üĒūįIDCĄ─ł¾Ėµ’@╩ŠŻ¼2011─ĻŻ¼1800EBĄ─öĄō■▒╗äōĮ©║═┐ĮžÉŻ¼ŪęöĄō■─Ļį÷ķL┬╩▀_ĄĮ60%ĪŻ╚ń╣¹īó╦∙ėąĄ─öĄō■Č╝┤µā”į┌CD╣Ō▒P╔ŽŻ¼ČčŲüĒĄ─Ė▀Č╚╩ŪĄžŪ“ĄĮį┬Ū“ŠÓļxĄ─6▒ČĪŻ┴Ē═ŌŻ¼ļSų°Ė„ĘN╝ę═źöĄūųĮKČ╦Ą─┼dŲęį╝░Web2.0Ą─ÅVĘ║æ¬ė├Ż¼┤¾▒Ŗ│╔×ķą┼ŽóäōįņĄ─ų„¾wĪŻęŲäė╗ź┬ōŠW░čą┼ŽóĄ─╔·«aÅ─PC═žš╣ĄĮ╩ųÖCŻ¼╬’┬ōŠW░čą┼ŽóĄ─╔·«aÅ─╚╦═žš╣ĄĮ╬’Ż¼IDCŅA£y2020─Ļ╚½Ū“«a╔·Ą─ą┼Žóīó▀_ĄĮ350ā|TBĪŻ▀@ą®öĄō■ųąĄ─Į^┤¾▓┐Ęųīó┤µā”į┌╩└ĮńĖ„ĄžĄ─┤¾ą═öĄō■ųąą─ĪŻłDņ`¬ä½@Ą├š▀JimGrayį°öÓčįŻ¼¼Fį┌├┐18éĆį┬ą┬į÷Ą─öĄō■┴┐Ą╚ė┌ėą╩ĘęįüĒĄ─öĄō■┴┐ų«║═ĪŻą┼ŽóöĄūų╗»╦∙«a╔·Ą─│╩ųĖöĄ╝ēį÷ķLĄ─öĄō■ī”┤µā”ŽĄĮyĄ─╚▌┴┐╠ß│÷┴╦ć└Š■Ą─╠¶æĪŻ
┤┼▒P“īäėŲ„╩Ūę╗ĘNÖCļŖ╗ņ║ŽįOéõĪŻėŗ╦ŃŽÓ▒╚Ż¼┤µā”ŽĄĮyŠ▀ėą║▄ČÓ▓╗═¼Ą─╠žąįĪŻļSų°╔ńĢ■ą┼Žó╗»│╠Č╚Ą─▓╗öÓ╠ßĖ▀Ż¼ī”öĄō■┤µā”Ą─╝▒äĪ╠ß╔²Ż¼ī¦ų┬┴╦ęį“ėŗ╦Ń”×ķųąą─ĄĮęį“öĄō■┤µā””×ķųąą─Ą─ė^─ŅĖ’ą┬ĪŻį┌▀^╚źĄ─╩«ČÓ─ĻųąŻ¼┤┼▒PĄ─ģ^ė“├▄Č╚Īó▄ē├▄Č╚║═ŠĆ├▄Č╚Ęųäe½@Ą├┴╦100%Īó50%║═30%Ą─į÷ķL[4]ĪŻį┌┤µā”ŅIė“ėąā╔éĆųžę¬Ą─╝╝ągī”┤µā”ŽĄĮyĄ─░lš╣║═┤µā”╚▌┴┐Ą─öUš╣«a╔·┴╦ųžę¬Ą─ė░ĒæĪŻĄ┌ę╗éĆ╩Ū▓óąą┤µā”Ż¼▒╚╚ń┤┼▒PĻć┴ą╝╝ąg[5]Ż╗Ą┌Č■éĆŠ═╩ŪŠWĮj╝╝ągī”┤µā”ŽĄĮy¾wŽĄĮYśŗĄ─ė░ĒæĪŻ═©▀^īóŠWĮję²╚ļ┤µā”ŽĄĮyŻ¼Ė─ūāų„ÖC┼c═Ō▓┐┤µā”╣سcķgĄ─▀BĮė─Ż╩ĮŻ¼│÷¼F┴╦╚¶Ė╔ą┬ą═┤µā”¾wŽĄĮYśŗŻ║ĖĮŠW┤µā”Ż©NASŻ®║═┤µā”ģ^ė“ŠWŻ©SANŻ®ĪŻŠWĮj┤µā”╝╝ągī”ė┌ĮŌøQ┤µā”įOéõĄ─Ęų╔óąįĪóI/OĄ─▓óąąąįĪóģfūhĄ─Ė▀ą¦ąį╠ß╣®┴╦ę╗ĘN║▄║├Ą─╩ųČ╬ĪŻŠWĮj┼c┤µā”įOéõ▓╗═¼Ą─ĮY║ŽĘĮ╩Į┐╔ęįą╬│╔▓╗═¼═žōõĮYśŗĄ─ŠWĮj┤µā”ŽĄĮyŻ¼▓╗═¼Ą─