩®Ż¼▀@╩Ūę╗╣PŠ▐┤¾Ą─ķ_õNĪŻ▓óŪęļSų°öĄō■┴┐Ą─į÷╝ė║═Ę■äššłŪ¾Ą─į÷ķLŻ¼é„ĮyöĄō■ÄņīóĢ■├µ┼RųTČÓå¢Ņ}Ż║
ĪĪĪĪ1)┐╔öUš╣ąį▓ŅŻ║é„ĮyöĄō■▓╗╩Ū×ķ┤¾ęÄ─Ż┐╔╔ņ┐sĄ─Ęų▓╝╩Į╠Ä└ĒįOėŗĄ─Ż¼ļm╚╗ę▓╠ß╣®Å═ųŲ║═Ęųģ^Ą─ĮŌøQĘĮ░ĖŻ¼Ą½▓╗─▄Å─Ė∙▒Š╔ŽĮŌøQå¢Ņ}Ż¼▓óŪęĘŪ│Żļyęį░▓čb║═ŠSūoŻ¼╔§ų┴ę¬Ā▐╔³ę╗ą®é„ĮyRDBMS(Relational DataBase Management SystemŻ║ĻPŽĄą═öĄō■Äņ)Ą─ųžę¬╠žąįŻ¼▓╗ØMūŃÅŚąįąĶŪ¾Ą─ę¬Ū¾Ż╗
ĪĪĪĪ2)║Ż┴┐öĄō■Śl╝■Ž┬ūxīæąį─▄Ą═Ž┬Ż║«ööĄō■╗“▓ó░lė├æ¶│¼▀^─│éĆöĄ┴┐╝ē║¾Ż¼ąį─▄╔ŽĢ■ėą├„’@Ž┬ĮĄŻ¼▓╗─▄ØMūŃĖ▀▓ó░lūxīæĄ─Ę■äššłŪ¾Ż╗
ĪĪĪĪ3)╣▄└ĒÅ═ļs└¦ļyŻ║é„ĮyöĄō■ÄņĄ─ŠSūoę¬Ū¾╚╦åTīŻśIąįÅŖŻ¼╣▄└Ē╚╦åTę¬▀Mąąć└Ė±Ą─┼Óė¢Ż¼ī”öĄō■Ą─╣▄└Ē║═ŠSūoÅ═ļsŻ╗
ĪĪĪĪ4)▀\ąąŠSūo│╔▒ŠĖ▀Ż║é„ĮyöĄō■Äņ║▄ļy▀Mąą╔²╝ē║═Ė³ą┬Ż¼«ö¼FėąöĄō■Äņ▓╗─▄ØMūŃæ¬ė├ąĶŪ¾Ą─Ģr║“ę╗░Ń╩Ū╚½▓┐▓╔ė├ą┬Ą─Ė³ÅŖ┤¾Ą─ė▓╝■║═ą┬░µ▒ŠĄ─▄ø╝■Ż¼▀@śė▓╗āHąĶꬊ▐┤¾Ą─ķ_õNŻ¼▀ĆĢ■╩╣öĄō■ÄņĢ║═ŻĘ■䚯¼į┌║▄ČÓł÷║Ž▀@╩Ū▓╗─▄╚▌╚╠Ą─ĪŻ
ĪĪĪĪ1ĪóįŲöĄō■Äņ╝╝ągĄ─░lš╣║═ā׳c
ĪĪĪĪé„ĮyöĄō■Äņį┌ę╗Č©│╠Č╚╔ŽØMūŃ┴╦─┐Ū░é„ĮyĄ─æ¬ė├ąĶŪ¾Ż¼Ą½╩Ūė╔ė┌Ųõūį╔ĒĄ─╚▒Ž▌║═ą┼Žó╝╝ągĄ─░lš╣Ż¼╠žäe╩Ūį┌įŲėŗ╦ŃŲĮ┼_╔Ž║Ż┴┐öĄō■Ą─╣▄└Ē║═æ¬ė├Ą─▒│Š░ų«Ž┬Ż¼įŲöĄō■Äņ│╔×ķą┬ę╗┤·öĄō■ÄņĄ─░lš╣ĘĮŽ“Ż¼čąŠ┐įŲöĄō■ÄņŠ▀ėąųž┤¾Ą─ęŌ┴xĪŻ
ĪĪĪĪįŲėŗ╦Ń░┤ššĘ■äšŅÉą═┤¾ų┬┐╔ęįĘų×ķ╚²ŅÉ Ż║IaaS(Infrastructure as a ServiceŻ║╗∙ĄAįO╩®╝┤Ę■äš)ĪóPaaS(Platform as a ServiceŻ║ŲĮ┼_╝┤Ę■äš)║═SaaS(Software as a ServiceŻ║▄ø╝■╝┤Ę■äš)ĪŻįŲöĄō■Äņ╩Ūį┌SaaS│╔×ķæ¬ė├┌ģä▌Ą─┤¾▒│Š░Ž┬░lš╣ŲüĒĄ─įŲėŗ╦Ń╝╝ągŻ¼╦³śO┤¾Ąžį÷ÅŖ┴╦öĄō■ÄņĄ─┤µā”─▄┴”Ż¼Ž¹│²┴╦┘Yį┤Ą─ųžÅ═┼õų├Ż¼ūī▄øĪóė▓╝■╔²╝ēūāĄ├Ė³╝ė╚▌ęūĪŻįŲöĄō■ÄņŠ▀ėąĖ▀┐╔öUš╣ąįĪóĖ▀┐╔ė├ąįŻ¼▓╔ė├ČÓūŌæ¶ą╬╩Į║═ų¦│ų┘Yį┤ėąą¦Ęų░lĄ╚╠ž³cĪŻ┐╔ęįšfŻ¼įŲöĄō■Äņ┤·▒Ēų°öĄō■Äņ╝╝ąg╬┤üĒ░lš╣Ą─ę╗ĘNų„┴„ĘĮŽ“ĪŻ─┐Ū░Ż¼ī”ė┌įŲöĄō■ÄņĄ─Ė┼─ŅČ©┴x▓╗▒MŽÓ═¼Ż¼╬─ųąįŲöĄō■ÄņČ©┴x╩ŪŻ║įŲöĄō■Äņ╩Ū▓┐╩į┌įŲėŗ╦ŃŁhŠ│ųąĄ─öĄō■ÄņĪŻ
