OpenStack║åĮķŻ║OpenStack╩Ūų╝į┌×ķ╣½ėą╝░╦ĮėąįŲĄ─Į©įO(sh©©)┼c╣▄└Ē╠ß╣®▄ø╝■Ą─ę╗éĆ(g©©)ķ_į┤ĒŚ(xi©żng)─┐Ż¼▓╔ė├Apache╩┌ÖÓ(qu©ón)ģf(xi©”)ūhŻ¼╦³Ą─║╦ą─╚╬äš(w©┤)╩Ū║å╗»įŲŽĄĮy(t©»ng)Ą─▓┐╩▀^│╠Ż¼▓óŪę┘xėĶŲõ┴╝║├Ą─┐╔öU(ku©░)š╣ąį║═┐╔╣▄└ĒąįĪŻ╦³ęčĮø(j©®ng)į┌«ö(d©Īng)Ū░Ą─╗∙ĄA(ch©│)įO(sh©©)╩®╝┤Ę■äš(w©┤)(IaaS)┘Yį┤╣▄└ĒŅI(l©½ng)ė“š╝ō■(j©┤)ŅI(l©½ng)ī¦(d©Żo)Ąž╬╗Ż¼│╔×ķ╣½ėąįŲĪó╦ĮėąįŲ╝░╗ņ║ŽįŲ╣▄└ĒĄ─“įŲ▓┘ū„ŽĄĮy(t©»ng)”╩┬īŹ(sh©¬)╔ŽĄ─ś╦(bi©Īo)£╩(zh©│n)Ż¼į┌š■Ė«ĪóļŖą┼ĪóĮ╚┌ĪóųŲįņĪó─▄į┤Īó┴Ń╩█Īóßt(y©®)»¤ĪóĮ╗═©Ą╚ąąśI(y©©)│╔×ķŲ¾śI(y©©)äō(chu©żng)ą┬Ą─└¹Ų„ĪŻOpenStack╗∙ė┌ķ_Ę┼Ą─╝▄śŗ(g©░u)Ż¼ų¦│ųČÓĘNų„┴„Ą─╠ōöM╗»╝╝ąg(sh©┤)Ż¼įSČÓųž┴┐╝ē(j©¬)Ą─┐Ų╝╝╣½╦Š╚ńRedHatŻ¼AT&TŻ¼IBMŻ¼HPŻ¼SUSEŻ¼IntelŻ¼AMDŻ¼CiscoŻ¼MicrosoftŻ¼CitrixŻ¼DellĄ╚ģó┼cžĢ½I(xi©żn)įO(sh©©)ėŗ(j©¼)║═īŹ(sh©¬)¼F(xi©żn)Ż¼Ė³╝ė═Ųäė(d©░ng)┴╦OpenStackĄ─Ė▀╦┘│╔ķLŻ¼┤“ŲŲ┴╦AmazonĄ╚╔┘öĄ(sh©┤)╣½╦Šį┌╩ął÷╔Žē┼öÓĄ─Šų├µŻ¼ĮŌøQįŲĘ■äš(w©┤)▒╗å╬ę╗ÅS╔╠ĮēČ©Ą─å¢Ņ}▓óĮĄĄ═┴╦įŲŲĮ┼_(t©ói)▓┐╩│╔▒ŠĪŻ
OpenStack┘Yį┤š{(di©żo)Č╚║═ā×(y©Łu)╗»¼F(xi©żn)ĀŅ
OpenStackĄ─╠ōöMÖC(j©®)š{(di©żo)Č╚▓▀┬įų„ę¬╩Ūė╔FilterScheduler║═ChanceSchedulerīŹ(sh©¬)¼F(xi©żn)Ą─Ż¼ŲõųąFilterSchedulerū„×ķ─¼šJ(r©©n)Ą─š{(di©żo)Č╚ę²ŪµīŹ(sh©¬)¼F(xi©żn)┴╦╗∙ė┌ų„ÖC(j©®)▀^×V(filtering)║═ÖÓ(qu©ón)ųĄėŗ(j©¼)╦Ń(weighing)Ą─š{(di©żo)Č╚╦ŃĘ©Ż¼Č°ChanceSchedulerät╩Ū╗∙ė┌ļSÖC(j©®)╦ŃĘ©üĒ▀xō±┐╔ė├ų„ÖC(j©®)Ą─║åå╬š{(di©żo)Č╚ę²ŪµĪŻ╚ńłD1╩ŪFilterSchedulerĄ─╠ōöMÖC(j©®)š{(di©żo)Č╚▀^│╠Ż¼╦³ų¦│ųČÓĘNbuilt-inĄ─filter║═weigherüĒØMūŃę╗ą®│ŻęŖĄ─śI(y©©)äš(w©┤)ł÷Š░ĪŻį┌įO(sh©©)ėŗ(j©¼)╔ŽŻ¼OpenStack╗∙ė┌filter║═weigherų¦│ųĄ┌╚²ĘĮöU(ku©░)š╣Ż¼ę“┤╦ė├æ¶┐╔ęį═©▀^ūįČ©┴xfilter║═weigherŻ¼╗“š▀╩╣ė├json┘Yį┤▀xō±▒Ē▀_(d©ó)╩ĮüĒė░Ēæ╠ōöMÖC(j©®)Ą─š{(di©żo)Č╚▓▀┬įÅ─Č°ØMūŃ▓╗═¼Ą─śI(y©©)äš(w©┤)ąĶŪ¾ĪŻ
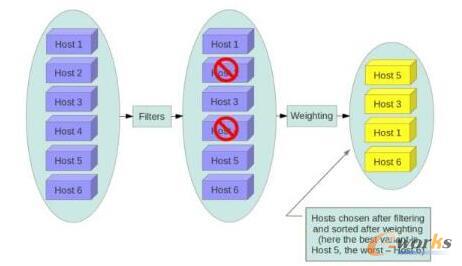
łD1 OpenStackš{(di©żo)Č╚workflow
Built-inĄ─filter(▓┐Ęų)Ż║
1 ComputeFilter▀^×Vėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)downÖC(j©®)Ą─ų„ÖC(j©®)
2 CoreFilter▀^×Vvcpu▓╗ØMūŃ╠ōöMÖC(j©®)šł(q©½ng)Ū¾Ą─ų„ÖC(j©®)
3 DiskFilter▀^×Vdisk▓╗ØMūŃ╠ōöMÖC(j©®)šł(q©½ng)Ū¾Ą─ų„ÖC(j©®)
4 RamFilter▀^×Vram▓╗ØMūŃ╠ōöMÖC(j©®)šł(q©½ng)Ū¾Ą─ų„ÖC(j©®)
