ÜWĻ¢│ĮŻ¼│¼▀^15─ĻĄ─▄ø╝■ķ_░l║═įOėŗĮø“ׯ¼─┐Ū░Š═┬Üė┌ąĪ├ū╣½╦ŠŻ¼žōž¤ąĪ├ūÅVĖµŲĮ┼_Ą─╝▄śŗčą░lĪŻ

į°×ķ╬ó▄ø╣½╦Š╣żū„10─ĻŻ¼ō·╚╬Ė▀╝ē▄ø╝■ķ_░lų„╣▄Ż¼ŅIī¦łFĻĀģó┼c╬ó▄ø╦č╦„╦„ę²║═╦č╦„ÅVĖµŲĮ┼_Ą─čą░l╣żū„ĪŻį°į┌╝ū╣Ū╬─╣½╦ŠÅ─╩┬öĄō■Äņ║═æ¬ė├Ę■äšŲ„Ą─čą░l╣żū„ĪŻ¤ßÉ█╝▄śŗįOėŗ║═Ė▀┐╔ė├ąįŽĄĮyŻ¼╠žäeī”ė┌┤¾ęÄ─Ż╗ź┬ōŠW▄ø╝■Ą─ķ_░lŻ¼Š▀ėąžSĖ╗Ą─└Ēšōų¬ūR║═īŹ█`Įø“×ĪŻ
┤¾╝ę║├Ż¼║▄Ė▀┼d─▄Ė·┤¾╝ęĘųŽĒę╗ą®ĻPė┌īŹĢröĄō■Ęų╬÷Ą─įÆŅ}ĪŻ
äé«ģśIĢr╬ęėąąę╚ź┴╦Oracle╣½╦Šū÷Ų¾śI▄ø╝■öĄō■ÄņŻ¼│╔×ķOracleųąć°Ą┌ę╗┼·čą░låT╣żĪŻ║¾üĒū÷┴╦Äū─ĻŻ¼ėXĄ├▀Ć╩ŪŽļū÷╗ź┬ōŠW▄ø╝■Ż¼Š═╚ź┴╦╬ó▄øŻ¼╣żū„┴╦╩«─Ļū¾ėęĪŻį┌─Ūū÷ā╔éĆĒŚ─┐Ż¼ę╗éĆ╩Ū╦č╦„Ż¼ę╗éĆ╩ŪÅVĖµŲĮ┼_ĪŻ╚ź─Ļę╗į┬Ę▌╝ė╚ļąĪ├ū╣½╦ŠŻ¼¼Fį┌ų„꬞ōž¤┤ŅĮ©ÅVĖµŲĮ┼_║═┤¾öĄō■ŲĮ┼_ĪŻ
╦∙ęįĮ±╠ņ╬ęĢ■ĮY║Ž╬ęį┌ąĪ├ūĪó╬ó▄øĄ─ę╗ą®┤¾öĄō■īŹ█`Ż¼Įo┤¾╝ęšäšä╬ęī”┤¾öĄō■Ą─└ĒĮŌŻ¼▓óĮķĮBę╗ą®║├ė├Ą─╣żŠ▀ĪŻ
▒Š┤╬č▌ųvĄ─ā╚╚▌┤¾ų┬Ęų×ķęįŽ┬▓┐ĘųŻ║
┤¾öĄō■║═ārųĄ
┤¾öĄō■Ęų╬÷╣żŠ▀ĘųŅÉ
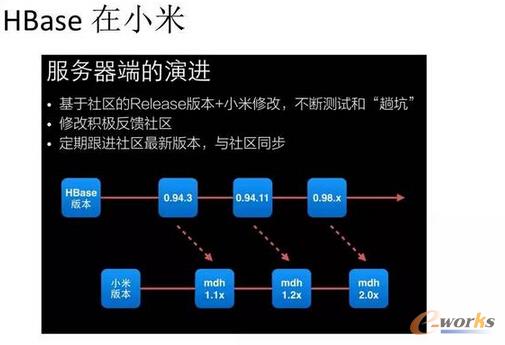
HBaseĄ─æ¬ė├║═Ė─▀M
DruidĄ─īŹĢrĘų╬÷īŹ█`
Ųõ╦³╣żŠ▀Ą─╠Į╦„
ę╗Īó┤¾öĄō■║═ārųĄ
╩▓├┤╩Ū┤¾öĄō■Ż┐▒Ŗšf╝Ŗ╝ŗĪŻ┤¾╝ę╦Ų║§ėXĄ├Š▀éõ┐ņĪóČÓĪóūā╗»┤¾ĪóĘNŅÉČÓ╦─éĆ╠žš„Ą─öĄō■Š═╩Ū┤¾öĄō■Ż¼╬ęéĆ╚╦Ė³įĖęŌÅ─┴Ēę╗éĆĮŪČ╚üĒČ©┴xŻ║ų╗ėą«ö─ŃōĒėą╚½┴┐Ą─öĄō■Ż¼▓ó═©▀^ĘŪ│ŻČÓĄ─öĄō■░čå¢Ņ}ĮŌøQĄ├▒╚▌^═Ļ├└ĢrŻ¼▀@Ģr║“Ą─å¢Ņ}▓┼╩ŪĮąū÷┤¾öĄō■å¢Ņ}ĪŻ
Įo┤¾╝ę┼eéĆ└²ūėŻ║▒╚╚ńšfėŗ╦Ńųąć°Ą─╚╦┐┌Ż¼╬ęéā┐╔ęį═©▀^├┐╩ĪĪó├┐╩ąĪó├┐ģ^Ą─│ķśėĪó▓╔śėĄ╚ĘĮĘ©üĒ½@╚ĪĘŪ│ŻĮėĮ³šµīŹĄ─öĄō■Ż¼║▄┐ņŠ═─▄═Ļ│╔▀@éĆ╚╬äšĪŻĄ½╩Ū▀@éĆ═©▀^▓╔śėĮŌøQ╚╦┐┌Įyėŗå¢Ņ}Ą─ł÷Š░╩ŪʱŠ═╩Ū┤¾öĄō■å¢Ņ}─žŻ┐į┘Įo┤¾╝ę┼eę╗éĆ╬ęūį╝║į┌ū÷Ą─┤¾öĄō■å¢Ņ}——ÅVĖµŽĄĮyĄ─═Ų╦]ĪŻė╔ė┌├┐éĆ╚╦┐┤Ą─ÅVĖµā╚╚▌ĪóŅÉą═Č╝╩Ū▓╗ę╗śėĄ─Ż¼─ŃąĶę¬ī”├┐