ĪĪĪĪį┌įŲöĄō■Äņæ¬ė├ųąŻ¼┐═æ¶Č╦▓╗ąĶę¬┴╦ĮŌįŲöĄō■ÄņĄ─Ąūīė╝Ü╣ØŻ¼╦∙ėąĄ─Ąūīėė▓╝■║═īŹ¼Fī”┐═æ¶Č╦Č°čį╩Ū═Ė├„Ą─Ż¼╦³Š═Ž±į┌╩╣ė├ę╗éĆ▀\ąąį┌▒ŠĄžĄ─öĄō■Äņę╗śėŻ¼ĘŪ│ŻĘĮ▒Ń║åå╬Ż¼═¼Ģrėų┐╔ęį½@Ą├└Ēšō╔ŽĮ³║§¤oŽ▐Ą─┤µā”║═╠Ä└Ē─▄┴”ĪŻŠ▀ėą╚ńŽ┬ā׳cŻ║
ĪĪĪĪäėæB┐╔öUš╣Ż║└Ēšō╔ŽŻ¼įŲöĄō■ÄņŠ▀ėą¤oŽ▐┐╔öUš╣ąįŻ¼┐╔ØMūŃ▓╗öÓį÷╝ėĄ─öĄō■┤µā”ąĶŪ¾ĪŻį┌├µī”▓╗öÓūā╗»Ą─Śl╝■ĢrŻ¼įŲöĄō■Äņ┐╔▒Ē¼F│÷║▄║├Ą─ÅŚąįĪŻ╚ńŻ║ī”ė┌ę╗éĆÅ─╩┬«aŲĘ┴Ń╩█Ą─ļŖūė╔╠äš╣½╦ŠŻ¼Ģ■┤µį┌╝Š╣Øąį╗“═╗░ląįĄ─«aŲĘąĶŪ¾ūā╗»Ż╗╗“š▀ī”ė┌ŠWĮj╔ńģ^šŠ³cŻ¼┐╔─▄Ģ■ĮøÜvę╗éĆųĖöĄ╝ēĄ─į÷ķLļAČ╬ĪŻ▀@ĢrŻ¼Š═┐╔ęįĘų┼õŅ~═ŌĄ─öĄō■Äņ┤µā”┘Yį┤üĒ╠Ä└Ēį÷╝ėĄ─ąĶŪ¾Ż¼Ųõ▀^│╠ų╗ąĶÄūĘųńŖĪŻę╗Ą®ąĶŪ¾▀^╚źęį║¾Ż¼Š═┐╔┴ó╝┤ßīĘ┼▀@ą®┘Yį┤ĪŻ
ĪĪĪĪĖ▀┐╔ė├ąįŻ║▓╗┤µį┌å╬³c╩¦ą¦å¢Ņ}ĪŻ╚ń╣¹ę╗éĆ╣سc╩¦ą¦┴╦Ż¼╩ŻėÓĄ─╣سcŠ═Ģ■Įė╣▄╬┤═Ļ│╔Ą─╩┬äšĪŻČ°Ūęį┌įŲöĄō■ÄņųąŻ¼öĄō■═©│Ż╩ŪÅ═ųŲĄ─Ż¼į┌Ąž└Ē╔Žę▓╩ŪĘų▓╝Ą─ĪŻųT╚ńGoogleŻ¼Amazon ║═IBM Ą╚┤¾ą═įŲėŗ╦Ń╣®æ¬╔╠Š▀ėąĘų▓╝į┌╩└ĮńĘČć·ā╚Ą─öĄō■ųąą─Ż¼═©▀^į┌▓╗═¼Ąž└Ēģ^ķgā╚▀MąąöĄō■Å═ųŲŻ¼┐╔ęį╠ß╣®Ė▀╦«ŲĮĄ─╚▌Õe─▄┴”ĪŻ└²╚ńŻ¼Amazon SimpleDB Ģ■į┌▓╗═¼Ą─ģ^ķgā╚▀MąąöĄō■Å═ųŲŻ¼ę“┤╦Ż¼╝┤╩╣š¹éĆģ^ė“ā╚Ą─įŲįO╩®░l╔·╩¦ą¦Ż¼ę▓─▄▒ŻūCöĄō■└^└m┐╔ė├ĪŻ
ĪĪĪĪ▌^Ą═Ą─╩╣ė├┤·ārŻ║═©│Ż▓╔ė├ČÓūŌæ¶(multi -tenancy)Ą─ą╬╩ĮŻ¼▀@ĘN╣▓ŽĒ┘Yį┤Ą─ą╬╩Įī”ė┌ė├æ¶Č°čį┐╔ęį╣Ø╩Īķ_õNŻ╗Č°Ūęė├æ¶▓╔ė├░┤ąĶĖČ┘MĄ─ĘĮ╩Į╩╣ė├įŲėŗ╦ŃŁhŠ│ųąĄ─Ė„ĘN▄øĪóė▓╝■┘Yį┤Ż¼▓╗Ģ■«a╔·▓╗▒žę¬Ą─┘Yį┤└╦┘MĪŻ┴Ē═ŌŻ¼įŲöĄō■ÄņĄūīė┤µā”═©│Ż▓╔ė├┤¾┴┐┴«ārĄ─╔╠śIĘ■äšŲ„Ż¼▀@ę▓┤¾┤¾ĮĄĄ═┴╦ė├æ¶ķ_õNĪŻ
ĪĪĪĪęūė├ąįŻ║╩╣ė├įŲöĄō■ÄņĄ─ė├æ¶▓╗ė├┐žųŲ▀\ąąįŁ╩╝öĄō■ÄņĄ─ÖCŲ„Ż¼ę▓▓╗▒ž┴╦ĮŌ╦³╔Ēį┌║╬╠ÄĪŻė├æ¶ų╗ąĶę¬ę╗éĆėąą¦Ą─µ£ĮėūųĘ¹┤«Š═┐╔ęįķ_╩╝╩╣ė├įŲöĄō■ÄņĪŻ┤¾ęÄ─Ż▓óąą╠Ä└ĒŻ║ų¦│ųÄū║§īŹĢrĄ─├µŽ“ė├æ¶Ą─æ¬ė├Īó┐ŲīWæ¬ė├║═ą┬ŅÉą═Ą─╔╠äšĮŌøQĘĮ░ĖĪŻ
ĪĪĪĪ2Īóų„┴„Ą─įŲöĄō■Äņ«aŲĘ║═▒╚▌^
ĪĪĪĪĮø▀^Į³Äū─ĻĄ─░lš╣Ż¼Ė„Ų¾śIĖ∙ō■ūį╔ĒĄ─śIäšąĶŪ¾║═öĄō■╠žš„įOėŗ┴╦Ė„ūįĄ─įŲöĄō■ÄņŻ¼═©▀^ī”«öŪ░įŲöĄō■Äņ╩ął÷Ą─š{▓ķŻ¼ĮY╣¹╚ń▒Ē1 ╦∙╩ŠĪŻ
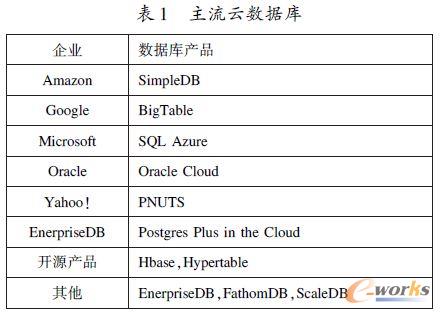