5 ImagePropertiesFilter▀^×VarchitectureŻ¼hypervisortype▓╗ØMūŃ╠ōöMÖC(j©®)šł(q©½ng)Ū¾Ą─ų„ÖC(j©®)
6 SameHostFilter▀^×V║═ųĖČ©╠ōöMÖC(j©®)▓╗į┌═¼ę╗éĆ(g©©)ų„ÖC(j©®)╔ŽĄ─ų„ÖC(j©®)
7 DifferentHostFilter▀^×V║═ųĖČ©╠ōöMÖC(j©®)į┌═¼ę╗éĆ(g©©)ų„ÖC(j©®)╔ŽĄ─ų„ÖC(j©®)
JsonFilter▀^×V▓╗ØMūŃOpenStackūįČ©┴xĄ─json┘Yį┤▀xō±▒Ē▀_(d©ó)╩ĮĄ─ų„ÖC(j©®)Ż║json┘Yį┤▀xō±▒Ē▀_(d©ó)╩Įą╬╚ńquery=’[“>”Ż¼“$cpus”Ż¼4]’▒Ē╩Š▀^×VĄ¶cpusąĪė┌Ą╚ė┌4Ą─ų„ÖC(j©®)
Built-inĄ─weigher(▓┐Ęų)Ż║
1 RAMWeigherĖ∙ō■(j©┤)ų„ÖC(j©®)Ą─┐╔ė├ram┼┼ą“
2 IoOpsWeigherĖ∙ō■(j©┤)ų„ÖC(j©®)Ą─iožō(f©┤)▌d┼┼ą“
į┌ę╗éĆ(g©©)Å═(f©┤)ļsĄ─įŲŽĄĮy(t©»ng)ųąŻ¼ī”(du©¼)įŲėŗ(j©¼)╦Ń┘Yį┤Ą─▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»ī”(du©¼)ė┌▒ŻūCįŲŽĄĮy(t©»ng)Ą─ĮĪ┐Ą▀\(y©┤n)ąąŻ¼╠ßĖ▀IT╣▄└ĒĄ─ą¦┬╩ėąųžę¬Ą─ū„ė├ĪŻūŅą┬░µ▒ŠĄ─OpenStackę▓ø]ėą╠ß╣®ŅÉ╦ŲĄ─╣”─▄Ż¼▀@┐╔─▄╩Ūė╔ė┌įŲŽĄĮy(t©»ng)Ą─▒O(ji©Īn)┐žĄ─ī”(du©¼)Ž¾║═ā×(y©Łu)╗»─┐ś╦(bi©Īo)ī”(du©¼)ė┌▓╗═¼Ą─ė├æ¶ėą▓╗═¼Ą─ę¬Ū¾Ż¼ļyė┌ą╬│╔Įy(t©»ng)ę╗īŹ(sh©¬)¼F(xi©żn)║═╝▄śŗ(g©░u)Ż¼Ą½╩ŪOpenStackęčĮø(j©®ng)ęŌūR(sh©¬)ĄĮ▀@▓┐ĘųĄ─ųžę¬ąį▓óŪęåóäė(d©░ng)┴╦2éĆ(g©©)ĒŚ(xi©żng)─┐üĒÅøča(b©│)▀@éĆ(g©©)Č╠░ÕŻ¼«ö(d©Īng)Ū░╦³éāČ╝╠Äė┌ʧ╗»ļAČ╬Ż║
Watcher(httpsŻ║//github.com/openstack/watcher)Ż║ę╗éĆ(g©©)ņ`╗ŅĄ─Īó┐╔╔ņ┐sĄ─ČÓūŌæ¶OpenStack-basedįŲ┘Yį┤ā×(y©Łu)╗»Ę■äš(w©┤)Ż¼═©▀^ųŪ─▄Ą─╠ōöMÖC(j©®)▀węŲ▓▀┬įüĒ£p╔┘öĄ(sh©┤)ō■(j©┤)ųąą─Ą─▀\(y©┤n)ĀI│╔▒Š║═į÷╝ė─▄į┤Ą─└¹ė├┬╩ĪŻ
Congress(httpsŻ║//github.com/openstack/congress)Ż║ę╗éĆ(g©©)╗∙ė┌«Éśŗ(g©░u)įŲŁh(hu©ón)Š│Ą─▓▀┬į┬Ģ├„Īó▒O(ji©Īn)┐žŻ¼īŹ(sh©¬)╩®Ż¼īÅėŗ(j©¼)Ą─┐“╝▄ĪŻ
PRS║åĮķ
ė╔ė┌OpenStackķ_į┤Ą─╠žąįŻ¼ų▒Įė═Č╚ļ╔╠śI(y©©)╩╣ė├┐╔─▄├µ┼R║¾Ų┌╔²╝ē(j©¬)Ż¼ŠSūo(h©┤)Ż¼Č©ųŲ╗»ąĶŪ¾¤oĘ©═Ų▀M(j©¼n)Ą─å¢Ņ}Ż¼ę“┤╦ę╗ą®ėą╝╝ąg(sh©┤)īŹ(sh©¬)┴”Ą─╣½╦ŠČ╝╗∙ė┌OpenStackķ_░l(f©Ī)┴╦ūį╝║╔╠śI(y©©)╗»Ą─░µ▒ŠŻ¼▀@ą®╔╠śI(y©©)╗»░µ▒ŠĄ─OpenStackČ╝░³║¼┴╦ę╗ą®¬Ü(d©▓)ėąĄ─╠žąį▓ó║═╔ńģ^(q©▒)ķ_į┤Ą─OpenStacką╬│╔┴╦▓Ņ«É╗»Ż¼▒╚╚ń═Ļ╔Ų┴╦OpenStack╠ōöMÖC(j©®)Ą─š{(di©żo)Č╚║═ŠÄ┼┼╣”─▄Ż¼╝ėÅŖ(qi©óng)┴╦įŲŽĄĮy(t©»ng)Ą─▀\(y©┤n)ąąĢr(sh©¬)▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»Ż¼Åøča(b©│)┴╦įŲŽĄĮy(t©»ng)ūįäė(d©░ng)╗»×─(z©Īi)ļy╗ųÅ═(f©┤)Ą─┐š╚▒Ż¼║å╗