═žōõĮYśŗī”ė┌ŽĄĮyąį─▄Ą─ė░Ēæę▓Ė„▓╗ŽÓ═¼ĪŻĄ½ė╔ė┌ąį─▄ĪóārĖ±Īó┐╔öUš╣ąįĄ╚Ė„ĘĮ├µĄ─įŁę“Ż¼▀@ą®╚į▓╗ūŃęįæ¬ī”▒¼š©ąįĄ─öĄō■į÷ķLĪŻ┴Ē═ŌŻ¼įSČÓ┤¾ą═Ų¾śIĄ─IT╗∙ĄAįO╩®Ą─└¹ė├┬╩ų╗ėą35%ĪŻį┌─│ą®Ų¾śIųą┐╔─▄Ģ■Ą═ų┴15%ĪŻGoogleł¾ĖµĘQŲõĘ■äšŲ„Ą─└¹ė├┬╩═∙═∙į┌10%ĄĮ15%ų«ķg[9]ĪŻ▀@╩╣Ą├╣żśIĮń▓╗Ą├▓╗ųžą┬╦╝┐╝╦∙├µ┼RĄ─å¢Ņ}Ż¼▓ó┼¼┴”īżŪ¾ĮŌøQĄ─ĘĮĘ©ĪŻ
2001─ĻŻ¼Googleį┌╦č╦„ę²Ūµ┤¾Ģ■╔Ž╩ū┤╬╠ß│÷įŲėŗ╦ŃĄ─Ė┼─ŅĪŻ2007─Ļ─ĻĄūŻ¼GoogleĄ─ę╗├¹╣ż│╠Ĥį┘┤╬╠ß│÷┴╦įŲėŗ╦ŃĪŻūį┤╦Ż¼įŲėŗ╦Ńķ_╩╝Ą├ĄĮ╣żśIĮńĪóīWągĮń║═Ė„ć°š■Ė«Ą─ÅVĘ║Ēææ¬ĪŻć└Ė±ęŌ┴x╔ŽųvŻ¼įŲėŗ╦Ń▓ó▓╗╩Ūę╗ĘNą┬╝╝ągŻ¼Č°╩Ūę╗ĘNą┬Ą─Ę■äš─Ż╩ĮĪŻįŲėŗ╦Ńīóæ¬ė├║═ėŗ╦ŃÖC┘Yį┤░³└©ė▓╝■║═ŽĄĮy▄ø╝■╠ōöM╗»ų«║¾░³čb│╔Ę■䚯¼═©▀^░┤ąĶĖČ┘MĄ─ĘĮ╩ĮŻ¼┤®įĮInternetüĒØMūŃė├æ¶Ė„ĘN▓╗═¼Ą─ąĶŪ¾ĪŻė├æ¶┐╔ęį▓╗į┘ąĶę¬┘Å┘I░║┘FĄ─ėŗ╦ŃÖCŽĄĮyŻ¼▓╗į┘ę“×ķąĶę¬Č╠Ģrķg╩╣ė├─│éĆ▄ø╝■Č°▓╗Ą├▓╗┘Å┘Iįō▄ø╝■Ą─╩╣ė├░µÖÓĪŻ▀@ĘNĘ■äš─Ż╩Įį┌▀^╚źĄ─╩«ČÓ─Ļųąėą▀^│õĘųĄ─╠ĮėæŻ¼▀@ā╔─ĻĄ─ųžą┬┼dŲ▓óęįę╗éĆą┬Ą─╝╝ąg├¹į~│÷¼FŻ¼▓ó▓╗╩Ūę“×ķ«a╔·┴╦─│ĘN╝╝ąg╔ŽĄ─═╗ŲŲŻ¼Č°╩Ūė╔ė┌ą┼ŽóöĄūų╗»ī¦ų┬öĄō■Ą─▒¼š©ąįį÷ķL╦∙ĦüĒĄ─ę╗ŽĄ┴ąå¢Ņ}ūī╬ęéā▓╗Ą├▓╗ųžą┬╦╝┐╝ėŗ╦ŃÖCŽĄĮy░lš╣Ą─ą┬ū▀Ž“ĪŻ┴Ē═ŌŻ¼ė╔ė┌╝╝ąg▀M▓Į╦∙ĦüĒĄ─▓┐Ęų└Ž╝╝ągĄ─ųžą┬Å═╠Kę▓ī”įŲėŗ╦ŃĄ─░lš╣ŲĄĮ┴╦═Ų▓©ų·×æĄ─ū„ė├ĪŻĮĶų·ė┌įŲėŗ╦ŃĄ─└Ē─ŅŻ¼īó┤µā”┘Yį┤▀Mąąš¹║ŽŻ¼▓óīŹ¼F┤µā”┘Yį┤Ą─░┤ąĶĘų┼õĪŻė┌╩ŪŠ═«a╔·┴╦įŲ┤µā”ĪŻ
1 įŲ┤µā”├µ┼RĄ─╠¶æ