éĆ╚╦╚źū÷╦ŃĘ©Ż¼═©▀^öĄō■Ęų╬÷═┌Š“├┐éĆ╚╦Ą─öĄō■Øō┴”ĪŻ╝┘įO¼Fį┌─ŃŽļ═©▀^ę╗ą®╦ŃĘ©šęĄĮę╗ą®ė├涎▓ÜgĄ─ÅVĖµ╗“š▀ā╚╚▌Ż¼Č°▀@Ģr─Ń꬚ęĄĮĄ─ā╚╚▌╔┘┴╦ę╗░ļŻ¼─ŃŠ═ø]Ę©═Ų╦Ń│÷ę╗░ļė├æ¶Ą─öĄō■Ż¼▀@Ģr║“─ŃĄ─ą¦╣¹ę▓▓Ņ┴╦ę╗░ļĪŻę▓Š═╩Ūšf─ŃĄ─öĄō■┴┐įĮČÓŻ¼Ė▓╔wįĮČÓė├æ¶Ż¼ą¦╣¹įĮ║├ĢrŻ¼▀@Ģr║“╬ęéā┐╔ęįšJ×ķ╦³╩Ūę╗éĆšµš²Ą─┤¾öĄō■å¢Ņ}ĪŻ

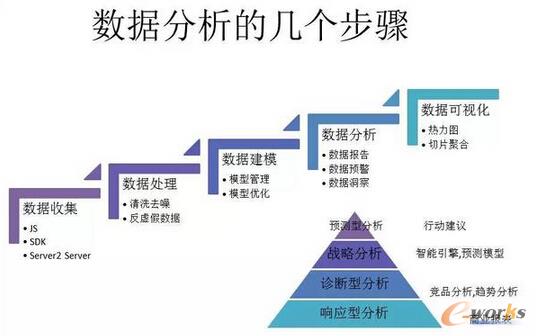
łD1 ┤¾öĄō■Ą─╣╩╩┬Ż║ārųĄ×ķ├└
┤¾öĄō■═Ō▒Ē╣Ō§r┴┴¹ÉŻ¼Š═Ž±╝tśŪē¶└’Ą─┤¾ė^ł@Ż¼Ą½└’├µŲõīŹ╩Ū║▄¤o─╬Ą─ĪŻū÷┤¾öĄō■╝╝ągĄ─═¼īWČ╝ų¬Ą└Ż¼▀@└’├µ╔µ╝░ĄĮöĄō■Ą─ŪÕŽ┤Īóš¹└ĒĪó┤µā”Ą╚║▄ČÓ║▄ČÓ┐▌į’Ą─╩┬ŪķĪŻ┤╦═ŌŻ¼┤¾öĄō■▀Ćėąę╗éĆ╠ž³cŻ¼Š═╩Ū«ö─Ńėą┴╦┤¾öĄō■Ż¼▀ĆĄ├Žļ╚ń║╬╚źūā¼FĪŻį┌╬ę┐┤üĒŻ¼┤¾öĄō■īŹļH╔Ž║▄ļyšęĄĮę╗éĆų▒ĮėĄ─═ŠÅĮüĒūā¼FŻ¼╦³Ą─┤_┐╔ęį╚ź═ŲäėśI䚥─ųŪ─▄╗»Ż¼ū÷ā╚╚▌═Ų╦]ūīė├æ¶Ą─¾w“×Ė³║├Ż¼Ą½▀@ą®Č╝╩Ūę╗ą®ķgĮėĄ─ūā¼Fł÷Š░Ż¼šµš²┤¾öĄō■─▄ē“ūā¼FĄ─ł÷Š░Ż¼╬ęūį╝║┐éĮY┴╦ę╗Ž┬Ż¼┤¾Ė┼ėąā╔éĆĘĮŽ“Ż║ę╗éĆ╩ŪÅVĖµŻ¼Č■╩ŪŃyąąĄ─š„ą┼ŽĄĮyŻ¼│²┴╦▀@ā╔éĆŅIė“ų«═ŌŻ¼║▄╔┘ėą╣½╦ŠįĖęŌ×ķöĄō■┘Iå╬ĪŻ
Ž┬├µ║åå╬ĮķĮBąĪ├ūĄ─┤¾öĄō■╝╝ąg┐“╝▄ĪŻ
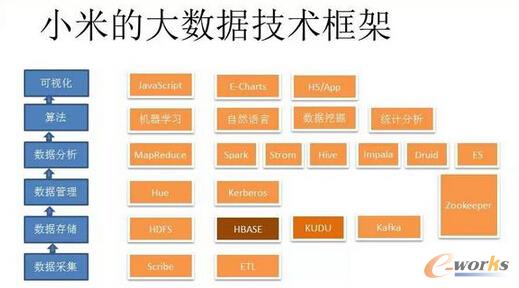
łD2 ąĪ├ūĄ─┤¾öĄō■╝╝ąg┐“╝▄
║═║▄ČÓ╣½╦ŠŅÉ╦ŲŻ¼ąĪ├ūĄ─┤¾öĄō■┐“╝▄ę▓░³└©öĄō■▓╔╝»Īó┤µā”Īó╣▄└ĒĪóĘų╬÷Īó╦ŃĘ©║═┐╔ęĢ╗»ĪŻ┤¾▓┐ĘųĮM╝■Č╝╩Ūķ_į┤Ą─Ż¼┴Ē═Ō╬ęéāĢ■ī”ę╗ą®║╦ą─Ą─ĮM╝■ū÷ę╗ą®╔Ņ╝ė╣ż╗“š▀ā×╗»ĪóūįČ©┴xĪŻŲõųąŻ¼į┌öĄō■▓╔╝»▓┐ĘųŠ═╩ŪScribeŻ¼┤µā”ė├Ą├▌^ČÓĄ─▀Ć╩ŪHBaseŻ¼║¾├µ╬ęĢ■ĮķĮBąĪ├ūį┌▀@ę╗ēKĄ─ā×╗»ĪŻ╣▄└Ē╔Ž╬ęéāė├┴╦Kerberos╚źū÷šJūCŻ¼į┌╔Ž├µ▀Ćėąę╗ą®SparkĪóStormĪóHiveĪóImpala║═DruidĪŻ
šfĄĮ┤¾öĄō■æ¬ė├Ż¼ĘNŅÉĘŪ│ŻČÓŻ¼╬ę║åå╬ųvę╗Ž┬ąĪ├ūį┌┤¾öĄō■╔ŽĄ─ę╗ą®æ¬ė├ĪŻ

łD3 ąĪ├ū┤¾öĄō■æ¬ė├