»┴╦įŲŽĄĮy(t©»ng)Ą─░▓čb║═▓┐╩Ż¼ę²╚ļ┴╦╗∙ė┌┘Yį┤╩╣ė├Ģr(sh©¬)ķLĄ─Äżäš(w©┤)┘M(f©©i)ė├ŽĄĮy(t©»ng)Ą╚Ą╚ĪŻPRS(PlatformResourceScheduler)╩ŪIBMPlatformComputing╣½╦ŠĄ─╗∙ė┌OpenStackĄ─╔╠śI(y©©)╗»┘Yį┤š{(di©żo)Č╚Ż¼ŠÄ┼┼║═ā×(y©Łu)╗»Ą─ę²ŪµŻ¼╦³╗∙ė┌ī”(du©¼)įŲėŗ(j©¼)╦Ń┘Yį┤Ą─│ķŽ¾║═ŅA(y©┤)Ž╚Č©┴xĄ─š{(di©żo)Č╚║═ā×(y©Łu)╗»▓▀┬įŻ¼×ķ╠ōöMÖC(j©®)Ą─Ę┼ų├äė(d©░ng)æB(t©żi)ĄžĘų┼õ║═ŲĮ║Ōėŗ(j©¼)╦Ń╚▌┴┐Ż¼▓óŪę▓╗ķgöÓĄž▒O(ji©Īn)┐žų„ÖC(j©®)Ą─ĮĪ┐ĄĀŅørŻ¼╠ßĖ▀┴╦ų„ÖC(j©®)Ą─└¹ė├┬╩▓ó▒Ż│ųė├æ¶śI(y©©)äš(w©┤)Ą─│ų└m(x©┤)ąį║═ĘĆ(w©¦n)Č©ąįŻ¼ĮĄĄ═IT╣▄└Ē│╔▒ŠĪŻPRS▓╔ė├┐╔▓Õ░╬╩ĮĄ─¤oŪų╚ļįO(sh©©)ėŗ(j©¼)Ż¼100%╝µ╚▌OpenStackAPIŻ¼▓óŪęī”(du©¼)═Ō╠ß╣®ś╦(bi©Īo)£╩(zh©│n)Ą─Įė┐┌Ż¼ĘĮ▒Ńė├æ¶▀M(j©¼n)ąąČ■┤╬ķ_░l(f©Ī)Ż¼ęįØMūŃ▓╗═¼ė├æ¶Ą─śI(y©©)äš(w©┤)ąĶŪ¾ĪŻ▒Š╬─īóĢ■(hu©¼)Å─╠ōöMÖC(j©®)│§╩╝š{(di©żo)Č╚▓▀┬įŻ¼īŹ(sh©¬)Ģr(sh©¬)▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»▓▀┬įŻ¼ė├æ¶ūįČ©┴xOpenStackFilterŻ¼╠ōöMÖC(j©®)š{(di©żo)Č╚╩¦öĪĄ─TroubleShootingReport║═╗∙ė┌═ž?f©┤)õĮY(ji©”)śŗ(g©░u)š{(di©żo)Č╚Ą╚ĘĮ├µĖ┼└©ĮķĮBPRSĄ─ų„ę¬╣”─▄║═╩╣ė├ł÷Š░Ż¼ų«║¾īóėąę╗ŽĄ┴ą╬─š┬ī”(du©¼)├┐éĆ(g©©)ų„Ņ}š╣ķ_╔Ņ╚ļĮķĮBĪŻ
╠ōöMÖC(j©®)│§╩╝š{(di©żo)Č╚▓▀┬į
╠ōöMÖC(j©®)Ą─│§╩╝Ę┼ų├▓▀┬įųĖĄ─╩Ūė├æ¶Ė∙ō■(j©┤)╠ōöMÖC(j©®)ī”(du©¼)┘Yį┤Ą─ę¬Ū¾øQČ©╠ōöMÖC(j©®)Š┐Š╣æ¬(y©®ng)įōäō(chu©żng)Į©į┌──ĘNŅÉą═Ą─ų„ÖC(j©®)╔ŽŻ¼▀@ĘN┘Yį┤ę¬Ū¾Š═╩Ūę╗ą®╝s╩°Śl╝■╗“š▀▓▀┬įĪŻ└²╚ńŻ¼ė├æ¶Ą─╠ōöMÖC(j©®)ąĶę¬▀xō±CPU╗“š▀ā╚(n©©i)┤µ┤¾ąĪØMūŃę╗Č©ę¬Ū¾Ą─ų„ÖC(j©®)╚źĘ┼ų├Ż¼╠ōöMÖC(j©®)╩ŪąĶę¬Ę┼ų├į┌▒▒Š®Ą─öĄ(sh©┤)ō■(j©┤)ųąą─▀Ć╩Ū╬„░▓Ą─öĄ(sh©┤)ō■(j©┤)ųąą─Ż¼ÄūéĆ(g©©)╠ōöMÖC(j©®)╩ŪĘ┼į┌ŽÓ═¼Ą─ų„ÖC(j©®)╔Ž▀Ć╩ŪĘ┼ų├į┌▓╗═¼Ą─ų„ÖC(j©®)╔ŽĄ╚Ą╚ĪŻįŁ╔·OpenStackš{(di©żo)Č╚┐“╝▄į┌ņ`╗ŅĄ─ų¦│ųĄ┌╚²ĘĮĄ─filter║═weigherĄ─═¼Ģr(sh©¬)ę▓å╩╩¦┴╦ī”(du©¼)š{(di©żo)Č╚▓▀┬įĄ─Įy(t©»ng)ę╗┼õų├║═╣▄└ĒŻ¼«ö(d©Īng)Ū░PRSų¦│ų╚ńłD2Ą─│§╩╝Ę┼ų├▓▀┬įŻ¼▓óŪę┐╔ęįį┌▀\(y©┤n)ąąĢr(sh©¬)äė(d©░ng)æB(t©żi)Ą─ą▐Ė─Ę┼ų├▓▀┬įĪŻ
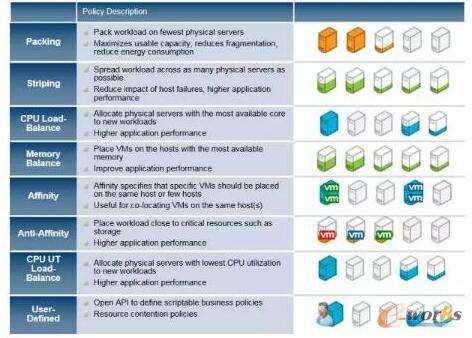
łD2 ╠ō╦ŲÖC(j©®)│§╩╝Ę┼ų├▓▀┬į
- PackingŻ║╠ōöMÖC(j©®)▒M┴┐Ę┼ų├į┌║¼ėą╠ōöMÖC(j©®)öĄ(sh©┤)┴┐ūŅČÓĄ─ų„ÖC(j©®)╔Ž
- StrippingŻ║╠ōöMÖC(j©®)▒M┴┐Ę┼ų├į┌║¼ėą╠ōöMÖC(j©®)öĄ(sh©┤)┴┐ūŅ╔┘Ą─ų„ÖC(j©®)╔Ž
- CPUlOAdbalanceŻ║╠ōöMÖC(j©®)▒M┴┐Ę┼į┌┐╔ė├coreūŅČÓĄ─ų„ÖC(j©®)╔Ž