įŲ┤µā”├µŽ“éĆ╚╦Ą─æ¬ė├ų„ę¬ė╔ŠW▒PĪóį┌ŠĆ╬─ÖnŠÄ▌ŗĪó╣żū„┴„╝░╚š│╠░▓┼┼Ż╗├µŽ“Ų¾śIĄ─æ¬ė├ų„ę¬ėąŲ¾śI┐šķgĄ─ūŌ┘UĘ■䚯¼Ų¾śI╝ēöĄō■éõĘ▌║═ÜwÖnĪóęĢŅl▒O┐žŽĄĮyĄ╚ĪŻ¤ošō╩Ū──ĘNæ¬ė├Ż¼║Ż┴┐öĄō■Ą─Ė▀Č╚Š█╝»Č╝ę¬ī¦ų┬┤µā”ŽĄĮyÅ─╔┘öĄĄ─┤µā”ę²ŪµŽ“▀Bį┌ŠWĮj╔ŽĄ─│╔Ū¦╔Ž╚fĄ─╔╠ė├╗»┤µā”įOéõ▀Mąą▐DūāŻ¼Å─é„ĮyĄ─¤¤ćĶ╩ĮĄ─Į©įO─Ż╩Į▐Dūā×ķ╝»╝s╗»Ą─Į©įO─Ż╩ĮĪŻį┌▀^╚źĄ─╩«ČÓ─Ļųą╝»╚║ŠWĮjĄ─ųžę¬▀Mš╣ų«ę╗╩Ū┐╔ęįīó│╔Ū¦╔Ž╚fĄ─╣سc▀BŲüĒŻ¼═¼Ģr▒ŻūCĖ▀┐╔öUš╣ąį║═ŽÓī”▌^Ą═Ą─═©ą┼ķ_õNĪŻę“┤╦Ż¼╬ęéāšJ×ķŻ¼▓╔ė├╔╠ė├╗»Ą─╝╝ągüĒśŗįņ┐╔öUš╣Ą─╝»╚║╩ŪįŲ┤µā”Ą─╗∙▒ŠĮM╝■ĪŻę“×ķ╬ęéā┐╔ęįęį┤ŅĘe─ŠĄ─ą╬╩ĮüĒŠ█║Ž┤µā”ĮM╝■ęįśŗįņ┤¾ęÄ─ŻĄ─┤µā”ŽĄĮyĪŻĄ½╩Ū¼FėąĄ─┤µā”ŽĄĮy▀MąąęÄ─ŻĄ─öUš╣ų«║¾▀Ć┤µį┌║▄ČÓ┤²ĮŌøQĄ─å¢Ņ}ĪŻ
1.1 ├¹ūų┐šķg
┤µā”Ų„┐šķgĄ─ĮM┐Ś║═Ęų┼õŻ¼öĄō■Ą─┤µā”Īó▒Żūo║═Öz╦„Č╝ę└┘ćė┌╬─╝■ŽĄĮyĪŻ╬─╝■ŽĄĮyė╔╬─╝■║═─┐õøĮM│╔ĪŻöĄō■░┤Ųõā╚╚▌ĪóĮYśŗ║═ė├═Š├³├¹│╔▓╗═¼Ą─╬─╝■Ż¼Č°─┐õøätśŗĮ©╬─╝■ŽĄĮyĄ─īė┤╬╗»ĮYśŗĪŻ¼F┤·Ą─╬─╝■ŽĄĮyę╗░ŃČ╝╩Ū░┤śõą╬Ą─īė┤╬╝▄śŗüĒĮM┐Ś╬─╝■║═─┐õøĪŻ╝»╚║╬─╝■ŽĄĮy═∙═∙ę▓▓╔ė├śõą╬╝▄śŗüĒśŗįņ├¹ūų┐šķgĪŻ╚╗Č°Ż¼«ööĄō■Ą─įLå¢Å─śõĖ∙ū▀Ž“śõ╚~Ą─Ģr║“Ż¼įLå¢Ą─čė▀tĢ■ŽÓæ¬Ąžį÷╝ėĪŻ┴Ē═ŌŻ¼▀Ćėąā╔éĆųžę¬Ą─ę“╦žī¦ų┬śõą╬╝▄śŗ▓╗▀m║Žė┌įŲ┤µā”ŁhŠ│ĪŻĄ┌ę╗Ż¼śõĖ∙▒Š╔ĒŠ═╩Ūę╗éĆå╬ę╗╩¦ą¦³cŻ¼Č°Ūę║▄╚▌ęūą╬│╔ŽĄĮyĄ─“Ų┐Ņi”Ż╗Ą┌Č■Ż¼śõą╬╝▄śŗ║▄ļyį┌Internet╔ŽöUš╣ĄĮĄž└Ē╔ŽĘų▓╝Ą─ęÄ─ŻĪŻ┴Ē═ŌŻ¼īė┤╬╗»ĮYśŗ╩╣Ą├╬─╝■Ą─įLå¢ą¦┬╩▓╗Ė▀ĪŻ├┐ę╗īė─┐õøČ╝ļ[▓ž┴╦╦³╦∙░³║¼Ą─ūė─┐õø║═╬─╝■Ż¼ė├æ¶║▄ļyų¬Ą└ę╗éĆ─┐õøŽ┬├µĄĮĄūėą──ą®╬─╝■║═ūė─┐õøĪŻę“┤╦Ż¼ė├æ¶įLå¢─│éĆ╬─╝■ĢrŻ¼▒žĒÜ═©▀^īė┤╬ą═Ą──┐õøśõĮYśŗĄĮ▀_Ųõ▒Ż┤µ╬╗ų├Ż¼╚ń╣¹▓╗ų¬Ą└╬─╝■▒Ż┤µ╬╗ų├Ż¼ät▒žĒÜ▒ķÜvš¹éĆ─┐õøĪŻę“┤╦įŲ┤µā”ų╗ėą▓╔ė├ĘŪ╝»ųą╩ĮĄ─├¹ūų┐šķgüĒ▒▄├ŌØōį┌Ą─ąį─▄“Ų┐Ņi”║═å╬³c╩¦ą¦ĪŻ