╩ūŽ╚╩ŪŠ½£╩ĀIõNŻ¼╬ęéā┐╔ęįī”├┐éĆė├æ¶ū÷ę╗ą®«ŗŽ±ĪŻė├į┌╦č╦„║══Ų╦]╔ŽŻ¼ūī╦³ūāĄ├Ė³╝ėŠ½£╩Ż╗▀Ćėą╗ź┬ōŠWĮ╚┌Ż¼ėąę╗ą®š„ą┼¾wŽĄ┐╔ęįė├ĄĮŻ╗Š½╝Ü╗»▀\ĀIŻ╗▀ĆėąĘ└³S┼ŻŻ¼ę“×ķąĪ├ū╩ųÖCĄ─ąįār▒╚▌^Ė▀Ż¼║▄ČÓĢr║“ą┬ŲĘ│÷üĒĢr³S┼ŻéāĢ■╚źōīŻ¼┴Ēę╗ĘĮ├µŻ¼¼Fį┌Ą─³S┼Ż╩ųČ╬įĮüĒįĮĖ▀├„┴╦Ż¼╦¹éāĢ■─ŻöM║▄ČÓIPĪóą┬Ą─┘~╠¢╗“š▀└ŽĄ─┘~╠¢Ą╚ę╗ą®Å═ļsĄ─┘Å┘Iąą×ķŻ¼╦∙ęįŠ═║▄ąĶę¬▓╔╚Īę╗ą®╩ųČ╬╚źĘ└³S┼ŻĪŻ▀ĆėąłDŲ¼ĪółDŽ±Ą─Ęų╬÷║═╠Ä└ĒŻ¼Ž±ąĪ├ū╩ųÖCą┬═Ų│÷Ą─īÜīÜŽÓāįĄ╚ĪŻ
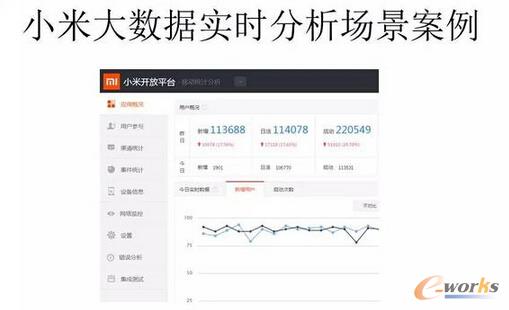
łD4 ąĪ├ū┤¾öĄō■īŹĢrĘų╬÷ł÷Š░░Ė└²
äéäéšfĄ─╩Ūę╗ą®śI䚥─ł÷Š░Ż¼▀Ćėąę╗ą®Įoķ_░lš▀ė├Ą─ł÷Š░ĪŻ
▒╚╚ńšfąĪ├ū═Ų│÷Ą─ę╗éĆöĄō■ĮyėŗĘų╬÷ŲĮ┼_Ż¼╦³╠ß╣®ę╗ą®APIūī─ŃŪČ▀M╚źŻ¼┐╔ęįė├öĄō■Ęų╬÷─ŃĄ─æ¬ė├╩╣ė├ŪķørĪŻ╚╗║¾ĮY║ŽąĪ├ūĄ─ė├涫ŗŽ±Ż¼×ķķ_░lš▀╠ß╣®Ė³║├Ą─öĄō■Ęų╬÷Ę■äšĪŻ
─┐Ū░ąĪ├ū╚š╗Ņ│¼▀^Ū¦╚fĄ─APP┤¾Ė┼ėąČ■╩«Äū╝ęŻ¼░³└©×gė[Ų„Īóæ¬ė├╔╠ĄĻĪóęĢŅlĄ╚Ż¼▀@ą®æ¬ė├īŹĢrĘų╬÷Ą─ąĶŪ¾ĘŪ│Ż═·╩óŻ¼╦¹éāČ╝╩Ūė├▀@ę╗╠ūŽĄĮy╚źū÷öĄō■┤“³cĪóAB£yįćĪó«ŗŽ±ĪóĘųĮMĄ╚Ż¼╦∙ęįį┌║¾├µ╬ęéāąĶę¬ę╗éĆ═╠═┬┴┐┤¾Ą─īŹĢröĄō■Ęų╬÷╠Ä└ĒŽĄĮyüĒ│ąō·▀@▓┐Ęųėŗ╦ŃĄ─╚╬äšĪŻ
łD5 öĄō■Ęų╬÷Ą─ÄūéĆ▓Į¾E
šfĄĮöĄō■Ęų╬÷Ą─▓Į¾EŻ¼ūŅķ_╩╝╩ŪöĄō■╩š╝»Ż¼╚╗║¾╠Ä└ĒŻ¼ŪÕŽ┤Ż¼Į©─ŻŻ¼Ęų╬÷Ż¼ūŅ║¾┐╔ęĢ╗»ĪŻ▀@╩Ū┤¾Ė┼Ą─╗∙▒Š▓Į¾EĪŻ
Å─öĄō■Ęų╬÷Ą─ŅÉą═üĒ┐┤Ż¼ę▓┐╔ęįĘų×ķ╦─éĆīė┤╬Ż║ūŅŽ┬├µ╩Ūę╗éĆ▒╚▌^╗∙ĄAĄ─īė┤╬Ż¼ĮąĒææ¬ą═Ęų╬÷Ż¼╗∙▒Š╔Ž╩Ū░┤šš╔╠śIąĶŪ¾│÷╔╠śIł¾▒ĒĪŻĄ┌Č■éĆīė┤╬Įąį\öÓą═Ęų╬÷Ż¼Š═╩Ūšf«ö─Ńėą┴╦║▄ČÓöĄō■ęį║¾Ż¼Å─öĄō■└’├µ═┌Š“│÷ę╗ą®å¢Ņ}Ż¼╗“š▀═©▀^öĄō■╚źĮŌßī▀@ą®å¢Ņ}Ż¼Ž±ę╗ą®ĖéŲĘĘų╬÷Īó┌ģä▌Ęų╬÷ĪŻĄ┌╚²éĆīė┤╬Įąæ┬įĘų╬÷Ż¼▀@éĆīė┤╬ŽÓī”Ū░├µā╔éĆīė┤╬üĒšf▒╚▌^ļy┴╦Ż¼╝┤į┌ū÷║▄ČÓ╣½╦ŠĄ─Ęų╬÷ĢrŻ¼─ŃąĶę¬Į©éĆ─Żą═Ż¼╚╗║¾ė├öĄō■╚źĄ├│÷ę╗ą®ĮYšōŻ¼║▄ČÓū╔įā╣½╦ŠŠ═╠ß╣®▀@ĘNæ┬įĘų╬÷Ż¼Ž±¹£┐ŽÕaĪóžÉČ„Ą╚╣½╦Š║▄ČÓĢr║“Š═╩Ūį┌▀@ę╗īė┤╬ū÷╩┬ŪķĪŻūŅ║¾ę╗éĆīė┤╬ę▓ļyŻ¼ĮąŅA£yą═Ęų╬÷ĪŻ─Ń▓╗╣Ōę¬Į©║├─ŻŻ¼▀ĆꬎļĄĮĄūį§├┤ū÷Ż¼▓╔ė├╩▓├┤śėĄ─ąąäėŻ¼Įo│÷šµš²Ą─Į©ūhĪŻ