- MemoryloadbalanceŻ║╠ōöMÖC(j©®)▒M┴┐Ę┼į┌┐╔ė├memoryūŅČÓĄ─ų„ÖC(j©®)╔Ž
- AffinityŻ║ČÓéĆ(g©©)╠ōöMÖC(j©®)ąĶę¬Ę┼ų├į┌ŽÓ═¼Ą─ų„ÖC(j©®)╔Ž
- AntiAffinityŻ║ČÓéĆ(g©©)╠ōöMÖC(j©®)ąĶę¬Ę┼į┌į┌▓╗═¼Ą─ų„ÖC(j©®)╔Ž
- CPUUtilizationloadbalanceŻ║╠ōöMÖC(j©®)▒M┴┐Ę┼į┌CPU└¹ė├┬╩ūŅĄ═Ą─ų„ÖC(j©®)╔Ž
īŹ(sh©¬)Ģr(sh©¬)▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»▓▀┬į
ļSų°OpenStackįŲŽĄĮy(t©»ng)Ą─│ų└m(x©┤)▀\(y©┤n)ąąŻ¼įŲŽĄĮy(t©»ng)ųąĄ─ėŗ(j©¼)╦Ń┘Yį┤ė╔ė┌╠ōöMÖC(j©®)Ą─Ę┼ų├Ģ■(hu©¼)«a(ch©Żn)╔·╦ķŲ¼╗“Ęų┼õ▓╗Š∙Ż¼╠ōöMÖC(j©®)Ą─▀\(y©┤n)ąąą¦┬╩ė╔ė┌ų„ÖC(j©®)load▀^▌dČ°ĮĄĄ═Ż¼ų„ÖC(j©®)Ą─downÖC(j©®)Ģ■(hu©¼)įņ│╔ė├æ¶æ¬(y©®ng)ė├│╠ą“¤oĘ©╩╣ė├Ą╚ę╗ŽĄ┴ąå¢Ņ}ĪŻė├æ¶┐╔ęį═©▀^╚╦╣żĖ╔ŅA(y©┤)Ą─ĘĮ╩ĮüĒ┼┼│²▀@ą®å¢Ņ}.└²╚ńė├æ¶┐╔ęįīóload▒╚▌^Ė▀Ą─ų„ÖC(j©®)╔ŽĄ─╠ōöMÖC(j©®)migrateĄĮŲõ╦¹ų„ÖC(j©®)╔ŽüĒĮĄĄ═įōų„ÖC(j©®)Ą─loadŻ¼═©▀^rebuild╠ōöMÖC(j©®)Å─downĄ¶Ą─ų„ÖC(j©®)╔ŽĄĮŲõ╦³┐╔ė├ų„ÖC(j©®)╔ŽĮŌøQė├æ¶æ¬(y©®ng)ė├│╠ą“Ė▀┐╔ė├ąįĄ─å¢Ņ}Ż¼Ą½▀@ąĶꬎ¹║─┤¾┴┐Ą─ITŠSūo(h©┤)│╔▒ŠŻ¼▓óŪęę²╚ļĖ³ČÓĄ─╚╦×ķĄ─’L(f©źng)ļU(xi©Żn)ĪŻPRSßśī”(du©¼)▀@ą®å¢Ņ}╠ß╣®┴╦╚ńłD3Ą─ā╔ĘNŅÉą═Ą─▀\(y©┤n)ąąĢr(sh©¬)▓▀┬įüĒ│ų└m(x©┤)Ą─▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»įŲŽĄĮy(t©»ng)ĪŻ

łD3 ▒O(ji©Īn)┐ž║═ā×(y©Łu)╗»▓▀┬į
╗∙ė┌╠ōöMÖC(j©®)Ą─HA▓▀┬įŻ║«ö(d©Īng)ų„ÖC(j©®)downÖC(j©®)║¾Ż¼ų„ÖC(j©®)╔Ž▀\(y©┤n)ąąĄ─╠ōöMÖC(j©®)Ģ■(hu©¼)ūįäė(d©░ng)rebuildĄĮą┬Ą─┐╔ė├ų„ÖC(j©®)╔Ž
╗∙ė┌ų„ÖC(j©®)Ą─LoadBalance▓▀┬įŻ║ų¦│ųPacking/Stripping/CPUloadbalance/Memoryloadbalance/CPUUtilizationloadbalance▓▀┬įŻ¼Ė∙ō■(j©┤)ė├æ¶įO(sh©©)ų├Ą─ķōųĄ│ų└m(x©┤)▓╗öÓĄ─ŲĮ║ŌŽĄĮy(t©»ng)ųąų„ÖC(j©®)╔ŽĄ─ėŗ(j©¼)╦Ń┘Yį┤
ė├æ¶┐╔ęįĖ∙ō■(j©┤)śI(y©©)äš(w©┤)ąĶę¬Č©┴xŽÓæ¬(y©®ng)Ą─ā×(y©Łu)╗»▓▀┬į▒O(ji©Īn)┐žų„ÖC(j©®)Ą─ĮĪ┐ĄĀŅør▓ó▀M(j©¼n)ąą│ų└m(x©┤)▓╗öÓĄ─ā×(y©Łu)╗»ĪŻ└²╚ńŻ¼ė├æ¶Č©┴xĄ─╝»╚║ųąų„ÖC(j©®)▀\(y©┤n)ąąĢr(sh©¬)▒O(ji©Īn)┐žLoadBalance▓▀┬į╩ŪCPUUtilizationLoadBalanceŻ¼▓óŪęķōųĄ╩Ū70%Ż¼▀@Š═ęŌ╬Čų°«ö(d©Īng)ų„ÖC(j©®)Ą─CPU└¹ė├┬╩│¼▀^70%Ą─Ģr(sh©¬)║“Ż¼▀@éĆ(g©©)ų„ÖC(j©®)╔ŽĄ─╠ōöMÖC(j©®)Ģ■(hu©¼)▒╗PRSį┌ŠĆ▀węŲĄĮäeĄ─CPU└¹ė├┬╩ąĪė┌70%Ą─ų„ÖC(j©®)╔ŽŻ¼Å─Č°▒ŻūCįōų„ÖC(j©®)╩╝ĮK╠Äė┌ĮĪ┐ĄĄ─ĀŅæB(t©żi)Ż¼▓óŪęŲĮ║Ō┴╦╝»╚║ųąų„ÖC(j©®)Ą─ėŗ(j©¼)╦Ń┘Yį┤ĪŻ▀@ā╔ĘN▀\(y©┤n)ąąĢr(sh©¬)▒O(ji©Īn)┐ž▓▀┬į┐╔ęį═¼Ģr(sh©¬)▀\(y©┤n)ąą▓óŪę┐╔ęįųĖČ©▒O(ji©Īn)┐žĄ─ĘČć·Ż║