1.2 į¬öĄō■ĮM┐Ś
į¬öĄō■╩Ū├Ķ╩÷öĄō■Ą─öĄō■Ż¼ų„ę¬ė├üĒĘ┤ė│ĄžųĘą┼Žó║═┐žųŲą┼ŽóŻ¼═©│Ż░³└©╬─╝■├¹Īó╬─╝■┤¾ąĪĪóĢrķg┤┴Īó╬─╝■ī┘ąįĄ╚Ą╚ĪŻį¬öĄō■ų„ę¬╩Ūė├üĒ╣▄└ĒĄ─▓┘ū„öĄō■ĪŻčąŠ┐▒Ē├„Ż¼į┌╬─╝■ŽĄĮyĄ─▓┘ū„ųąŻ¼│¼▀^50%Ą─▓┘ū„╩Ūßśī”į¬öĄō■Ą─[10]ĪŻį¬öĄō■ūŅųžę¬Ą─╠ž³c╩ŪŲõ═∙═∙╩ŪąĪĄ─ļSÖCšłŪ¾ĪŻę╗░ŃüĒųvŻ¼į¬öĄō■Č╝╩Ū┤µā”į┌┤┼▒P╔ŽĄ─Ż¼╚╗Č°Ż¼║═┤┼▒P┤µā”╚▌┴┐Ą─į÷ķL▓╗═¼Ą─╩ŪŻ¼ė╔ė┌ÖCąĄĮM╝■╦∙ĦüĒĄ─čė▀tŻ¼┤┼▒PĄ─ŲĮŠ∙įLå¢Ģrķg├┐─ĻĄ─ĮĄĄ═▓╗ūŃ8%ĪŻHitachiĄ─┤┼▒Pį┌▀^╚ź10─Ļ└’┤┼▒PįLå¢Ģrķg║═īżĄ└ĢrķgĄ─░lš╣┌ģä▌[12]╚ńłD1╦∙╩ŠĪŻī”ė┌▀@ĘNė╔ąĪĄ─ļSÖCšłŪ¾╦∙ĮM│╔Ą─öĄō■įLå¢┴„Ż¼┤┼▒PĄ─īżĄ└Ģrķg╩Ū┤┼▒PįLå¢čė▀tųąūŅų„ꬥ─▓┐ĘųĪŻę“┤╦Ż¼ī”ė┌┤¾ęÄ─ŻŽĄĮyüĒųvŻ¼į¬öĄō■Ą─įLå¢═∙═∙│╔×ķųŲ╝sš¹éĆŽĄĮyąį─▄Ą─“Ų┐Ņi”ĪŻ
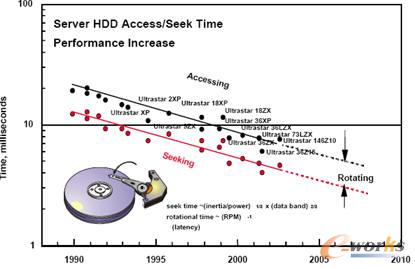
łD1 ┤┼▒PįLå¢Ģrķg║═īżĄ└ĢrķgĄ─░lš╣┌ģä▌
║▄ČÓĘų▓╝╩ĮĄ─┤µā”ŽĄĮyīóöĄō■įLå¢║═į¬öĄō■Ą─įLå¢Ęųļxķ_üĒĪŻį┌▀@śėĄ─ŽĄĮyųąŻ¼┐═æ¶Č╦╩ūŽ╚║═į¬öĄō■Ę■äšŲ„═©ą┼üĒ½@╚Īį¬öĄō■░³└©╬─╝■├¹Īó╬─╝■╬╗ų├Ą╚ą┼ŽóĪŻ╚╗║¾Ż¼└¹ė├įōį¬öĄō■Ż¼┐═æ¶Č╦ų▒Įė║═öĄō■Ę■äšŲ„═©ą┼╚źįL墎Óæ¬Ą─öĄō■ĪŻę╗░ŃüĒųvŻ¼į¬öĄō■Ę■äšŲ„Ą─ā╚┤µ┐╔ęįØMūŃ┤¾▓┐ĘųĄ─ūxšłŪ¾Ż¼Ą½Ę■äšŲ„▓╗Ą├▓╗ų▄Ų┌ąįĄžįLå¢┤┼▒PüĒūx╚ĪąĶꬥ─öĄō■Ż¼▓óŪę╦∙ėąį¬öĄō■Ą─Ė³ą┬ę▓ę¬īæ╗žĄĮ┤┼▒PĪŻ┤µā”ŽĄĮy┐šķgĄ─į÷ķL┐╔ęį═©▀^į÷╝ėŅ~═ŌĄ─┤µā”Ę■äšŲ„üĒ▒ŻūCĪŻ╚╗Č°Ż¼ī”ė┌ę╗éĆ╣▄└ĒöĄęįā|ėŗĄ─öĄō■╬─╝■Ą─įŲ┤µā”ŽĄĮyŻ¼▒ŻūCį¬öĄō■Ą─įLå¢ąį─▄║═┐╔öUš╣ąį▒╚▌^└¦ļyĪŻī”ė┌Ž±įŲ▀@śėĄ─ąĶę¬Ė▀┐╔öUš╣ąįĄ─ŁhŠ│Ż¼ī”į¬öĄō■Ą─ę└┘ćĮoŽĄĮyįOėŗĦüĒ┴╦Š▐┤¾Ą─╠¶æĪŻ