Č■Īó┤¾öĄō■Ęų╬÷╣żŠ▀
ąĪ├ūĮyėŗŲĮ┼_│ąĮėĄ─öĄō■┴┐ĘŪ│Ż┤¾Ż¼Č°Ūęī”īŹĢrĄ─ę¬Ū¾ĘŪ│ŻĖ▀Ż¼╦∙ęįį┌╣żŠ▀Ą─▀x╚Ī╔Žę▓╗©┴╦║▄ČÓĢrķgĪŻŽ┬├µĮo┤¾╝ęĮķĮBę╗Ž┬ąĪ├ūį┌┤¾öĄō■īŹĢr╠Ä└ĒĢrę╗ą®╣żŠ▀▀xą═Ą─╦╝┬ĘĪŻ
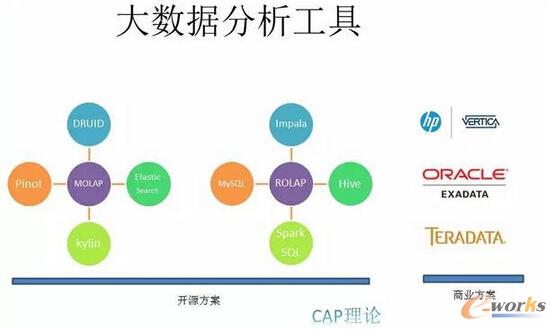
łD6 ┤¾öĄō■Ęų╬÷╣żŠ▀
īŹĢrĘų╬÷▓╗╩Ūę╗éĆą┬å¢Ņ}Ż¼Ą½╚ń╣¹╔ŽĄĮā|╚f╝ēĄ─öĄō■┴┐ĢrŻ¼▀@éĆå¢Ņ}ę▓’@Ą├ĘŪ│Żųžę¬ĪŻį┌öĄō■Ęų╬÷ė╚Ųõ╩ŪČÓŠSĘų╬÷▀@ēKŻ¼ėąÄūéĆ┴„┼╔Ż¼ę╗éĆ┴„┼╔╩Ūķ_į┤Ą─╣żŠ▀Ż¼▀Ćėąę╗éĆ┴„┼╔╩Ū╔╠śIĄ─╣żŠ▀ĪŻ╔╠śIĄ─╣żŠ▀ųąėąÄū╝ę▒╚▌^ėą├¹Ż¼ę╗éĆ╩Ū╗▌ŲšĄ─VerticaŻ¼ę╗éĆ╩ŪOracleŻ¼OracleĄ─▓╗ūŃų«╠ÄŠ═╩Ū╠½┘F┴╦Ż¼│╔▒Š▌^Ė▀Ż¼▀ĆėąŠ═╩ŪTeradataŻ¼├└ć°╝ėų▌ę╗éĆ└Ž┼ŲĄ─ČÓŠSöĄō■Ęų╬÷╣½╦ŠĪŻį┌┴Ēę╗▀ģĄ─ķ_į┤▄ø╝■Ż¼ę▓┐╔┤¾Ė┼Ęų×ķā╔éĆ┴„┼╔Ż¼ę╗éĆĮąū÷MOLAP Ż¼╦³į┌įOėŗų«│§Š═╩ŪŽļ░čöĄō■ĮYśŗūā│╔ę╗éĆČÓŠSöĄō■ÄņŻ¼▀@śė▓ķįāŲüĒ╝╚┐ņėųĘĮ▒ŃŻ╗┴Ēę╗éĆĮąROLAPŻ¼Ų¾łDė├é„ĮyĻPŽĄą═öĄō■Äņ╚źśŗĮ©ČÓŠSöĄō■ÄņŻ¼ę“×ķŽ±MySQLĪóHive▀@ĘNé„ĮyöĄō■Äņ╩ŪĘŪ│ŻĘĮ▒ŃĄ─ĪŻ┐éĄ─üĒšfŻ¼ķ_į┤Ą─┤¾Ė┼ėąā╔Śl┬ĘŻ¼ę╗ŚlŠ═╩ŪįŁ╔·Ą─ų¦│ųČÓŠSĄ─Ż¼┴Ēę╗ŚlŠ═╩Ū═©▀^ĻPŽĄą═öĄō■Äņ╚ź─ŻöM▀@ĘNČÓŠS▓ķįāĪŻįŁ╔·ČÓŠS▀@▀ģ╣żŠ▀Ą─įÆŻ¼ąĪ├ūė├Ą─▒╚▌^ČÓĄ─Š═╩ŪDruidŻ¼PinotŻ¼Kylin║═ElasticSearchĪŻ
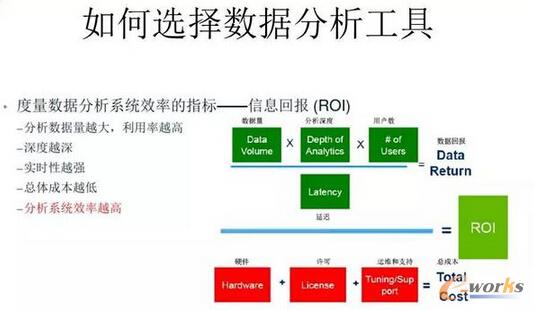
łD7 ╚ń║╬▀xō±öĄō■Ęų╬÷╣żŠ▀
į┌▀xöĄō■Ęų╬÷╣żŠ▀Ą─Ģr║“ąĶę¬┐╝æ]║▄ČÓ╩┬ŪķŻ¼Ž±ę╗ą®║▄ųžę¬Ą─öĄō■┴┐Ż¼▀ĆėąŠ═╩Ū─ŃąĶę¬Ęų╬÷▀@ą®öĄō■Ą─ŠSČ╚ėąČÓ╔┘Ż¼─ŃĄ─ė├æ¶▓ó░lČ╚Ż¼▀@ą®Č╝╩ŪīŹļH▀^│╠ųąąĶę¬┐╝æ]Ą─ųžę¬ę“╦žĪŻ╠žäe╩ŪŠSČ╚Ż¼ŠSČ╚įĮČÓŻ¼ŽĄĮyĢ■įĮÅ═ļsĪŻ
äéäéŪ░├µųvĄĮąĪ├ūĄ─Įyėŗ╣żŠ▀Ż¼▀@└’į┘Ę┼ę╗ÅłąĪ├ūĮyėŗ║¾┼_Ą─╝▄śŗłDŻ¼╬ę░č╦³╔į╬ó║å╗»┴╦ę╗Ž┬Ż║