š¹éĆ(g©©)╝»╚║Ż║▒O(ji©Īn)┐žĄ─▓▀┬įū„ė├ė┌š¹éĆ(g©©)╝»╚║ųą╦∙ėąĄ─ų„ÖC(j©®)
HostaggregationŻ║hostaggregation╩ŪOpenStackī”(du©¼)ę╗╚║Š▀ėąŽÓ═¼ų„ÖC(j©®)ī┘ąįĄ─ę╗éĆ(g©©)▀ē▌ŗäØĘųŻ¼▀@śėė├æ¶┐╔ęįĖ∙ō■(j©┤)śI(y©©)äš(w©┤)ąĶŪ¾ī”(du©¼)▓╗═¼Ą─hostaggregationČ©┴x▓╗═¼LoadBalance▓▀┬įŻ¼└²╚ńī”(du©¼)aggregation1æ¬(y©®ng)ė├Packing▓▀┬įŻ¼ī”(du©¼)aggregation2æ¬(y©®ng)ė├Stripping▓▀┬įĪŻ
ė├æ¶ūįČ©┴xOpenStackFilter
OpenStackī”(du©¼)╠ōöMÖC(j©®)Ą─š{(di©żo)Č╚╩Ū╗∙ė┌ī”(du©¼)ų„ÖC(j©®)Ą─▀^×V║═ÖÓ(qu©ón)ųĄėŗ(j©¼)╦ŃŻ¼PRSę▓īŹ(sh©¬)¼F(xi©żn)┴╦ŽÓ═¼Ą─╣”─▄Ż¼▓óŪę×ķ╠ß╣®┴╦Ė³╝ėā×(y©Łu)č┼Ą─Įė┐┌ĘĮ▒Ńė├æ¶Č©┴x│÷Å═(f©┤)ļsĄ─filterµ£Ż¼▓óŪę┼õ║Ž╩╣ė├╠ōöMÖC(j©®)│§╩╝š{(di©żo)Č╚▓▀┬įÅ─Č°äė(d©░ng)æB(t©żi)Ą─īóė├æ¶ūįČ©┴xĄ─╠ōöMÖC(j©®)Ę┼ų├▓▀┬į▓Õ╚ļĄĮ╠ōöMÖC(j©®)Ą─š{(di©żo)Č╚▀^│╠ųą╚źØMūŃśI(y©©)äš(w©┤)ąĶŪ¾Ż║
PRSfilterų¦│ųČ©┴xworkingscopeŻ║OpenStackįŁ╔·Ą─filterĢ■(hu©¼)─¼šJ(r©©n)ū„ė├ė┌╠ōöMÖC(j©®)š{(di©żo)Č╚Ą─š¹éĆ(g©©)╔·├³ų▄Ų┌Ż¼▒╚╚ńcreateŻ¼livemigrateŻ¼coldmigrateŻ¼resizeĄ╚ĪŻČ°PRS×ķfilterČ©┴x┴╦workingscopeŻ¼▀@śė┐╔ęįīŹ(sh©¬)¼F(xi©żn)ūī─│ą®filterį┌create╠ōöMÖC(j©®)Ą─Ģr(sh©¬)║“╔·ą¦Ż¼─│ą®filterį┌╠ōöMÖC(j©®)migrateĄ─Ģr(sh©¬)║“╔·ą¦Ż¼▓óŪę▀Ćų¦│ųūīę╗éĆ(g©©)filter╣żū„į┌ČÓéĆ(g©©)workingscope
PRSfilterų¦│ųČ©┴xincludehosts║═excludehostsŻ║ė├æ¶┐╔ęįų▒Įėį┌filterųą×ķ╠ōöMÖC(j©®)ųĖČ©ąĶę¬┼┼│²Ą─ų„ÖC(j©®)┴ą▒Ē╗“š▀ąĶę¬Ę┼ų├Ą─ų„ÖC(j©®)┴ą▒Ē
PRSfilterų¦│ųČ©┴xPRS┘Yį┤▓ķįāŚl╝■Ż║ė├æ¶ę▓┐╔ęįį┌filterųąČ©┴xPRS┘Yį┤▓ķįāŚl╝■Ż¼ų▒Įė▀xō±Śl╝■Š▀éõūĪų„ÖC(j©®)┴ą▒ĒŻ¼└²╚ńselect(vcpu>2&&memSize>1024)

łD4 PRS filter workflow
╠ōöMÖC(j©®)š{(di©żo)Č╚╩¦öĪTroubleShootingReport
«ö(d©Īng)╠ōöMÖC(j©®)äō(chu©żng)Į©╩¦öĪ╠Äė┌ErrorĄ─Ģr(sh©¬)║“Ż¼įŲŽĄĮy(t©»ng)æ¬(y©®ng)įō╠ß╣®ūŃē“Ą──▄┴”ĘĮ▒Ń╣▄└ĒåTtroubleshootingŻ¼Å─Č°▒M┐ņ┼┼│²Õe(cu©░)š`▓ó▒ŻūCįŲŽĄĮy(t©»ng)š²│Ż▀\(y©┤n)ąąĪŻįņ│╔╠ōöMÖC(j©®)▓┐╩╩¦öĪĄ─įŁę“ų„ę¬ėą2ĘNŻ║Ą┌ę╗ĘN╩Ūš{(di©żo)Č╚╩¦öĪŻ¼ø]ėąūŃē“Ą─ėŗ(j©¼)╦Ń┘Yį┤╗“š▀║Ž▀mĄ─ų„ÖC(j©®)ØMūŃ╠ōöMÖC(j©®)╠ōöMÖC(j©®)Ą─šł(q©½ng)Ū¾ĪŻĄ┌Č■ĘN╩Ūš{(di©żo)Č╚│╔╣”Ż¼Ą½╩Ūį┌ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)╔Ž▓┐╩╠ōöMÖC(j©®)Ą─Ģr(sh©¬)║“╩¦öĪŻ¼įŁę“╩ŪČÓĘNČÓśėĄ─Ż¼▒╚╚ńLibvirtÕe(cu©░)š`Ż¼imageŅÉą═Õe(cu©░)š`Ż¼äō(chu©żng)Į©╠ōöMÖC(j©®)ŠW(w©Żng)Įj(lu©░)╩¦öĪĄ╚ĪŻ«ö(d©Īng)Ū░Ą─OpenStack╠ōöMÖC(j©®)Ą─TroubleShootingÖC(j©®)ųŲ▓╗─▄ŪÕ╬·Ę┤ė│å¢Ņ}Ą─įŁę“Ż¼ąĶę¬╣▄└ĒåT┤¾┴┐Ą─Ęų╬÷╣żū„Ż¼▀@¤oę╔į÷╝ė┴╦┼┼│²å¢Ņ}Ą─ļyČ╚║═Ģr(sh©¬)ķgŻ║
ī”(du©¼)ė┌╠ōöMÖC(j©®)š{(di©żo)Č╚╩¦öĪŻ¼OpenStackų╗╠ß╣®NoValidHostĄ─Õe(cu©░)š`«É│ŻüĒ▒Ē├„ø]ėą┐╔ė├Ą─┘Yį┤Ż¼ė├涤oĘ©═©▀^CLI(novashow$vm_uuid)Ą├ĄĮ╩Ū──éĆ(g©©)filterĄ─╝s╩°Śl╝■įņ│╔š{(di©żo)Č╚╩¦öĪĪŻ
ī”(du©¼)ė┌▓┐╩╩¦öĪŻ¼╣▄└ĒåTąĶę¬SSHĄĮ╩¦öĪĄ─ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)╚źÖz▓ķ╚šųŠ╬─╝■Ęų╬÷╩¦öĪįŁę“
PRS╠ß╣®┴╦troubleshootingreportĮy(t©»ng)ę╗Ą─ęĢłD’@╩Š╠ōöMÖC(j©®)š¹éĆ(g©©)╔·├³ų▄Ų┌(create/migrate/resize/Ą╚)▓┘ū„╩¦öĪĄ─įŁę“╚ńłD5Ż¼╠ōöMÖC(j©®)test_vmį┌Ą┌ę╗┤╬äō(chu©żng)Į©Ą─Ģr(sh©¬)║“ė╔ė┌ø]ėąūŃē“Ą─ėŗ(j©¼)╦Ń┘Yį┤╗“š▀║Ž▀mĄ─ų„ÖC(j©®)Č°╩¦öĪ(“ErrorMessage”▀xĒŚ(xi©żng)ėą╩¦öĪįŁę“Ż¼”DeployedHost”×ķ┐šĄ─┴ą▒Ē)ĪŻė╔troubleshootingreportĄ─“AvailableHosts”▀xĒŚ(xi©żng)┐╔ęįų¬Ą└ŽĄĮy(t©»ng)ųąėą4┼_(t©ói)ų„ÖC(j©®)Ż¼ŠG╔½Ą─ĘĮ┐“▒Ē╩ŠŽĄĮy(t©»ng)ųą├┐ę╗éĆ(g©©)fillterĄ─┘Yį┤ę¬Ū¾║═ØMūŃ┘Yį┤ę¬Ū¾Ą─ų„ÖC(j©®)┴ą▒ĒĪŻūŅĮK▀xō±Ą─ų„ÖC(j©®)æ¬(y©®ng)įō▒╗░³║¼į┌╦∙ėąfilterų„ÖC(j©®)┴ą▒ĒųąĪŻė╔ComputeFilter▀xō±Ą─ų„ÖC(j©®)┴ą▒Ē▓╗░³║¼ų„ÖC(j©®)“my-comp3”Ż¼┐╔ęįĄ├┤╦ų„ÖC(j©®)Ą─nov-computeservice┐╔─▄▒╗ĻP(gu©Īn)ķ]Ż¼ė╔DiskFilterĄ─ų„ÖC(j©®)┴ą▒Ē▓╗░³║¼“my-comp1”║═ų„ÖC(j©®)“my-comp2”┐╔ęįĄ├ų¬▀@ą®ų„ÖC(j©®)Ą─┐╔ė├disk┘Yį┤▓╗ūŃ(<1024MB)Ż¼▓óŪę▀@ā╔éĆ(g©©)filter▀xō±Ą─ų„ÖC(j©®)ø]ėąĮ╗╝»Ż¼ę“┤╦š{(di©żo)Č╚╩¦öĪŻ¼╣▄└ĒåT┐╔ęįĖ∙ō■(j©┤)▀@ą®ą┼Žó─▄├„┤_Ą─ų¬Ą└š{(di©żo)Č╚╩¦öĪĄ─įŁę“Å─Č°▌pęūĄ─┼┼│²Õe(cu©░)š`ĪŻ
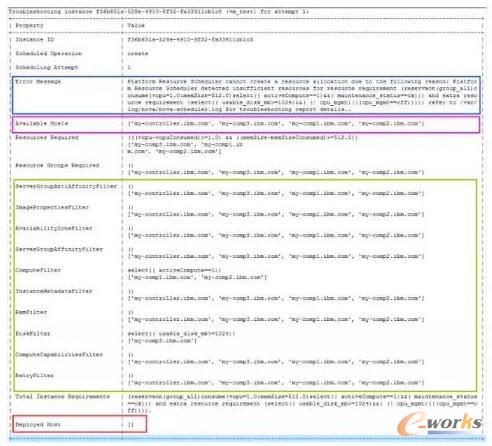
łD5 Trouble Shooting Report
╗∙ė┌═ž?f©┤)õĮY(ji©”)śŗ(g©░u)Ą─š{(di©żo)Č╚