1.3 ─▄║─┼cĄž░Õ┐šķg
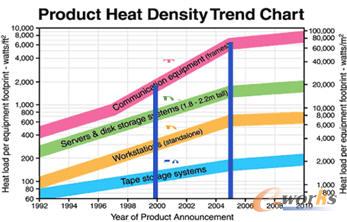
łD2 öĄō■ųąą─Ą─¤ß├▄Č╚┌ģä▌łD
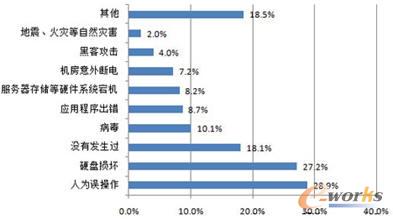
2005─Ļ├└ć°ą┬Į©┴óĄ─öĄō■ųąą─ąĶꬎ¹║─Ą──▄┴┐ŽÓ«öė┌╝ė└¹ĖŻ─ßüåų▌╦∙Ž¹║──▄┴┐Ą─10%Ż©┤¾╝s5GWŻ®Ż¼ąĶę¬╗©┘M┤¾╝s40ā|├└ĮĪŻėóć°Ą─1500éĆöĄō■ųąą─├┐─ĻŽ¹║─Ą──▄┴┐║═ėóć°Ą┌╩«┤¾│Ū╩ą╚R┐©╦╣╠ž╦∙ąĶꬥ──▄┴┐ŽÓ«öĪŻ2010─ĻŻ¼ėóć°å╬éĆöĄō■ųąą─├┐─Ļį┌─▄┴┐╔ŽĄ─╗©┘M▀_ĄĮ┤¾╝s740╚fėóµ^ĪŻį┌▀@ą®öĄō■ųąą─ųąŻ¼┤µā”ŽĄĮy╦∙Ž¹║─Ą──▄┴┐▀_ĄĮ┴╦┐é─▄║─Ą─27%ĪŻ┴Ē═ŌŻ¼Ž¹║─Ą──▄┴┐│²┴╦╣®Ė„ĘNėŗ╦ŃÖCĮM╝■╣żū„═ŌŻ¼▀ĆĢ■«a╔·┤¾┴┐Ą─¤ß┴┐ĪŻė╔ė┌┤¾▓┐Ęųėŗ╦ŃÖCĮM╝■ų╗─▄į┌ę╗Č©Ą─£žČ╚ŁhŠ│Ž┬▓┼─▄▒ŻūCūŃē“Ą─┐╔┐┐ąįŻ¼ę“┤╦Ż¼▀ĆąĶę¬Ņ~═ŌĄ──▄┴┐“īäėųŲ└õįOéõĪŻNetappĄ─š{▓ķ▒Ē├„┤¾ą═öĄō■ųąą─ųąųŲ└õŽĄĮyĄ──▄║─āH┤╬ė┌Ę■äšŲ„ĪŻöĄō■ųąą─ų„ę¬įOéõĄ─¤ß├▄Č╚┌ģä▌╚ńłD2╦∙╩ŠĪŻ┐╔ęįšJ×ķŻ¼öĄō■ųąą─Ą──▄║─å¢Ņ}╠Äė┌ę╗éĆÉ║ąį裣hĄ─ĀŅæBĪŻ
┴Ē═ŌŻ¼ė╔ė┌öĄō■Ą─į÷ķLī¦ų┬öĄō■ųąą─ī”ą┬įOéõąĶŪ¾Ą─▓╗öÓį÷╝ėŻ¼Ą½╩ŪöĄō■ųąą─Ą─┐╔öUš╣ąį═Ļ╚½╩▄Ž▐ė┌ŲõĄž░Õ┐šķgĪŻį┌öĄō■ųąą─Ą─┐šķg╬┤öUš╣Ą─ŪķørŽ┬Ż¼ļSų°å╬╬╗Ąž░Õ├µĘeā╚ėŗ╦ŃÖCįOéõĄ─▓╗öÓį÷╝ėŻ¼é„ĮyöĄō■ųąą─Ą─įOéõ╚▌┴┐▒žīó▀_ĄĮśOŽ▐ĪŻę“┤╦Ż¼─▄║─║═Ąž░Õ┐šķg│╔×ķ«öŪ░įOėŗ║═╣▄└Ē┤¾ą═öĄō■ųąą─╦∙├µ┼RĄ─ų„ę¬╠¶æĪŻ
2 įŲ×─éõ
łD3 öĄō■üG╩¦Ą─įŁę“