ĪĪĪĪ╩╣ė├įŲöĄō■ÄņŲĮ┼_┐╔ęįų▒Įė▓╔ė├AmazonĪóMicrosoftĪóOracle Ą─įŲ┤µā”ĮŌøQĘĮ░ĖŻ¼Ą½╩ŪĮ©įO▀@śėĄ─ŲĮ┼_┤·ār║▄┤¾Ż¼ī”Įø┘Mę¬Ū¾║▄Ė▀ĪŻ═¼Ģrę▓┐╔ęį▓╔ė├HBaseĪóHypertable Ą╚ķ_į┤Ą─ĮŌøQĘĮ░ĖŻ¼▀@ļm╚╗├Ō┘M▓óŪę┐╔ęįĖ∙ō■ūį╔Ēæ¬ė├ū÷ŽÓæ¬Ą─ā×╗»Ż¼Ą½╩Ūī”╝╝ągę¬Ū¾║▄Ė▀Ż¼║¾Ų┌ķ_░lŠ▀ėąę╗Č©ļyČ╚ĪŻ×ķ┴╦▀x╚Ī║Ž▀mĄ─įŲöĄō■ÄņŻ¼ī”Ė„éĆ«aŲĘ▀Mąą┴╦ī”▒╚ĪŻ
ĪĪĪĪ2.1ĪĪAmazon Ą─SimpleDB
ĪĪĪĪSimpleDB╩ŪAmazon ╠ß╣®Ą─║åå╬öĄō■ÄņĘ■䚯¼ų„ę¬ė├ė┌┤µā”ĮYśŗ╗»öĄō■Ż¼▓ó×ķöĄō■╠ß╣®▓ķšęĪóäh│²Ą╚╗∙▒ŠĄ─Ę■䚯¼ŲõŠ▀¾wĄ─īŹ¼F╝Ü╣ØAmazon ø]ėą╣½ķ_ĪŻė╔ė┌Amazon ų„ę¬╩Ū╠ß╣®╔╠śIąįĄ─Ę■䚯¼╩╣ė├ŲõĘ■äšąĶę¬ę╗éĆAmazon Ą─Äżæ¶Ż¼─Ū├┤ę╗éĆė├æ¶Äżæ¶Š═ŽÓ«öė┌╚½╝»Ż¼Č°Š▀¾wĄ─öĄō■ätŽÓ«öė┌ūė╝»ĪŻė╔ė┌SimpleDB║åå╬Ą─öĄō■┤µā”ĘĮ╩ĮŻ¼Ųõ╦∙ėąĄ─öĄō■Č╝╩ŪęįūųĘ¹┤«ą╬╩Į┤µā”Ż¼ī¦ų┬Ųõ▓╔╚Īį~ĄõĒśą“▀Mąą▓ķįāŻ¼öĄō■▓┘ū„║▄▓╗ĘĮ▒ŃĪŻ┐╝æ]ĄĮŲõ╝╝ągĘŌķ]ąįŻ¼▓╗─▄į┌īŹ“ףhŠ│ųą╩╣ė├ŲõŲĮ┼_ĪŻ
ĪĪĪĪ2.2 Google Ą─BigTable
ĪĪĪĪBigTable╩ŪGoogle ╗∙ė┌GFS (Google File System)║═Chubby ķ_░lĄ─Ęų▓╝╩Į┤µā”ŽĄĮyĪŻBigTable ╩ŪĘŪĻPŽĄą═öĄō■ÄņŻ¼╩Ūę╗éĆŽĪ╩ĶĄ─ĪóĘų▓╝╩ĮĪó│ųŠ├╗»┤µā”Ą─ČÓŠSČ╚┼┼ą“▒ĒĪŻ╦³▓╔ė├ąąµI(row key)Īó┴ąµI(column key)║═Ģrķg┤┴(timestamp)ī”▒Ē▀Mąą╦„ę²ĪŻ▒ĒųąĄ─├┐éĆųĄČ╝╩Ū╬┤ĮøĮŌßīĄ─ūų╣ØöĄĮMĪŻBigTable į┌ąąµI╔ŽĖ∙ō■ūųĄõĒśą“ī”öĄō■▀MąąŠSūoŻ¼▓óŪęę╗Åł▒ĒĄ─ąąµIę▓╩ŪŲõäØĘųąąģ^ķgŻ¼▀MąąSplit ║═žō▌dŠ∙║ŌĄ─ę└ō■ĪŻŲõįOėŗ─┐Ą─╩Ū┐╔┐┐Ąž╠Ä└ĒPB ╝ēĄ─öĄō■Ż¼▓óŪę─▄ē“▓┐╩ĄĮ╔ŽŪ¦┼_ÖCŲ„╔ŽĪŻBigTable ęčĮøīŹ¼F┴╦Ž┬├µĄ─ÄūéĆ─┐ś╦Ż║▀mė├ąįÅVĘ║Īó┐╔öUš╣ĪóĖ▀ąį─▄║═Ė▀┐╔ė├ąįĪŻBigTableęčĮøį┌ČÓéĆGoogle Ą─ą┬«aŲĘ║═ĒŚ─┐ųąĄ├ĄĮ┴╦æ¬ė├Ż¼╚ńGoogle Analytics ║═Google Earth Ą╚ĪŻ
ĪĪĪĪĖ∙ō■ī”BigTable Ą─蹊┐Ż¼┴╦ĮŌĄĮBigTable ų„ę¬╩ŪGoogle ßśī”ūį╔ĒĖ„ĘNæ¬ė├įOėŗĄ─┤µā”ŽĄĮyŻ¼▓óŪęø]ėąķ_į┤Ż¼į┌īŹ“×ųą¤oĘ©╩╣ė├ĪŻĄ½╩ŪBigTable Ą─ų„ę¬╝╝ąg║═īŹ¼FČ╝ī”═Ōķ_Ę┼Ż¼▓óŪęBigTable Ą─蹊┐┘Y┴ŽĘŪ│ŻžSĖ╗Ż¼į┌蹊┐įŲ┤µā”Ą─▀^│╠ųąŠ▀ėą║▄Ė▀Ą─ĮĶĶbęŌ┴x║═ģó┐╝ārųĄĪŻ
ĪĪĪĪ2.3ĪĪMicrosoft Ą─SQL Azure