łD8 ąĪ├ūöĄō■ĮyėŗĘų╬÷ŲĮ┼_-╝▄śŗ
╩ūŽ╚╩Ū╩ųÖCĪóļŖęĢĪóļŖ─X░č╩┬╝■═©▀^ŠWĮj┤“ķ_ąĪ├ūĘų╬÷Ę■äšŲ„Ż¼▀@ĢrĘ■äšŲ„ėąā╔Śl┬ĘŻ¼ę╗Śl┬Ę╩Ū░čLog┤µį┌ Scirbe└’├µŻ¼╚╗║¾═©▀^MapReduce║═HDFS╚źū÷ėŗ╦Ń║═┤µā”Ż¼ĮY╣¹Ģ■Ę┼ĄĮMySQLöĄō■Äņ║═HBaseųąŻ¼┴Ē═Ōę╗Śl┬Ęät╩Ū╦∙ėą╩┬╝■üĒ┴╦ęį║¾Ż¼Įø▀^Kafkaęį╝░StormĄ─ėŗ╦Ń╝»╚║░čŅAėŗ╦Ń╦Ń║├Ż¼ūŅ║¾┤µĄĮHBaseųąĪŻ╦∙ęįį┌ąĪ├ūĮyėŗŲĮ┼_╔ŽŽ±ĘųńŖ╝ēĄ─öĄō■Č╝╩ŪÅ─╔Ž├µ▀@Śl┬ĘüĒĄ─Ż¼░┤╠ņĄ─öĄō■ät╩ŪÅ─Ž┬├µ▀@Śl┬ĘüĒĄ─Ż¼╬ęéā├┐╠ņĢ■ė├═Ļš¹┼▄Ą─Log╚ź╚Ī┤·īŹĢrĄ─öĄō■Ż¼┤¾Ė┼╩Ū▀@śėę╗éĆ▀^│╠ĪŻ
╚²ĪóHBaseĄ─æ¬ė├║═Ė─▀M

łD9 ×ķ╩▓├┤ŪÓ▓AHBaseŻ┐
ąĪ├ūė├HBase▀Ć╩ŪąUČÓĄ─Ż¼HBase╩Ūę╗éĆ▒╚▌^ėą├¹Ą─┴ą╩Į┤µā”Ż¼╬ęéā╣½╦Šę▓ėą╚²éĆHBase CommitterŻ¼ī”HBaseū÷┴╦║▄ČÓĖ─▀MĪŻ▒╚╚ńī”į┤┤·┤aĄ─Ė─▀MŻ¼Ė─═Ļęį║¾╬ęéāėųĢ■░č▀@ą®Ė─▀MĘĄ╗žĄĮķ_į┤╔ńģ^ĪŻį┘╚ń├¹ūųĘ■䚯¼ęįŪ░Ą─įÆŻ¼HBaseįLå¢ę¬╠Ņ║▄ČÓServer├¹ĪóČ╦┐┌├¹Ż¼¼Fį┌ė├ę╗éĆ├¹ūųŠ═┐╔ęįįLå¢Ż¼░³└©HBase╩Ū▓╗ų¦│ųČ■╝ē╦„ę²Ą─Ż¼╬ęéā═∙└’├µį÷╝ė┴╦╦„ę²╣”─▄ĪŻ
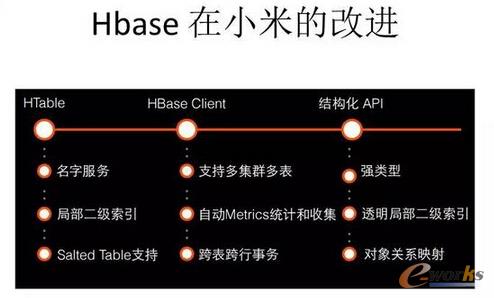
łD10 HBaseį┌ąĪ├ūĄ─Ė─▀M
łD11 HBaseį┌ąĪ├ū
łD11 HBaseį┌ąĪ├ū
į┌Ę■äšŲ„Č╦Ė─▀MĄ─▀^│╠ųąŻ¼╬ęéā░l¼Fėąą®Ė─▀M┐╔ęįĘ┤üĄĮ╔ńģ^Ż¼Ą½ėąą®Ę┤ü╗ž╚źĢrš¹éĆīÅ║╦┴„│╠╠žäe┬²Ż¼ęįų┴ė┌║¾üĒąĪ├ūā╚▓┐┬²┬²Īóų▓ĮĄžŠ═č▌ūā│╔┴╦ę╗éĆ╣┘ĘĮĄ─░µ▒ŠŻ¼ķLŲ┌üĒ┐┤Ż¼▀@ā╔éĆ░µ▒ŠĄ─╚┌║ŽųĄĄ├╔Ņ╦╝╩ņæ]ĪŻ
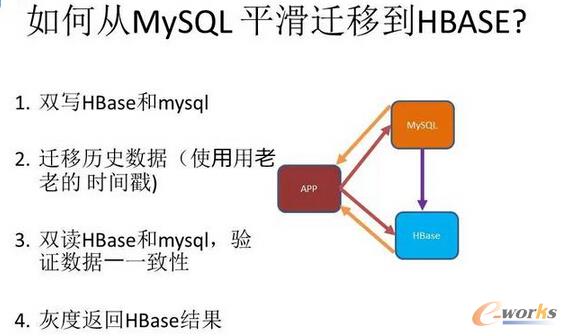
łD12 ╚ń║╬Å─MySQLŲĮ╗¼▀węŲĄĮHBASEŻ┐
ąĪ├ūį┌│§Ų┌Ģr║▄ČÓśIäš╩Ū╩╣ė├MySQLĄ─Ż¼ę“×ķŽÓī”üĒšf║åå╬┤ų▒®Ż¼Ą½╦³Ą─╚▌┴┐ėąŽ▐ĪŻśIäš╚▌┴┐öUÅłęį║¾Ż¼ąĪ├ū┤¾Ė┼ėąā╔ā|éĆė├æ¶Ż¼1.5ā|éĆį┬╗Ņė├æ¶Ż¼╚š╗Ņę▓│¼▀^ę╗ā|ČÓŻ¼MySQLę╗░ŃüĒšf╩Ūō╬▓╗ūĪĄ─Ż¼▀@éĆĢr║“║▄ČÓśI䚊═ąĶę¬▀węŲĄĮHBase╔ŽĪŻ