ć°ļH╔Žī”ė┌ITŽĄĮy×─ļyĄ─Č©┴x╩ŪųĖė╔ė┌╚╦×ķ╗“ūį╚╗Ą─įŁę“Ż¼įņ│╔ą┼ŽóŽĄĮy▀\ąąć└ųž╣╩šŽ╗“░c»łŻ¼╩╣ą┼ŽóŽĄĮyų¦│ųĄ─śIäš╣”─▄═ŻŅD╗“Ę■äš╦«ŲĮ▓╗┐╔Įė╩▄Ż¼▓ó▀_ĄĮ╠žČ©Ą─ĢrķgĄ─═╗░ląį╩┬╝■ĪŻļm╚╗öĄō■╩ŪŲ¾śIĄ─├³├}Ż¼╚╗Č°į┌é„ĮyĄ─┤µā”ŽĄĮyŽ┬Ż¼öĄō■üG╩¦║▄ļy▒▄├ŌĪŻöĄō■üG╩¦Ą─įŁę“╚ńłD3╦∙╩ŠĪŻłD3▒Ē╩Š╚╦×ķę“╦ž╩Ūī¦ų┬öĄō■üG╩¦Ą─ūŅųžę¬Ą─įŁę“ĪŻė╔ė┌╣▄└ĒåT╗“åT╣żĄ─╗Ņäėįņ│╔öĄō■Ą─ōp╩¦╗“ūāĖ³Ż¼╩╣öĄō■Ą─═Ļš¹ąį┼cšµīŹąį╩▄ĄĮė░ĒæŻ¼╚ńš`äh│²Īóš`Ė±╩Į╗»╗“š`Ęųģ^Īóš`┐╦┬ĪĄ╚š`▓┘ū„Ż¼ŽĄĮy╣▄└ĒåT│÷Õe╗“ąŅęŌŲŲē─ĪóĖ`╚ĪĄ╚Ą╚ĪŻę“┤╦Ż¼╚ń╣¹į┌įŲėŗ╦ŃŁhŠ│Ž┬Ż¼īŻśIĄ─╣ż│╠╝╝ąg╚╦åTīó─▄ūŅ┤¾Ž▐Č╚Ąž▒▄├Ōė╔ė┌╚╦×ķę“╦ž╦∙ī¦ų┬Ą─öĄō■üG╩¦ĪŻ╚╗Č°Ż¼įOéõ║═ė▓╝■╣╩šŽ╦∙ĦüĒĄ─öĄō■üG╩¦ät║▄ļy▒▄├ŌĪŻ└²╚ńŻ¼ė▓▒Pōpē─╩ŪśO×ķ│ŻęŖĄ─ī¦ų┬öĄō■üG╩¦Ą─įŁę“Ż¼ę╗░ŃüĒųvŻ¼┤┼▒PĻć┴ąŻ©RAIDŻ®ŽĄĮy─▄ē“ę╗Č©│╠Č╚╔Ž▒▄├Ōė▓▒P╣╩šŽī¦ų┬Ą─öĄō■üG╩¦Ż¼╚ńRAID1ĪóRAID5Č╝─▄ē“į┌ę╗ēKė▓▒P╩¦ą¦║¾ī”öĄō■▀Mąąą▐Å═ĪŻĄ½į┌ā╔ēKė▓▒P╩¦ą¦Ą─ŪķørŽ┬Ż¼ätāHėąRAID6öĄō■▒Żūo─Ż╩Į─▄ē“▒ŻūoöĄō■▓╗üG╩¦Ż¼Č°RAID6ė╔ė┌Å═ļs╚▀ėÓ║═ąŻ“×╦ŃĘ©ī¦ų┬ŽĄĮy┤¾┴┐Ą─ķ_õNŻ¼ę╗░ŃŲ¾śI▓╔ė├Ģr┤µį┌ŅÖæ]ĪŻ┴Ē═ŌŻ¼┤¾ą═┤µā”ŽĄĮyųą┤┼▒PĄ─╩¦ą¦═∙═∙╩ŪŠ▀ėąŽÓĻPąįĄ─Ż¼ę╗ēK┤¾╚▌┴┐┤┼▒P╩¦ą¦║¾ę¬▀MąąķLĢrķgĄ─ųžśŗŻ©└²╚ńŻ¼1TB╚▌┴┐Ą─┤┼▒Pųžśŗ┐╔─▄ąĶę¬öĄąĪĢrŻ®Ż¼Ģ■ī”ŽĄĮyĦüĒśOĖ▀Ą─┤µā”I/O┬╩Ż¼▀@┐╔─▄ī¦ų┬┴Ēę╗ēK┤┼▒PĄ─╩¦ą¦Ż¼Å─Č°ę²░l▀Bµią¦æ¬ĪŻę“┤╦Ż¼└¹ė├║¹Ą¹ą¦æ¬üĒ├Ķ╩÷║┴▓╗×ķ▀^ĪŻ