ĪĪĪĪSQL Azure ╩Ū╬ó▄øĄ─įŲĻPŽĄą═öĄō■ÄņŻ¼╩Ū╗∙ė┌SQL Server ╝╝ągśŗĮ©Ą─Ż¼ų„ę¬×ķė├æ¶╠ß╣®öĄō■æ¬ė├Ę■äšĪŻSQL ║å╗»┴╦öĄō■ÄņĄ─▓┐╩Ż¼ė├涤oąĶ░▓čb║═┼õų├öĄō■ÄņŻ¼ę▓▓╗ąĶ▀MąąŠSūo║═╣▄└ĒĪŻ▓óŪęŻ¼SQL Azure ▀Ć×ķė├æ¶╠ß╣®Ė▀┐╔ė├ąį║═╚▌Õe─▄┴”ĪŻSQL Azure ū÷×ķę╗éĆ╔╠ė├öĄō■ÄņŻ¼Ųõ╠ß╣®ę╗éĆįŲČ╦Ą─DBMS(DataBase Manager System)Ż¼▀@╩╣Ą├▒ŠĄžæ¬ė├║═įŲæ¬ė├┐╔ęįį┌╬ó▄øĄ─öĄō■ųąą─Ą─Ę■äšŲ„╔Ž┤µā”öĄō■ĪŻė├æ¶╩Ū░┤ąĶĖČ┘MŻ¼Ųõųąų„ꬥ─┘Mė├╩Ū▓┘ū„┘Mė├Ż¼Č°▓╗╩Ū┤┼▒P║═DBMS ▄ø╝■═Č╚ļĄ─┘Mė├ĪŻ
ĪĪĪĪSQL Azure ū÷×ķę╗┐Ņ╔╠śI▄ø╝■Ż¼Ųõ▓╔ė├░┤ąĶĘ■äšĪó░┤ąĶ╩š┘MĄ──Ż╩ĮĪŻė╔ė┌Ųõ▓╗ķ_į┤Ż¼╦∙ęį¤oĘ©į┌īŹ“ףhŠ│ųą┤ŅĮ©Ż¼Ą½╩Ūū÷×ķįŲöĄō■Äņųą▓╔ė├ĻPŽĄą═öĄō■─Żą═Ą─Ąõą═┤·▒ĒŻ¼ę└╚╗Š▀ėąųžę¬Ą─蹊┐ęŌ┴xĪŻ
ĪĪĪĪ2.4ĪĪApache Ą─HBase
ĪĪĪĪHBaseöĄō■Äņ╩Ū╗∙ė┌Hadoop Ą─Apache ĒöīėĒŚ─┐Ż¼╦³╩ŪBigTable Ą─ķ_į┤īŹ¼FŻ¼Ą½┤µį┌║▄ČÓ▓╗═¼ų«╠ÄĪŻHBase ╩Ūę╗éĆį┌HDFS ╔Žķ_░lĄ─├µŽ“┴ąĄ─Ęų▓╝╩ĮöĄō■ÄņŻ¼ų„ę¬ų¦│ųīŹĢrĄ─ļSÖCūxīæ│¼┤¾ęÄ─ŻöĄō■╝»ĪŻHBase╩ŪūįĄūŽ“╔ŽĄž▀MąąśŗĮ©Ż¼─▄ē“║åå╬Ąž═©▀^į÷╝ė╣سcüĒ▀_ĄĮŠĆąįöUš╣ĪŻHBase ╩ŪĘŪĻPŽĄą═öĄō■ÄņŻ¼▓╗ų¦│ųSQL ▓ķįāŻ¼Ą½ŲõŠ▀éõ┴╦RDBMS ¤oĘ©▒╚öMĄ─╠žąįŻ║į┌┴«ārė▓╝■śŗ│╔Ą─╝»╚║╔Ž╣▄└Ē│¼┤¾ęÄ─ŻĄ─ŽĪ╩Ķ▒ĒĪŻHBaseŽĄĮyĮYśŗ╚ńłD1 ╦∙╩ŠĪŻ
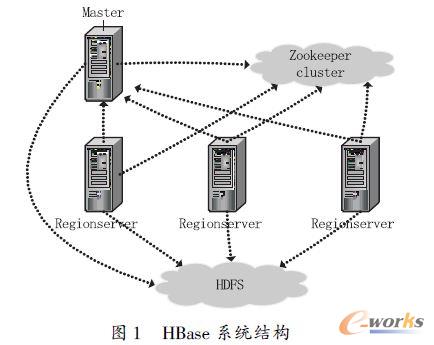
ĪĪĪĪHBase ▓╔ė├ę╗éĆMaster ╣سcģfš{╣▄└Ēę╗éĆ╗“ČÓéĆRegionServer Å─ī┘ÖC(HBase ░č▒Ē╦«ŲĮäØĘų│╔Region“ģ^ė“”)ĪŻHBase ų„┐žÖC(master)žōž¤åóäė║═ūóāįRegionServerŻ¼░čRegion Ęų┼õĮoRegionServer ▓óžōž¤RegionServerĄ─╣╩šŽ╗ųÅ═ĪŻRegionServer žōž¤Region Ą─╣▄└Ē║═Ēææ¬ė├æ¶Ą─ūxīæšłŪ¾Ż¼«öėąą┬Ą─Region «a╔·ĢrŻ¼RegionServer īó═©ų¬Master ╣سcĪŻ
ĪĪĪĪHBase ę└┘ćė┌Zookeeper(Zookeeper ╠ß╣®Ęų▓╝╩ĮµiĘ■䚯¼ŅÉ╦ŲGoogle Ą─Chubby)Ż¼╦³╣▄└Ēę╗éĆZookeeperīŹ└²Ż¼ū„×ķ╝»╚║Ą─“ÖÓ═■”(authority)Ż¼▓óžōž¤Ė∙─┐õø▒ĒĄ─╬╗ų├Īó«öŪ░╝»╚║ų„┐žÖCĄžųĘĄ╚ųžę¬ą┼ŽóĄ─╣▄└ĒŻ¼▓óžōž¤ŠSūoš¹éĆ╝»╚║Ą─╣żū„ĀŅæB║═×─ļy╗ųÅ═ĪŻ
ĪĪĪĪHBase ╩Ūķ_į┤īŹ¼FŻ¼┐╔ęįĘĮ▒ŃĄžÅ─╗ź┬ōŠW╔ŽŽ┬▌d░▓čb░³║═į┤┤·┤aŻ¼ĘŪ│Ż▀m║ŽŲ¾śIĪó┐Ųčąå╬╬╗║═īWąŻ▀Mąą╩╣ė├īW┴Ģ║═į┘ķ_░lĪŻĄ½Ųõ▓┘ū„║═╣▄└ĒĮń├µ▒╚▌^║åå╬▓╗ē“ėč║├Ż¼ąĶę¬▀Mę╗▓Į╠ßĖ▀ĪŻ