ę“┤╦Ż¼ūŅ║¾ąĪ├ū╠ß│÷ę╗éĆ║▄CommonĄ─HBase▀węŲĘĮĘ©Ż¼į┌ūŅķ_╩╝īæöĄō■Ą─Ģr║“ļpīæŻ¼╝╚īæHBaseėųīæMySQLĄ─Ż¼▒ŻūCą┬Ą─öĄō■Ģ■═¼Ģr┤µį┌ė┌HBase║═MySQL└’Ż¼Ą┌Č■éĆŠ═╩Ū░čMySQLųąĄ─Üv╩ĘöĄō■▀węŲĄĮHBaseŻ¼▀@śėÅ─└Ēšō╔Žā╔éĆöĄō■ÄņŠ═─▄ōĒėą═¼śėĄ─ā╚╚▌┴╦ĪŻĄ┌╚²éĆ╩ŪļpūxHBase║═MySQLŻ¼ąŻ“×öĄō■╩Ū▓╗╩ŪČ╝ę╗ų┬Ż¼ę╗░Ń▀_ĄĮ99.9%Ą─ĮY╣¹ĢrŻ¼╬ęéāŠ═šJ×ķ▀węŲ╩Ū▒╚▌^│╔╣”Ą─ĪŻūŅ║¾╗ęČ╚ĘĄ╗žĄĮHBaseĮY╣¹ĪŻ
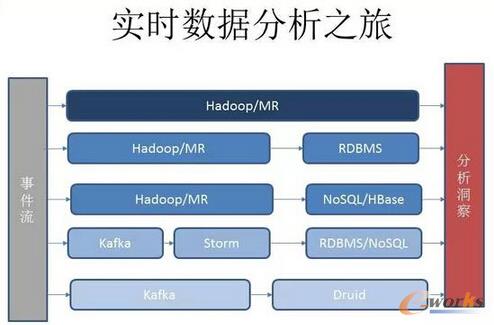
łD13 īŹĢröĄō■Ęų╬÷ų«┬├
╦─ĪóDruidĄ─īŹĢrĘų╬÷īŹ█`
ę╗ķ_╩╝ū÷ąĪ├ūĮyėŗŲĮ┼_ĢrŻ¼öĄō■ŲõīŹę▓ø]ėąū÷ĄĮīŹĢrĄ─Ż¼Č╝╩Ūū▀╔Ž├µĄ─ę╗Śl┬ĘŻ¼Ą┌Č■éĆļAČ╬═©▀^MapReduce╠Ä└Ēęį║¾Ż¼░čöĄō■Ę┼ĄĮĻPŽĄą═öĄō■└’├µŻ¼▒╚╚ńŽ±MySQL▀@śėĄ─öĄō■ÄņĪŻį┘║¾üĒŻ¼śIäš┬²┬²öUš╣Ż¼RDBMSĄ─╚▌┴┐ėąŽ▐Ż¼│÷¼F║▄ČÓå¢Ņ}Ż¼╦∙ęįĄĮĄ┌╚²éĆļAČ╬╬ęéā░čRDBMSūā│╔HBaseŻ¼▀@éĆļAČ╬ę▓│ų└m┴╦║▄Š├Ż¼į┘║¾üĒ╬ęéāŽļĄ├ĄĮīŹĢrĄ─öĄō■Ż¼üĒĄĮĄ┌╦─▓ĮŻ¼═©▀^KafkaĪóStormį┘ĄĮRDBMS╗“š▀NoSQLŻ¼ūŅ║¾ę╗▓Į╬ęéāų▒Įė╩Ū░čöĄō■Å─Kafka▐DĄĮDruidĪŻ
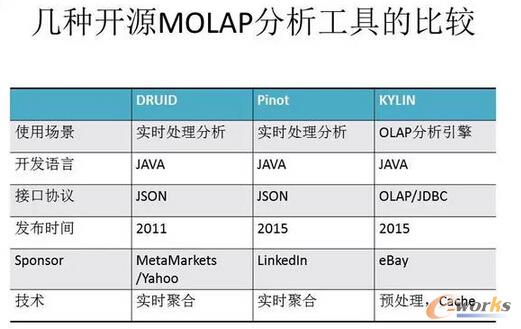
łD14 ÄūĘNķ_į┤MOLAPĘų╬÷╣żŠ▀Ą─▒╚▌^
Druidė╔ę╗╝ęĮąMetaMarketsĄ─╣½╦Šķ_░lŻ¼─┐Ū░Ž±YahooĪóąĪ├ūĪó░ó└’Īó░┘Č╚Ą╚╣½╦ŠČ╝į┌ė├╦³┤¾┴┐Ąžū÷ę╗ą®öĄō■Ą─īŹĢrĘų╬÷Ż¼░³└©ę╗ą®ÅVĖµĪó╦č╦„Īóė├æ¶Ą─ąą×ķĮyėŗĪŻ╦³Ą─╠ž³c░³└©Ż║
×ķĘų╬÷Č°įOėŗ
×ķOLAPČ°╔·Ż¼╦³ų¦│ųĖ„ĘNfilterĪóaggregator║═▓ķįāŅÉą═ĪŻ
Į╗╗ź╩Į▓ķįā
Ą═čė▀töĄō■Ż¼ā╚▓┐▓ķįā×ķ║┴├ļ╝ēĪŻ
Ė▀┐╔ė├ąį
╝»╚║įOėŗŻ¼╚źųąąį╗»ęÄ─ŻĄ─öU┤¾║═┐sąĪ▓╗Ģ■įņ│╔öĄō■üG╩¦ĪŻ
┐╔╔ņ┐s
¼FėąĄ─Druid▓┐╩├┐╠ņ╠Ä└ĒöĄ╩«ā|╩┬╝■║═TB╝ēöĄō■ĪŻDruid▒╗įOėŗ│╔PB╝ēäeĪŻ
┼cDruidŽÓŅÉ╦ŲĄ─īŹĢröĄō■Ęų╬÷╣żŠ▀Ż¼▀ĆėąLinkedlnĄ─Pinot║═eBayĄ─KylinŻ¼╦³éāČ╝╩Ū╗∙ė┌Javaķ_░lĄ─ĪŻDruidŽÓī”▒╚▌^▌p┴┐╝ēŻ¼ė├Ą─╚╦ę▓ČÓŻ¼«ģŠ╣ķ_░lĢrķgŠ├ę╗ą®Ż¼å¢Ņ}ę▓╔┘ę╗ą®ĪŻ