OpenStackHeat╩Ū╠ōöMÖC(j©®)ĮMĄ─ŠÄ┼┼ĮM╝■Ż¼╦³▒Š╔Ēø]ėąš{(di©żo)Č╚─ŻēKŻ¼╦³╗∙ė┌NovaĄ─FilterSchedulerū„×ķš{(di©żo)Č╚Ą─ę²Ūµī”(du©¼)ę╗ĮM╗“ČÓĮM╠ōöMÖC(j©®)▀M(j©¼n)ąąų„ÖC(j©®)╝ē(j©¬)äeĄ─▒ŌŲĮ╗»š{(di©żo)Č╚║═ŠÄ┼┼Ż¼Ą½▀@ĘNš{(di©żo)Č╚─Żą═├┐┤╬ų╗─▄╠Ä└Ēę╗éĆ(g©©)╠ōöMÖC(j©®)šł(q©½ng)Ū¾Ż¼«ö(d©Īng)▓┐╩ČÓéĆ(g©©)╠ōöMÖC(j©®)Ą─Ģr(sh©¬)║“Ż¼╦³▓╗─▄Ė∙ō■(j©┤)┘Yį┤šł(q©½ng)Ū¾▀M(j©¼n)ąąĮy(t©»ng)ę╗Ą─š{(di©żo)Č╚║═╗ž╦▌Ż¼īóĢ■(hu©¼)įņ│╔š{(di©żo)Č╚ĮY(ji©”)╣¹▓╗£╩(zh©│n)┤_ĪŻPRS▓╗Ą½ų¦│ųų„ÖC(j©®)╝ē(j©¬)äeĄ─▒ŌŲĮ╗»š{(di©żo)Č╚Ż¼▀Ćų¦│ųī”(du©¼)ę╗ĮM═¼śŗ(g©░u)╠ōöMÖC(j©®)ā╚(n©©i)▓┐╗“š▀ę╗ĮM╠ōöMÖC(j©®)║═┴Ēę╗ĮM╠ōöMÖC(j©®)į┌ę╗éĆ(g©©)śõą╬═ž?f©┤)õĮY(ji©”)śŗ(g©░u)╔Ž(RegionŻ¼ZoneŻ¼RackŻ¼Host)╔Ž▀M(j©¼n)ąąš¹¾wš{(di©żo)Č╚ĪŻ╗∙ė┌═ž?f©┤)õĮY(ji©”)śŗ(g©░u)Ą─ČÓéĆ(g©©)╠ōöMš¹¾wš{(di©żo)Č╚┐╔ęįĄ├ĄĮę╗ą®’@Č°ęūęŖĄ─║├╠ÄŻ¼▒╚╚ńį┌▓┐╩Ą─Ģr(sh©¬)║“?y©żn)ķ┴╦═žō(f©┤)õĮY(ji©”)śŗ(g©░u)╔Žīė╝ē(j©¬)ų«ķg╗“╠ōöMÖC(j©®)ų«ķg½@Ą├Ė³║├Ą─═©ą┼ąį─▄┐╔ęį▀xō±AffinityĄ─▓▀┬įŻ¼×ķ┴╦½@Ą├═ž?f©┤)õĮY(ji©”)śŗ(g©░u)╔Žīė╝ē(j©¬)ų«ķg╗“╠ōöMÖC(j©®)ų«ķgĄ─Ė▀┐╔ė├ąįŻ¼┐╔ęį▀xō±Anti-Affinity▓▀┬įĪŻPRS═©▀^║═HeatĄ─╔ŅČ╚╝»│╔īŹ(sh©¬)¼F(xi©żn)┴╦╗∙ė┌═ž?f©┤)õĮY(ji©”)śŗ(g©░u)Ą─š¹¾wš{(di©żo)Č╚ĪŻą┬Ą─Heat┘Yį┤ŅÉą═IBMŻ║Ż║PolicyŻ║Ż║Groupė├üĒ├Ķ╩÷▀@ĘNę╗ĮM╗“ČÓĮM╠ōöMÖC(j©®)į┌ę╗éĆ(g©©)śõą╬Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)╔ŽĄ─▓┐╩ąĶŪ¾ĪŻ
AffinityŻ║ė├üĒ├Ķ╩÷ę╗ĮM╠ōöMÖC(j©®)ā╚(n©©i)▓┐Ą─į┌ųĖČ©Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)īė╝ē(j©¬)╔Ž╩ŪAffinityĄ─╗“š▀ę╗ĮM╠ōöMÖC(j©®)║═┴Ēę╗ĮM╠ōöMÖC(j©®)į┌ųĖČ©Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)īė╝ē(j©¬)╔Ž╩ŪAffinityĄ─ĪŻ
Anti-AffinityŻ║ė├üĒ├Ķ╩÷ę╗ĮM╠ōöMÖC(j©®)ā╚(n©©i)▓┐Ą─į┌ųĖČ©Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)īė╝ē(j©¬)╔Ž╩ŪAnti-AffinityĄ─╗“š▀ę╗ĮM╠ōöMÖC(j©®)║═┴Ēę╗ĮM╠ōöMÖC(j©®)į┌ųĖČ©Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)īė╝ē(j©¬)╔Ž╩ŪAnti-AffinityĄ─ĪŻ
MaxResourceLostPerNodeFailureŻ║ė├üĒ├Ķ╩÷«ö(d©Īng)═ž?f©┤)õĮY(ji©”)śŗ(g©░u)ųĖČ©īė╝ē(j©¬)░l(f©Ī)╔·å╬³c(di©Żn)╣╩šŽĢr(sh©¬)Ż¼ė├æ¶Ą─ę╗ĮM╠ōöMÖC(j©®)į┌▀@éĆ(g©©)īė╝ē(j©¬)╔ŽĄ─ōp╩¦┬╩▓╗─▄Ė▀ė┌ę╗éĆ(g©©)ķōųĄĪŻ
░Ė└²1Ż║╚ńłD6Ż¼ė├æ¶Č©┴x┴╦2éĆ(g©©)autoscalinggrouptier1║═tier2Ż¼├┐éĆ(g©©)tierČ╝ąĶę¬2éĆ(g©©)╠ōöMÖC(j©®)Ż¼Ųõųątier1ąĶę¬╠ōöMÖC(j©®)į┌rack╣Ø(ji©”)³c(di©Żn)╔ŽAnti-AffinityŻ¼tier2ąĶę¬╠ōöMÖC(j©®)į┌rack╣Ø(ji©”)³c(di©Żn)╔ŽAffinityŻ¼▓óŪętier1║═tier2╔ŽĄ─╠ōöMÖC(j©®)ų«ķgąĶę¬ØMūŃAffinity.