ĪĪĪĪ2.5ĪĪįŲöĄō■«aŲĘ▒╚▌^ĮY╣¹
ĪĪĪĪ═©▀^ī”ÄūĘNŠ▀ėą┤·▒ĒąįĄ─įŲöĄō■Äņ▀MąąčąŠ┐Ż¼▒╚▌^ĮY╣¹╚ń▒Ē2 ╦∙╩ŠĪŻ
ĪĪĪĪ3ĪóīŹ“×
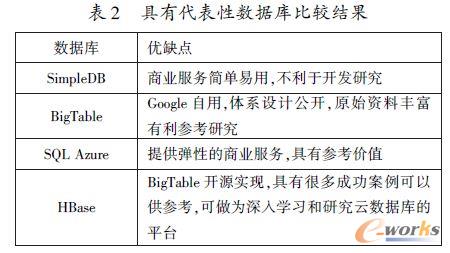
ĪĪĪĪŠC╔Ž╦∙╩÷Ż¼øQČ©▓╔ė├HBase ū÷×ķ蹊┐įŲöĄō■ÄņĄ─īŹ“×ŲĮ┼_ĪŻ
ĪĪĪĪHBase Ą─░▓čb┐╔ęįĘų×ķ╚²ĘN─Ż╩ĮŻ║å╬ÖC─Ż╩ĮĪóé╬Ęų▓╝╩Į─Ż╩Į║══Ļ╚½Ęų▓╝╩Į─Ż╩ĮĪŻ╬─ųą▓╔ė├═Ļ╚½Ęų▓╝╩Į─Ż╩ĮŻ¼▀@śė┐╔ęį─ŻöMīŹļHŠWĮjŁhŠ│Ż¼─▄ē“¾w¼FįŲöĄō■ÄņĄ─╠žąįŻ¼╩╣īŹ“×ĮY╣¹Ė³Š▀ėąšfĘ■┴”ĪŻ
ĪĪĪĪ3.1ĪĪīŹ“ףhŠ│Ą─┤ŅĮ©
ĪĪĪĪį┌īŹ“ףhŠ│ųą╣▓ėą6 ┼_Ę■äšŲ„Ż¼┤ŅĮ©═Ļ╚½Ęų▓╝╩ĮHDFS ┼cHBase ŁhŠ│Ż¼▓╔ė├hadoop0.20.0 ┼cHBase0.92.0 ░µ▒ŠŻ¼ŲõųąČ■┼_╣سcū÷×ķNamenode ║═Master ╣سcŻ¼┴Ē═Ō╦─┼_ū÷Datanode ║═RegionServerŻ¼▓óŪęį┌Ųõ╔Ž▀\ąąZookeeper Ę■äšĪŻš¹éĆīŹ“ףhŠ│╚ńłD2 ╦∙╩ŠĪŻ
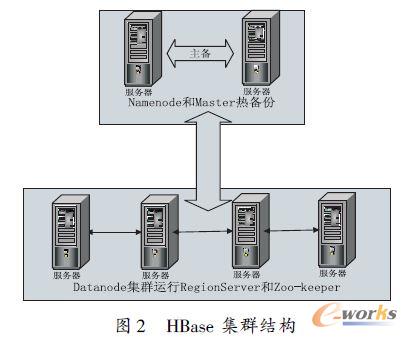
ĪĪĪĪį┌░▓čbHadoop ║═HBase ų«Ū░ę¬į┌ŽĄĮyųą░▓čbJDK ▓ó┼õų├║├ŁhŠ│ūā┴┐ĪŻį┌ė├æ¶─┐õøŽ┬░▓čb║├Hadoop║═HBase ų«║¾Ż¼▀M╚ļHadoop ─┐õøŽ┬▌ö╚ļ├³┴ŅŻ║
ĪĪĪĪrm / tmp/ *
ĪĪĪĪbin/ hadoop namenode – format
ĪĪĪĪbin/ start-all.sh
ĪĪĪĪüĒåóäėHDFSŻ¼┐╔ęį╩╣ė├bin/ hadoop dfsadmin – reportüĒ▓ķ┐┤HDFS Ą─┐╔ė├┘Yį┤ĪóīŹļH╩╣ė├░┘Ęų▒╚║═DatanodeĄ─▀\ąąŪķørĪŻ
ĪĪĪĪHBase ╩Ū▀\ąąį┌HDFS ų«╔ŽĄ─Ż¼╦∙ęį▒žĒÜ┤_▒ŻHDFS ╠Äė┌š²│Ż▀\ąąĀŅæBĪŻ═¼Ģrę“×ķ┤µį┌░µ▒Š╝µ╚▌ąįå¢Ņ}Ż¼į┌åóäėHBase ų«Ū░▒žĒÜūīHBase ┤_Č©╩╣ė├HadoopĄ─░µ▒ŠŻ¼ąĶę¬░čHadoop ─┐õøŽ┬Ą─hadoop-0.20.2-core.jar ╠µōQĄ¶HBase/ lib ─┐õøŽ┬Ą─hadoop-core-1.0.0.jarĪŻūŅ║¾┤_▒Ż╝»╚║ųą├┐┼_Ą─Ģrķg▒Ż│ųŽÓī”ę╗ų┬(š`▓ŅąĪė┌30 ├ļ)Ż¼▀M╚ļHBase ─┐õø▌ö╚ļ├³┴Ņbin/ start-hbase.sh åóäėHBaseĪŻė├├³┴Ņbin/ hbase shell ▀M╚ļ═ŌÜż│╠ą“Ż¼ė├├³┴Ņstatus ▓ķ┐┤HBase Ą─ĀŅæBĪŻ
ĪĪĪĪ3.2ĪĪīŹ“×įöĮŌ
ĪĪĪĪį┌═Ļ│╔īŹ“ףhŠ│Ą─┤ŅĮ©ų«║¾Ż¼×ķ┴╦ī”HBase ╣┘ĘĮ├Ķ╩÷Ą─HBase ŽĄĮyŠ▀éõĄ─╠žąį▀Mąą“×ūCŻ¼įOėŗ┴╦ę╗ą®īŹ“×ī”HBase ╝»╚║▀Mąą│§▓ĮĄ─£yįćŻ║
ĪĪĪĪ1)║Ż┴┐öĄō■Ą─┤µā”