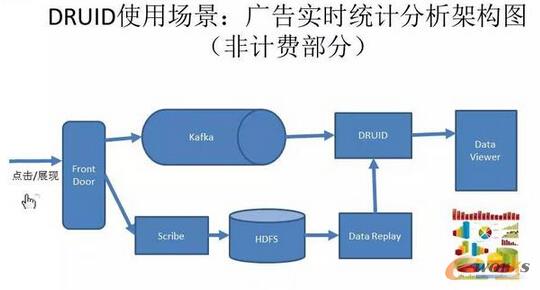
łD15 DRUID╩╣ė├ł÷Š░Ż║ÅVĖµīŹĢrĮyėŗĘų╬÷╝▄śŗłDŻ©ĘŪėŗ┘M▓┐ĘųŻ®
Druidį┌ąĪ├ūā╚▓┐│²┴╦æ¬ė├ė┌ąĪ├ūĮyėŗų«═ŌŻ¼▀Ćæ¬ė├ė┌ÅVĖµŽĄĮyĪŻąĪ├ūĄ─ÅVĖµŽĄĮyų„ę¬╩Ūī”├┐éĆÅVĖµĄ─šłŪ¾Īó³cō¶Īóš╣¼Fū÷ę╗ą®Ęų╬÷Ż¼ę╗ŚlŠĆ╩Ū═©▀^Kafka→Druid→öĄō■┐╔ęĢ╗»’@╩ŠŻ¼┴Ē═Ōę╗Śl┬ĘŠ═╩Ū═Ļš¹öĄō■┬õ▒PĄĮHDFSŻ¼├┐╠ņ═Ē╔Ž═©▀^öĄō■ųžĘ┼╚ź╝mš²Druid└’Ą─ę╗ą®öĄō■Ż¼Ė▓╔wDruidĄ─£╩┤_öĄō■Ż¼ūŅ║¾ū÷┐╔ęĢ╗»ĪŻ
╬ÕĪóŲõ╦³╣żŠ▀Ą─╠Į╦„

łD16 ╩▓├┤╩ŪPinot
PinotŻ¼Linkedlnķ_░lĄ─ŅÉ╦Ųė┌DruidĄ─ČÓŠSöĄō■Ęų╬÷ŲĮ┼_Ż¼╦³Ą─╣”─▄īŹļH╔Žę¬▒╚DruidÅŖ┤¾ę╗ą®Ż¼Ą½ę“×ķ╚ź─Ļ▓┼äéäéķ_╩╝ķ_į┤Ż¼ė├Ą─╚╦▒╚▌^╔┘ĪŻ┤¾╝ęėą┼d╚żĄ─┐╔ęį╚źįćįćĪŻ╦³Ą─š¹éĆ┤·┤a┴┐ę▓▒╚▌^┤¾Ż¼╝▄śŗ┼cDruidę▓ĘŪ│ŻŽÓ╦ŲŻ¼Ą½╦³ę²╚ļ┴╦Ė³║├Ą─ę╗ĘNģfš{╣▄└ĒŲ„Ż¼Ė³ČÓĄ─╩Ūę╗ĘNŲ¾śI╝ēäeĄ─įOėŗŻ¼Ė³╝ė═Ļš¹ĪóęÄĘČĪŻ
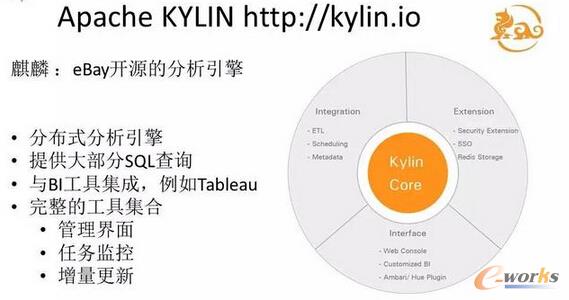
łD17 Apache KYLIN
Kylin╩ŪeBayĄ─ķ_į┤Ęų╬÷╣żŠ▀Ż¼╦³Ą─ā׳cŠ═╩Ū║▄┐ņŻ¼╠žäe▀m║Ž├┐╠ņČ©Ģrł¾▒ĒŻ¼╚▒³cę▓║▄├„’@Ż¼Š═╩ŪļSÖC▓ķįā║▄┬²ĪŻ╦³▀Ćėąę╗éĆ║├╠ÄŠ═╩Ūų¦│ųś╦£╩Ą─SQLŻ¼┼cTableauĄ╚BI╣żŠ▀╝»│╔Ż¼┐╔ęįų▒Įė▀BĄĮeBayĄ─▀@éĆKylin╣żŠ▀ĪŻČ°ŪęŻ¼Kylinį┌Fast Cubing╔Žū÷┴╦ę╗ą®ŅA╠Ä└ĒŻ¼Ę┤æ¬▌^┐ņĪŻ
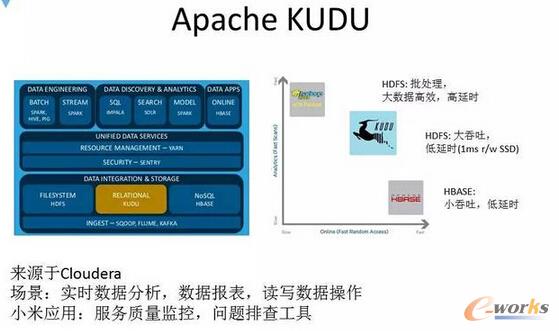
łD18 Apache KUDU
KUDU╩Ū╚ź─Ļ╩«į┬Ę▌Apacheķ_į┤Ą─ę╗éĆ╣żŠ▀Ż¼┼cąĪ├ū┬ō║Ž░l▓╝ĪŻ╦³Ą─Č©╬╗╩Ū╩▓├┤─žŻ┐┤¾╝ęČ╝ų¬Ą└Druid╩Ūę╗éĆ┼·╠Ä└ĒĪóĖ▀╚▌┴┐Ą─▓ķįāŽĄĮyŻ¼Ēææ¬Ģrķg║▄┬²Ż¼Č°HBase┐╔ęįų¦│ų┐ņ╦┘Ą─Ēææ¬ĢrķgŻ¼Ą½╦³ų„ę¬╩Ūę╗éĆīæ╔┘ūxČÓĄ─ŪķørĪŻ
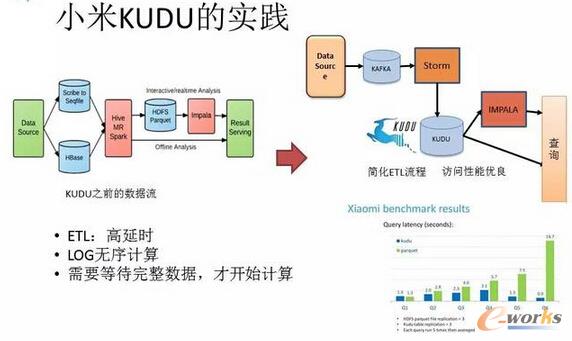
łD19 ąĪ├ūKUDUĄ─īŹ█`