▀@éĆ(g©©)ł÷Š░ŅÉ╦Ųė┌į┌╔·«a(ch©Żn)Łh(hu©ón)Š│╔Ž▓┐╩2ĮMwebapplicationŻ¼ę¬Ū¾▀\(y©┤n)ąądatabaseĄ─╠ōöMÖC(j©®)(tier1)║═▀\(y©┤n)ąąwebĄ─╠ōöMÖC(j©®)(tier2)į┌ŽÓ═¼Ą─ų„ÖC(j©®)╔Ž(ĘĮ▒ŃwebĘ■äš(w©┤)Ų„║═databaseĘ■äš(w©┤)Ų„═©ą┼)Ż¼▓óŪę2éĆ(g©©)▀\(y©┤n)ąądatabaseĄ─╠ōöMÖC(j©®)(tier1)║═2▀\(y©┤n)ąąwebĄ─╠ōöMÖC(j©®)(tier2)▓╗─▄═¼Ģr(sh©¬)▀\(y©┤n)ąąį┌ę╗┼_(t©ói)ų„ÖC(j©®)╔Ž(rack╝ē(j©¬)äe╔ŽAnti-AffinityŻ¼ō·(d©Īn)ą─å╬rackå╬³c(di©Żn)╣╩šŽįņ│╔╦∙ėąĄ─databaseĘ■äš(w©┤)Ų„╗“š▀webĘ■äš(w©┤)Ų„Č╝▓╗┐╔ė├)ĪŻ
łDĄ─ū¾▀ģ╩Ūę╗éĆ(g©©)▓┐╩Ą─ĮY(ji©”)╣¹Ż¼╝t╔½Ą─╠ōöMÖC(j©®)Ą─╩ŪwebĘ■äš(w©┤)Ų„tier1Ż¼³S╔½Ą─╠ōöMÖC(j©®)╩ŪdatabaseĘ■äš(w©┤)Ų„(tier2)Ż¼▀@śėhost1╔ŽĄ─databaseĘ■äš(w©┤)Ų„ų▒Įė×ķhost1╔ŽĄ─webĘ■äš(w©┤)Ų„╠ß╣®Ę■äš(w©┤)Ż¼host6╔ŽĄ─databaseĘ■äš(w©┤)Ų„ų▒Įė×ķhost6╔ŽĄ─webĘ■äš(w©┤)Ų„╠ß╣®Ż¼▓óŪęrack1╗“š▀rack3Ą─å╬³c(di©Żn)╣╩šŽŻ¼▓╗Ģ■(hu©¼)įņ│╔ė├æ¶webĘ■äš(w©┤)Ą─ųąöÓĪŻ
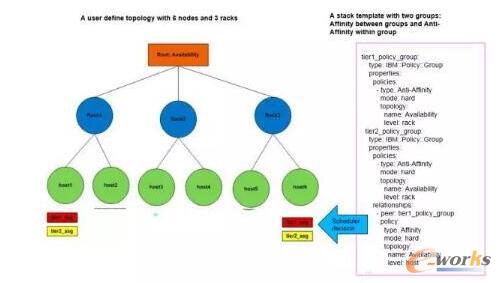
łD6 Affintylanti-Affinity▓▀┬į
░Ė└²2Ż║╚ńłD7Ż¼ė├æ¶Č©┴x┴╦1éĆ(g©©)autoscalinggrouptier1Ż¼▀@éĆ(g©©)tier1ąĶę¬4éĆ(g©©)╠ōöMÖC(j©®)Ż¼ę¬Ū¾«ö(d©Īng)zone░l(f©Ī)╔·å╬³c(di©Żn)╣╩šŽĄ─Ģr(sh©¬)║“Ż¼ė├æ¶Ą─4éĆ(g©©)╠ōöMÖC(j©®)Ą─ōp╩¦┬╩▓╗─▄┤¾ė┌50%ĪŻ▀@éĆ(g©©)ł÷Š░ŅÉ╦Ųė┌į┌╔·«a(ch©Żn)Łh(hu©ón)Š│╔Ž▓┐╩ę╗éĆ(g©©)NginxĘ■äš(w©┤)Ų„╝»╚║Ż¼«ö(d©Īng)░l(f©Ī)╔·╣╩šŽĢr(sh©¬)Ż¼┐éėąę╗░ļĄ─NginxĘ■äš(w©┤)Ų„─▄ē“š²│Ż╣żū„ĪŻłDĄ─ū¾▀ģ╩Ūę╗éĆ(g©©)▓┐╩Ą─ĮY(ji©”)╣¹Ż¼«ö(d©Īng)zon1╗“š▀zone2ųą╚╦╚╬║╬ę╗éĆ(g©©)░l(f©Ī)╔·╣╩šŽŻ¼ė├æ¶Ą─æ¬(y©®ng)ė├│╠ą“ūŅČÓōp╩¦2éĆ(g©©)NginxĘ■äš(w©┤)Ų„Ż¼ØMūŃė├æ¶Ą─śI(y©©)äš(w©┤)ę¬Ū¾Ż¼▀@śėė├æ¶į┌▓┐╩Ą─Ģr(sh©¬)║“Š══©▀^š¹¾wā×(y©Łu)╗»Ą─╠ōöMÖC(j©®)Ę┼ų├▓▀┬įīŹ(sh©¬)¼F(xi©żn)æ¬(y©®ng)ė├│╠ą“Ą─Ė▀┐╔ė├ąįČ°▓╗▒žĄ╚╣Ø(ji©”)³c(di©Żn)╩¦öĪĄ─Ģr(sh©¬)║“═©▀^PRSHA▓▀┬įĄ─▒O(ji©Īn)┐ž▓▀┬į═÷č“ča(b©│)└╬ĪŻ
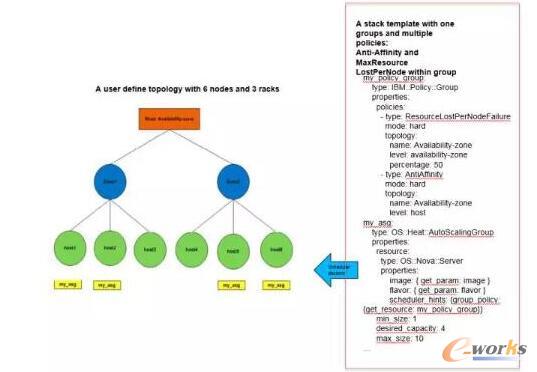
łD7 MaxResourceLostPerNodeFailure▓▀┬į
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.guhuozai8.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║OpenStackįŲČ╦Ą─┘Yį┤š{(di©żo)Č╚║═ā×(y©Łu)╗»Ų╩╬÷
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.guhuozai8.cn/html/consultation/10839719604.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")