ĪĪĪĪHBase ╠ß╣®JAVA ŠÄ│╠APIŻ¼į┌Eclipse ŁhŠ│Ž┬ŠÄīæöĄō■Äņīæ╚ļ│╠ą“Ż¼▓óŪę▀fį÷öĄō■īæ╚ļ┴┐Ż¼▓ķ┐┤╦∙ąĶĄ─ĢrķgŻ¼ī”ąį─▄▀Mąą║åå╬Ą─Ęų╬÷ĪŻ
ĪĪĪĪĖ∙ō■HBase ┤µā”Ą─╠ž³cŻ¼ę“×ķHBase ╩Ūī”Rowkey▀Mąą┼┼ą“Ą─Ż¼ļSÖCRowkey īó▒╗Ęų┼õĄĮ▓╗═¼Ą─region╔ŽŻ¼▀@śė─▄░lō]│÷Ęų▓╝╩ĮöĄō■ÄņĄ─ā׳cĪŻČ°Value ī”ė┌HBase üĒšf▓╗Ģ■▀Mąą╚╬║╬ĮŌ╬÷Ż¼ŲõöĄō■╩Ūʱūā╗»Ż¼ī”ąį─▄╩Ū▓╗æ¬įōėą╚╬║╬ė░ĒæĄ─ĪŻ═¼Ģr×ķ┴╦║åå╬ŲęŖŻ¼╦∙ėąĄ─öĄō■Č╝īóų╗▓Õ╚ļĄĮę╗éĆ▒ĒĖ±Ą─═¼ę╗éĆ┴ąųąĪŻ
ĪĪĪĪöĄō■▓Õ╚ļąį─▄£yįćĄ─įOėŗł÷Š░╩Ū▀@śėĄ─Ż║╚ĪļSÖCųĄĄ─Rowkey ķLČ╚×ķ2000 ūų╣ØŻ¼ųĄĄ─Value ķLČ╚×ķ4000 ūų╣ØŻ¼├┐┤╬▓Õ╚ļ10000 ŚlöĄō■Ż¼ų▒ĄĮ1000 ╚fŚlĮY╩°ĪŻīŹ“×Į©┴óĄ─▒Ē├¹×ķTestDataŻ¼īŹ“×ķ_╩╝║¾┐╔ęįÅ─
ĪĪĪĪhttpŻ║//masterŻ║60010 ▓ķ┐┤▀Mš╣ĪŻ
ĪĪĪĪĮY╣¹▒Ē├„Å─öĄō■äéķ_╩╝īæ╚ļĢrŻ¼ų╗┤µį┌1 éĆRegionŻ¼ļSų°öĄō■▀_ĄĮę╗Č©Ą─ęÄ─Żų«║¾TestData ķ_╩╝Ęų┴čŻ¼▓óīŹ¼Fžō▌dŠ∙║ŌŻ¼░čRegion ŲĮŠ∙┤µĘ┼į┌DatanodeųąĪŻ
ĪĪĪĪHBase ▓╗āHų¦│ųūįäėĄ─žō▌dŠ∙║Ō║═Ė▒▒Š╚▌×─ÖCųŲŻ¼▓óŪęūxīæąį─▄ę▓║▄ā׹ѯ¼═©▀^ī”╔Ž╩÷īŹ“×öĄō■īæ╚ļĢrķgĄ─ĮyėŗŻ¼öĄō■īæ╚ļ╦┘Č╚▀_ĄĮ0.47ms/ Śl(2127 Śl/├ļ)Ż¼▓óŪęį┌└Ēšō╔Ž▀Ćėą║▄┤¾Ą─╠ßĖ▀┐╔─▄Ż¼ę“×ķīŹ“×ė├Ą─öĄō■Äņīæ╚ļ│╠ą“×ķå╬ŠĆ│╠Ż¼ø]ėą▓╔ė├MapReduce ▓󹹊Ä│╠─Żą═ĪŻ╚ń╣¹▓╔ė├MapReduce ─Żą═Ż¼īæ╚ļ╦┘Č╚īóĢ■ėą║▄┤¾│╠Č╚Ą─╠ßĖ▀ĪŻ▀@īóį┌ęį║¾Ą─蹊┐╣żū„ųąĄ├ĄĮīŹ“ד×ūCĪŻ
ĪĪĪĪ2)öĄō■ÄņĄ─äėæBöUš╣ĪŻ
ĪĪĪĪŽÓī”é„ĮyĄ─öĄō■ÄņŻ¼įŲöĄō■ÄņŠ▀ėąĮ³║§¤oŽ▐Ą─┐╔öUš╣ąįŻ¼┐╔ęįØMūŃ▓╗öÓį÷╝ėĄ─öĄō■┤µā”ąĶŪ¾ĪŻį┌├µī”▓╗öÓūā╗»Ą─Śl╝■ĢrŻ¼įŲöĄō■Äņ┐╔ęį▒Ē¼F│÷║▄║├Ą─ÅŚąįĪŻ×ķūC├„įŲöĄō■ÄņŠ▀ėąĄ─▀@éĆā×ä▌įOėŗ┴╦╚ńłD3 ╦∙╩ŠĄ─īŹ“×ĪŻ
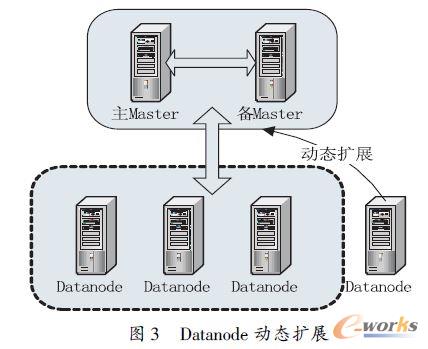
ĪĪĪĪ╩ūŽ╚ė├5 ┼_Ę■äšŲ„Į©┴óę╗éĆįŲöĄō■ÄņŲĮ┼_Ż¼Ųõųą2┼_Namenode ║═MasterŻ¼┴Ē═Ō3 ┼_×ķDatanode ║═RegionServerĪŻåóäėHDFS ║═HBaseŻ¼┤²ŽĄĮyš²│Ż▀\ąąų«║¾▓ķ┐┤HDFS ║═HBase ĀŅæB┐╔ęįĄ├ĄĮŽĄĮyųąš²│ŻĄ─Datanode ║═RegionServer Č╝╩Ū3 éĆĪŻ╚╗║¾Ż¼į┌Namenode╔ŽūóāįŽļę¬╝ė╚ļĄ─╣سcIP ĄžųĘŻ¼ė┌Hadoop Ą─conf─┐õøŽ┬Ą─slaves ╬─╝■║═HBase Ą─conf ─┐õøŽ┬Ą─regionservers╬─╝■ųą╠Ē╝ėą┬į÷╣سc├Ķ╩÷Ż¼▓ó░č┼õų├╬─╝■Å═ųŲĄĮš¹éĆ╝»╚║Ą─├┐┼_Ę■äšŲ„╔ŽĪŻė├start-all.sh ├³┴Ņī”š¹éĆHDFS ŽĄĮy▀MąąåóäėŻ¼▀@ĢrŽĄĮyĢ■ī”ūóāįSlave Ą─╣سc▀MąąÖz£yĪŻ╚ń╣¹ęčĮøÆņ▌d─Ū├┤ät╠°▀^Ż¼Ę±ätīóį┌įō╣سc╔ŽåóäėHDFS ▓óÆņ▌dĄĮŽĄĮyųąüĒĪŻį┘▀\ąąstarthbase.sh ░čą┬╠Ē╝ėĄ─RegionServer Æņ▌dĄĮ╝»╚║ųąĪŻūŅ║¾Ż¼┐╔ęį┐┤ĄĮš¹éĆHDFS ║═HBase Ą─┐╔ė├╣سcČ╝äėæBĄžį÷╝ė┴╦ĪŻ▀@ĘNäėæBöUš╣ąį─▄─▄ē“ØMūŃäėæBĄ─ąĶŪ¾▓óį┌╣Ø─▄ĘĮ├µŠ▀ėą║▄┤¾Ą─ā×ä▌ĪŻ
ĪĪĪĪ3)öĄō■Äņ╝»╚║Ą─┐╣ܦąįĪŻ
ĪĪĪĪįŲöĄō■ÄņĄ─┐╣ܦąį╩ŪŲõųąę╗éĆ║▄ųžę¬Ą─ąį─▄ųĖś╦Ż¼ų„ę¬¾w¼Fį┌öĄō■╣سcĄ─╚▌Õeąį║═Master ╣سcĄ─äėæBéõĘ▌╚▌ÕeĪŻßśī”▀@ā╔³cįOėŗīŹ¼F┴╦╚ńłD4 ╦∙╩ŠĄ─īŹ“×ĪŻ
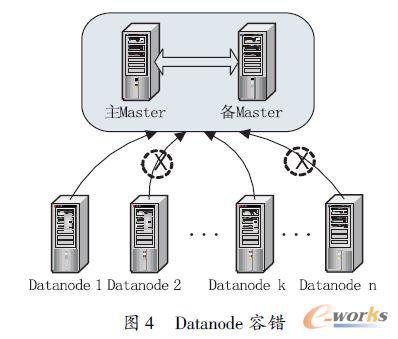
ĪĪĪĪöĄō■╣سcĄ─╚▌ÕeąįīŹ“ׯ║į┌┤ŅĮ©║├öĄō■Äņ╝»╚║ųąäōĮ©▒Ē▓óīæ╚ļę╗Č©┴┐Ą─öĄō■Ż¼╩ųäė▀Mąąžō▌dŠ∙║ŌūīöĄō■ŲĮŠ∙┤µĘ┼į┌├┐éĆ╣سcųąĪŻ╚╗║¾Ż¼į┘į┌öĄō■╣سc╝»╚║ųąkill ę╗Č©öĄ┴┐Ą─╣سcŻ¼▓óÖz£yöĄō■╩Ūʱ┐╔ė├ĪŻĮY╣¹╩ŪŻ║«ödown Ą¶Ą─öĄō■╣سcąĪė┌╝»╚║┼õų├dfs.replicationĄ─öĄō■Ė▒▒ŠöĄĢrŻ¼įō╝»╚║Ą─öĄō■╩╝ĮK▒Ż│ų┐╔ė├ĪŻ
ĪĪĪĪMaster╣سcĄ─äėæBŪąōQŻ║Master ╣سc╩Ū╣▄└ĒöĄō■Ą─į¬öĄō■▒ĒŻ¼▒ĒĄ─▓ķįāČ╝ę¬Įø▀^į¬öĄō■▒ĒĄ─╦„ę²Ż¼╦∙ęįMaster ╣سcŠ▀ėą╬©ę╗ąįŻ¼▓óŪęMaster ▒žĒÜę¬Ė▀┐╔┐┐ĪŻįOėŗ╚ńłD5 ╦∙╩ŠĄ─īŹ“×ĪŻ
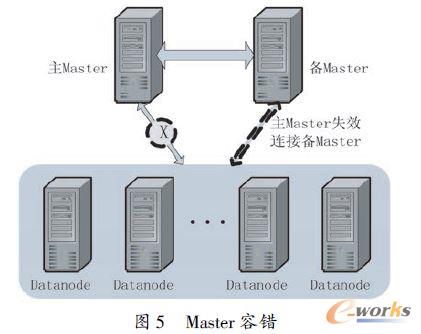
ĪĪĪĪā╔éĆ╣سc═¼Ģr▀\ąąHMaster Ę■䚯¼Ųõųąę╗éĆ×ķų„MasterŻ¼┴Ēę╗éĆ×ķéõĘ▌Master ▓ó┼cų„Master ▒Ż│ų═¼▓ĮĪŻį┌öĄō■Äņ╝»╚║š²│Ż▀\ąąĄ─ŪķørŽ┬Ż¼į┌ų„Master ╣سcųąkill Ą¶HMaster ▀M│╠Ż¼╝»╚║į┌Įø▀^zookeeper.session.timeout Č©┴xĄ─Ģrķgų«║¾Ż¼Öz£yĄĮų„Master ╣سc▓╗┐╔ė├Ż¼▀@Ģr╝»╚║īó▀MąąMaster ╣سcĄ─ŪąōQŻ¼▓óŪęų«Ū░öĄō■ÄņĄ─öĄō■▓╗Ģ■üG╩¦Ż¼š¹éĆ╝»╚║ę└╚╗┐╔ė├ĪŻ╦∙ęįŻ¼éõMaster į┌ų„Master │÷«É│Ż▓╗┐╔ė├║¾īóĮė╠µŲõ╣▄└ĒHBase öĄō■ÄņĄ─╣”─▄ĪŻ
ĪĪĪĪ4ĪóīŹ“×ĮY╣¹
ĪĪĪĪ═©▀^īŹ“×┐╔ęį┐┤│÷HBase į┌┐╔öUš╣ąįĪó║Ż┴┐öĄō■┤µā”ĪóĖ▀┐╔ė├ąįęį╝░╣▄└Ē║═▀\ąąŠSūoĘĮ├µŠ▀ėą║▄┤¾Ą─Ė─▀M║═╠ßĖ▀ĪŻ