KUDUŻ¼ū▀į┌▀@ā╔éĆśOČ╦Ą─ųąķgŻ¼╦³╝╚─▄ē“▒ŻūC┤¾═╠═┬Ż¼ėų┐╔ęį▒ŻūCĄ═čėĢrĪŻąĪ├ūÅ─╚ź─Ļ╩«į┬Ę▌ķ_╩╝╩╣ė├KUDUŻ¼ų„ę¬ė├ė┌ę╗ą®Ę■äš┘|┴┐▒O┐žĪóå¢Ņ}┼┼▓ķŻ¼┐é¾wĖąėX▀Ć▓╗ÕeĪŻąĪ├ūę▓╩ŪKUDU¼Fį┌ūŅ┤¾Ą─ę╗éĆė├æ¶Ż¼ę“×ķ╬ęéā║▄ČÓĢr║“ąĶę¬┐╝æ]HBase║═DruidŠC║ŽĄ─ę╗ą®ā׳cŻ¼╦∙ęįKUDUę▓╩ŪąĪ├ū─┐Ū░īŹ“ץ─ę╗éĆ╣żŠ▀ĪŻ

łD20 ElasticSearch
ElasticSearch┐╔─▄║▄ČÓ╣½╦ŠČ╝ėąīŹ█`Ż¼═¼śė┐╔ęįī”LOG║═ą┼Žóū÷ę╗ą®Ą╣┼┼▒ĒŻ¼║╦ą─╩Ūė├Lucene╚źū÷╦„ę²ĪŻ
ūŅ║¾Ż¼ąĪ├ūļm╚╗├┐╠ņČ╝į┌╠Ä└Ē┤¾öĄō■ĪóĖ„ĘNė├æ¶Ą─öĄō■Ż¼Ą½╬ęūį╝║Ą─ą┼─ŅŠ═╩Ū“╬ęéāąĶꬎ±▒Żūoūį╝║Ą─č█Š”ę╗śė▒Żūoė├æ¶Ą─ļ[╦Į”Ż¼ąĪ├ūį┌ė├æ¶ļ[╦Į▀@ĘĮ├µ═Č┘Y┴╦║▄ČÓŻ¼▓óū÷│÷┴╦├„┤_Ą─ęÄČ©ĪŻ

łD21 ė├æ¶ļ[╦Į▒Żūo
į┌ÜWų▐Ż¼║▄ČÓ╣½╦Šā╚▓┐Ģ■░čöĄō■Ęų│╔║▄ć└Ė±Ą─Ą╚╝ēŻ¼Ž±éĆ╚╦ą┼ŽóŻ¼╦∙ėą┐╔ęįĻP┬ōĄĮéĆ╚╦Ą─ą┼ŽóČ╝╩Ū┤µį┌ę╗éƬÜ┴óĄ─ÄņŻ¼╚╬║╬╚╦Č╝ø]ėąÖÓŽ▐╚źįLå¢ĪŻ▀Ćėąę╗ą®Ųš═©ą┼ŽóŻ¼┤¾╝ę╩Ū┐╔ęįė├Ą─Ż¼▀Ćėą▒╚╚ńšf│¼▀^ę╗╚f╚╦Ą─ę╗ą®Š█║Žą┼ŽóŻ¼┐╔ęį─├╚źū÷ę╗ą®╦ŃĘ©ĪŻĄ½éĆ╚╦ą┼Žó╩ŪłįøQ▓╗┐╔ęįįLå¢Ą─ĪŻČ°į┌2006─Ļ4į┬14╚šŻ¼ÜWų▐«öĢr▀Ć═Ų│÷┴╦ę╗éĆĘŪ│Ż┐ߥ─ļ[╦ĮÖÓ▒ŻūoŚl└²Ż¼╦³Č©┴x┴╦├┐éĆ╣½╦Šę¬įO┴ó╩ūŽ»öĄō■╣┘Ż¼üĒ▒ŻūoöĄō■ļ[╦ĮŻ¼▓óŪęę¬Ū¾├┐éĆ╣½╦ŠöĄō■Č╝╩Ū┐╔▀węŲĄ─Ż¼ę▓Š═╩ŪšfŻ¼─ŃĄ─╣½╦Šļm╚╗ōĒėąöĄō■Ż¼Ą½öĄō■ėąÖÓ└¹░čī┘ė┌╦¹Ą─éĆ╚╦ą┼ŽóÅ─ę╗éĆĘ■äš╔╠▐DęŲĄĮ┴Ē═Ōę╗éĆĘ■äš╔╠ĪŻ
ĘųŽĒĄ─ūŅ║¾Ż¼┐éĮYę╗Ž┬╬ęū÷öĄō■Ęų╬÷ČÓ─ĻüĒĄ─ą─Ą├Ż║
1Īóø]ėąśIäšæ¬ė├Ą─┤¾öĄō■Č╝╩Ū╦Ż┴„├źŻ¼▓╗ę¬╝ā┤Ō╚źšę╣żŠ▀Ż¼ę╗Č©ę¬ĮY║ŽśIäš╚ź▀xō±ĪŻ
2Īó╝╝ąg▀xą═ø]ėąŽļŽ¾ųą─Ū├┤ųžę¬Ż¼īŹė├║═Š½═©×ķ├ŅĪŻ
3ĪóŠSČ╚▓╗ē“╩Ūę╗éĆė└▀hĄ─═┤Ż¼¤o▒MĄ─é¹ĪŻį┌öĄō■Ęų╬÷Ą─▀^│╠ųąŻ¼ŠSČ╚╩Ū▓╗öÓį÷╝ėĄ─ĪŻ╦∙ęįį┌╬┤üĒ▀xō±╣żŠ▀Ą─═¼ĢrŻ¼ę╗Č©ę¬┐╝æ]ŠSČ╚Ą─į÷╝ėĪŻ
4ĪóŽ±▒Żūo─ŃĄ─č█Š”ę╗śė╚ź▒Żūoė├æ¶Ą─ÖÓ└¹║═ļ[╦ĮĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║─Ń╦∙▓╗ų¬Ą─ąĪ├ū┤¾öĄō■╝╝ąg
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839719834.html