2011─Ļ4į┬Ż¼üå±R▀dĄ─ŠWĮjĘ■äšĮøÜv┴╦ķLĢrķgöÓļŖŻ¼įņ│╔═ŻÖCĄ╚ę╗ŽĄ┴ąå¢Ņ}Ż¼▓óŪęė░ĒæĄĮ┴╦įŲėŗ╦ŃĄ─Ę■äšĪŻį┌ķL▀_4╠ņĄ─Ģrķg└’Ż¼ę╗ą®┐═涤oĘ©╩╣ė├üå±R▀dĄ─┤µā”Ę■䚯¼▓óŪęĢ■│÷¼FŠWĮj┼õų├Õeš`ĪŻ2011─Ļ4į┬25╚šŻ¼VmwareĄ─Cloud Foundryį┌░l▓╝13╠ņ║¾▀B└mā╔╠ņ░l╔·Ę■äšųąöÓ╩┬╝■ĪŻĄ┌ę╗┤╬╩Ūė╔ė┌─│╣®ļŖ╣±░l╔·╣╩šŽŻ¼į┌═ŻÖC│ų└m┴╦10ąĪĢr║¾Ż¼╣╩šŽĄ├ĄĮą▐Å═ĪŻĄ½į┌Ą┌Č■╠ņŻ¼«öVmwareĄ─╣┘ĘĮ╣żū„╚╦åTį┌ćLįćīŹ╩®Ž╚Ų┌Öz£yĘĮ░Ėęį▒▄├ŌŪ░ę╗╠ņĄ─╩┬╣╩į┘ę╗┤╬░l╔·ĢrŻ¼ī¦ų┬┴╦ą┬ę╗▌åĄ─═ŻÖCĪŻ2011─Ļ8į┬Ż¼Č╝░ž┴ųĄ─üå±R▀d║═╬ó▄øĄ─öĄō■ųąą─ę“įŌė÷└ūō¶Č°═ŻļŖŻ¼ā╔╝ęŲ¾śIČ╝ĮøÜv┴╦öĄ╠ņ▓┼═Ļ│╔ą▐Å═ĪŻć°ļHūŅų¬├¹Ą─ITŲ¾śIę▓¤oĘ©▒ŻūCŲõIT╗∙ĄAįO╩®Ą─24×7×365śIäš▀B└mąįĪŻį┘š▀Ż¼▓╗┐╔ŅA£yĄ─ūį╚╗×─║”ę▓Ģ■ī¦ų┬öĄō■üG╩¦Ż¼╚ń╚š▒ŠĄ─ÅVŹuĄžšŻ¼ųąć°Ą─Ńļ┤©ĄžšĄ╚ĪŻę“┤╦Ż¼ī”öĄō■▀Mąąėąą¦Ą─×─éõŻ¼▓óĮø│ŻąįĄ─▀Mąą╗ųÅ═č▌ŠÜ┤_▒ŻéõĘ▌Ą─ėąą¦ąį─▄ē“ūŅ┤¾│╠Č╚Ą─ĮĄĄ═ę“×ķė▓╝■╣╩šŽī¦ų┬öĄō■üG╩¦Ą─┐╔─▄ąįŻ¼│õĘųĄ├ĄĮįŲ┤µā”ė├æ¶Ą─ą┼╚╬ĪŻ
2.1 ×─éõĄ─╝╝ągųĖś╦
į┌╚▌×─¾wŽĄųąŻ¼╚╦éā═∙═∙▓╔ė├╗ųÅ═³c─┐ś╦Ż©RPOŻ®║═╗ųÅ═Ģrķg─┐ś╦Ż©RTOŻ®▀@ā╔éĆųĖś╦üĒ║Ō┴┐╚▌×─¾wŽĄĄ─æ¬╝▒─▄┴”║═ŽĄĮy▒Żūo─▄┴”ĪŻRPO¾w¼F×ķ×─ļy░l╔·║¾Ż¼╗ųÅ═▀\▐DĢröĄō■üG╩¦Ą─┐╔╚▌╚╠│╠Č╚ĪŻRTO▒Ē╩ŠąĶę¬╗ųÅ═Ą─ŠoŲ╚ąįę▓╝┤ČÓŠ├─▄ē“Ą├ĄĮ╗ųÅ═Ą─å¢Ņ}ĪŻ╚╗Č°Ż¼į┌įOėŗę╗éĆ╚▌×─ŽĄĮyĢrŻ¼▓ó▓╗ęŌ╬Čų°RPO║═RTOįĮąĪįĮ║├ĪŻę“×ķŽĄĮy═Č┘YĢ■ļSų°RPO║═RTOĄ─ĮĄĄ═Č°į÷╝ėĪŻę“┤╦Ż¼ūŅ╝čĄ─╚▌×─ĘĮ░Ė▓╗ę╗Č©╩Ūąįār▒╚ūŅ║├Ą─ĘĮ░ĖĪŻ
2.2 öĄō■éõĘ▌