ĪĪĪĪį┌äėæB┐╔öUš╣ąįĘĮ├µŻ║īŹ“×▒Ē├„HBase į┌╠Ē╝ė┤µā”╣سcī”öĄō■Äņ▀MąąöU╚▌Ą─▀^│╠ųąŻ¼öĄō■Äņø]ėą═Żų╣Ę■䚯¼▓óŪęę▓▓╗ę¬Ū¾╬’└ĒÖCŠ▀ėąŽÓ═¼Ą─╝▄śŗĪŻšf├„HBase Ą─öUš╣╩Ūį┌ŠĆĪóäėæBŠ▀ėąÅŚąįĄ─ĪŻÅ─Č°╩╣Ą├HBase ┐╔ė├ė┌╠ß╣®ÅŚąįĘ■䚯¼į┌Ę■äšĘÕųĄäėæB╝ė╚ļ┤¾┴┐╣سcė├ęįØMūŃĘ■äššłŪ¾Ż¼╠ßĖ▀Ę■äš┘|┴┐ĪŻČ°į┌Ą═╣╚ĢrŲ┌ätĻPķ]┤¾┴┐╣سcŻ¼▀@śė┐╔£p╔┘─▄┴┐Ž¹║─ĮĄĄ═│╔▒ŠĪŻ║Ż┴┐öĄō■Ą─ūxīæąį─▄ĘĮ├µŻ║ė╔ė┌HBase ╩Ū╗∙ė┌HDFS ų«╔ŽĮ©┴óĄ─Ż¼╦∙ęįę▓└^│ą┴╦ŲõMap/ Reduce Ą─ėŗ╦Ń─Żą═Ż¼▀@╩╣ŲõŠ▀ėąā׹ѥ─ūxīæąį─▄ĪŻ╠įīÜŠW═©▀^ā×╗»HBase ╩╣Ą├į┌öĄā|Śl╔╠ŲĘöĄō■ųą▓ķįāųĖČ©╔╠ŲĘĄ─Ģrķg┐╔ęį▀_ĄĮ║┴├ļ╝ēĪŻ
ĪĪĪĪĖ▀┐╔ė├ąįĘĮ├µŻ║é„ĮyöĄō■ÄņįOėŗĢr╩Ū┐╝æ]╚ń║╬▒▄├Ō╣╩šŽĄ─░l╔·Ż¼Č°HBase ät╩Ūęį┤¾Ą─╝»╚║×ķ│÷░l³cŻ¼░č╣╩šŽū÷×ķę╗éĆ│ŻæBüĒ▀Mąąī”┤²ĪŻHBase ▓╔ė├ČÓMaster╣سc═¼Ģr▀\ąąĄ─▓▀┬įŻ║Ųõųąę╗éĆMaster ×ķų„Master ╠ß╣®Ę■䚯¼Č°Ųõ╦³Ą─Master ╣سcät▒Ż│ų┼cų„Master Ą─═¼▓ĮŻ¼«öų„Master │÷Õeų«║¾ė╔Zookeeper ▀x┼e«a╔·ą┬Ą─ų„Master └^└m╠ß╣®Ę■äšĪŻī”RegionServer Č°čįų╗ę¬▓╗═¼Ģrėą┤¾ė┌Ė▒▒ŠöĄ─┐Ą─╣سc╩¦ą¦ät┐╔▒ŻūCöĄō■ę╗Č©┐╔ė├ĪŻ
ĪĪĪĪ┴Ē═ŌŻ¼į┌Ą═│╔▒Š║═ęūė├ąįĘĮ├µHBase ī”é„ĮyöĄō■Äņę▓ėą║▄┤¾Ą─ā×ä▌ĪŻė▓╝■ĘĮ├µHBase ų╗ę¬Ū¾╩╣ė├Ųš═©Ą─╔╠ė├Ę■äšŲ„╝┤┐╔Ż¼▄ø╝■ät╩Ūķ_į┤Ż¼╣Ø╝s┴╦┤¾┴┐│╔▒ŠĪŻ▓óŪęŻ¼HBase Ų┴▒╬┴╦╬’└ĒīėŻ¼ī”ė┌┐═æ¶Č╦Č°čįŠ═Ž±╩╣ė├ę╗éĆ░▓čbį┌▒ŠĄžĄ─öĄō■ÄņŻ¼▓┘ū„║åå╬Ż¼ŠSūoĘĮ▒ŃĪŻ
ĪĪĪĪ5ĪóĮY╩°šZ
ĪĪĪĪ╬─ųą╠ß│÷┴╦┐╔ęį╩╣ė├įŲöĄō■ÄņüĒĮŌøQ«öŪ░é„ĮyöĄō■Äņ├µ┼RĄ─ųTČÓå¢Ņ}Ż¼▓óė├HBase ū÷┴╦“×ūCąįĄ─īŹ“×ĪŻ═©▀^īŹ“×░l¼FįŲöĄō■Äņ│²┴╦┐╔ęį╠ß╣®é„ĮyöĄō■Äņę╗śėĄ─öĄō■┤µā”Ę■äšęį═ŌŻ¼▀ĆĮŌøQ┴╦─┐Ū░é„ĮyöĄō■Äņ├µ┼RĄ─å¢Ņ}Ż¼╠žäe╩Ūį┌┐╔öUš╣ąįĘĮ├µŠ▀ėą¤o┼céÉ▒╚Ą─ā×ä▌ĪŻįŲöĄō■Äņ╩Ū╬┤üĒöĄō■Äņ░lš╣Ą─ų„┴„ĘĮŽ“Ż¼┐╔ęįū÷×ķŲ¾śIå╬╬╗Īó┐Ųčąį║╦∙║═īWąŻöĄō■ÄņĄ─╩ū▀x«aŲĘĪŻ
ĪĪĪĪŽ┬ę╗▓ĮīŹ“×║═蹊┐╣żū„ų„ę¬╝»ųąį┌įŲöĄō■Äņąį─▄Ą─įö╝Ü£yįć║═Ęų╬÷Ż¼▓óĖ∙ō■īŹļHĄ─æ¬ė├ł÷Š░▀Mąąąį─▄Ą─ā×╗»ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲöĄō■Äņæ¬ė├蹊┐
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839713204.html