öĄō■éõĘ▌╩ŪųĖ×ķĘ└ų╣ŽĄĮy│÷¼F▓┘ū„╩¦š`╗“ŽĄĮy╣╩šŽī¦ų┬öĄō■üG╩¦Ż¼Č°īóöĄō■╝»║ŽÅ─æ¬ė├ŽĄĮyųąęįéõĘ▌Ė±╩Į┤µā”ĄĮ╠Äė┌ļxŠĆĄ─┤µā”Įķ┘|Ą─▀^│╠ĪŻį┌öĄō■éõĘ▌▀^│╠ųąŻ¼ę╗░Ń▓╔ė├éõĘ▌▄ø╝■┼õ║Ž┤┼ĦÄņĄ─╬’└ĒĮķ┘|▒Ż┤µŽĄĮyüĒ▀MąąĪŻöĄō■éõĘ▌Ęų×ķ═Ļ╚½éõĘ▌Īó▓Ņ«ÉéõĘ▌║═į÷┴┐éõĘ▌ĪŻ═Ļ╚½éõĘ▌╩ŪųĖī”─│ę╗éĆĢrķg³c╔ŽĄ─╦∙ėąöĄō■╗“æ¬ė├▀MąąĄ─ę╗éĆ═Ļ╚½┐ĮžÉĪŻ▓Ņ«ÉéõĘ▌ätéõĘ▌ūį╔Žę╗┤╬═Ļ╚½éõĘ▌ų«║¾ėąūā╗»Ą─öĄō■ĪŻį÷┴┐éõĘ▌ätéõĘ▌ūį╔Žę╗┤╬éõĘ▌Ż©░³║¼═Ļ╚½éõĘ▌Īó▓Ņ«ÉéõĘ▌Īóį÷┴┐éõĘ▌Ż®ų«║¾ėąūā╗»Ą─öĄō■ĪŻ¤ošō──ĘN─Ż╩ĮČ╝═Ļ╚½Ę■Å─éõĘ▌ėŗäØĄ─ęÄČ©Ż¼╝┤į┌╣╠Č©Ą─Ģrķg³cķ_╩╝éõĘ▌ĪŻ
é„ĮyĄ─éõĘ▌ŽĄĮy▓ó▓╗▒ŻūCöĄō■Ą─īŹĢrąį╗“Į³īŹĢrąįĪŻČ°ŪęŻ¼éõĘ▌║¾Ą─öĄō■Ė±╩Į╩ŪīŻė├Ą─éõĘ▌Ė±╩ĮŻ¼▓óĘŪæ¬ė├ŽĄĮyųąĄ─öĄō■įŁėąĖ±ŠųĪŻę“┤╦Ż¼«ö░l╔·×─ļyĢrŻ¼éõĘ▌öĄō■╩Ū▓╗─▄┴ó╝┤╩╣ė├Ą─Ż¼▒žĒÜŽ╚╗ųÅ═ĪŻ╗ųÅ═Ģrę¬═©▀^Ė±╩Į▐DōQ▀Mąąī¦╗ž▓┘ū„Ż¼▀@ī¦ų┬¤oĘ©▒ŻūC╗ųÅ═Ą─┐ņĮ▌ĪŻ└²╚ńŻ¼╚ń╣¹░┤ThĄ─ĢrķgķgĖ¶üĒ▀Mąąį÷┴┐éõĘ▌ĪŻ╚ń╣¹į┌AĢrķg³c░l╔·┴╦ŽĄĮy╣╩šŽŻ¼─Ūų╗─▄╗žÅ═ĄĮ╔Žę╗éĆéõĘ▌³cA-TŻ¼Č°Ūę▀Ćę¬▀MąąöĄō■Ė±╩ĮĄ─▐DōQĪŻļSų°TĄ─į÷╝ė║═öĄō■┴┐Ą─į÷ØqŻ¼ąĶę¬╗ųÅ═Ą─Ģrķgę▓ļSų«ŠĆąįį÷ØqĪŻę“┤╦Ż¼ųĖś╦RPO║═RTOČ╝Ģ■▌^Ė▀Ż¼ę▓║▄ļy▒ŻūCIT╗∙ĄAįO╩®Ą─24×7×365śIäš▀B└mąįĪŻ┴Ē═ŌŻ¼×ķ┴╦╠ßĖ▀RPOŻ¼▒žĒÜ╠ßĖ▀öĄō■éõĘ▌Ą─ŅlČ╚ĪŻĄ½┤¾ČÓöĄŪķørŽ┬Ż¼āHāHį÷╝ėéõĘ▌Ą─ŅlČ╚Ģ■ĦüĒę╗ŽĄ┴ąĄ─å¢Ņ}ĪŻ└²╚ńŻ║æ¬ė├Ą─Ė▀ĘÕĢrČ╬¤oĘ©▀MąąéõĘ▌▓┘ū„Ż╗éõĘ▌öĄō■╦∙╗©Ģrķg╠½ķLĪŻę“┤╦Ż¼ąĶę¬ėąę╗éĆŲ§ÖC║═ę╗éĆą┬Ą─╝╝ągĄ─šQ╔·Ż¼üĒ▀_ĄĮęįė├æ¶×ķųąą─Ą─öĄō■░▓╚½║═ŽĄĮy░▓╚½Ą─ę¬Ū¾ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲ┤µā”┼cįŲ×─éõĄ─įŁ└Ē┼cČ╠░ÕĘų╬÷(╔Ž)
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/1083978019.html