ūŅįńĄ─╔╠śI┴ą╩ĮöĄō■Äņ╩Ūį┌1995─Ļ░l▓╝Ą─Sybase IQŻ¼Ą½╩Ūę╗ų▒ĄĮ1999─Ļū¾ėę▓┼┬²┬²ĘĆČ©ĄĮ─▄ē“═Č╚ļ╔·«aŁhŠ│ĪŻ¼Fį┌Ą─┤¾ČÓöĄĘų╬÷ą═öĄō■ÄņČ╝╩Ūį┌2003-2005─ĻÅ─Postgresql Ęųų¦│÷üĒĄ─ĪŻŲõųąė╚Ųõ╩ŪVertica ×ķ┤·▒ĒĄ─┴ąöĄō■ÄņęčĮøį┌┤¾ęÄ─ŻöĄō■é}ÄņŁhŠ│ųąūC├„Ųõ╠žäe×ķöĄō■é}ÄņŁhŠ│įOėŗĄ─╦╝┬Ęį┌ę╗ą®ŅIė“Š▀ėąĖéĀÄā×ä▌ĪŻ▀@Ų¬╬─š┬ĮŌßīĮķĮB┴ą╩ĮöĄō■ÄņĄ─Äū┤¾╠ž³cĪŻ
Ė▀ą¦Ą─ā”┤µ┐šķg└¹ė├┬╩
é„ĮyĄ─ąą╩ĮöĄō■Äņė╔ė┌├┐éĆ┴ąĄ─ķLČ╚▓╗ę╗Ż¼×ķ┴╦ŅAĘ└Ė³ą┬Ą─Ģr║“▓╗ų┴ė┌│÷¼Fę╗ąąöĄō■╠°ĄĮ┴Ēę╗éĆblock ╔Ž╚źŻ¼ ╦∙ęį═∙═∙Ģ■ŅA┴¶ę╗ą®┐šķgĪŻČ°├µŽ“┴ąĄ─öĄō■Äņė╔ė┌ę╗ķ_╩╝Š══Ļ╚½×ķĘų╬÷Č°┤µį┌Ż¼▓╗ąĶę¬┐╝æ]╔┘┴┐Ą─Ė³ą┬å¢Ņ}Ż¼╦∙ęįöĄō■═Ļ╚½╩Ū├▄╝»ā”┤µĄ─ĪŻ
ąą╩ĮöĄō■Äņ×ķ┴╦▒Ē├„ąąĄ─id ═∙═∙Ģ■ėąę╗éĆé╬┴ąrowid Ą─┤µį┌ĪŻ┴ą╩ĮöĄō■Äņę╗░Ń▓╗Ģ■▒Ż┤µrowidĪŻ
┴ą╩ĮöĄō■Äņė╔ė┌Ųõßśī”▓╗═¼┴ąĄ─öĄō■╠žš„Č°░l├„Ą─▓╗═¼╦ŃĘ©╩╣Ųõ═∙═∙ėą▒╚ąą╩ĮöĄō■ÄņĖ▀Ą─ČÓĄ─ē║┐s┬╩Ż¼Ųš═©Ą─ąą╩ĮöĄō■Äņę╗░Ńē║┐s┬╩į┌3Ż║1 ĄĮ5Ż║1 ū¾ėęŻ¼Č°┴ą╩ĮöĄō■ÄņĄ─ē║┐s┬╩ę╗░Ńį┌8Ż║1ĄĮ30Ż║1 ū¾ėęĪŻ(InfoBright į┌╠žäeæ¬ė├┐╔ęį▀_ĄĮ40:1 Ż¼ Vertica į┌╠žäeæ¬ė├┐╔ęį▀_ĄĮ60:1 Ż¼ ę╗░Ń╩Ū▀@├┤Ė▀Ą─ē║┐s┬╩Č╝╩ŪŠWĮj┴„┴┐ŽÓĻPĄ─)
┴ą╩ĮöĄō■Äņė╔ė┌Ųõ╠ž╩ŌĄ─IO ─Żą═╦∙ęįŲõöĄō■ł╠ąąę²Ūµę╗░Ń▓╗ąĶę¬╦„ę²üĒ═Ļ│╔┤¾┴┐Ą─öĄō■▀^×V╚╬äš(Sybase IQ │²═Ō) ĪŻ▀@ėųŅ~═ŌĄ─£p╔┘┴╦öĄō■ā”┤µĄ─┐šķgŽ¹║─ĪŻ
┴ą╩ĮöĄō■Äņ▓╗ąĶę¬╬’╗»ęĢłDŻ¼ąą╩ĮöĄō■Äņ×ķ┴╦£p╔┘IO ę╗░ŃĢ■ėąā╔ĘN╬’╗»ęĢłDŻ¼│Żė├┴ąĄ─▓╗Š█║Ž╬’╗»ęĢłD║═Š█║ŽĄ─╬’╗»ęĢłDĪŻ┴ą╩ĮöĄō■Äņ▒Š╔Ē┴ą╩ŪĘų╔óā”┤µ╦∙ęį▓╗ąĶꬥ┌ę╗ĘNŻ¼Č°ė╔ė┌Ųõ╦¹╠žąį╩╣ŲõśO×ķ▀m║Žū÷Ųš═©Š█║Ž▓┘ū„ĪŻ(┴Ē═Ōę╗ĘN╬’╗»ęĢłD╩Ū▓╗─▄īŹĢr╦óą┬Ą─Ż¼▒╚╚ń┼┼├¹║»öĄŻ¼▓╗ęÄät▀BĮėconnect by Ą╚Ą╚Ż¼▀@▓┐Ęų┴ąöĄō■Äņ▓╗░³└©ĪŻ)
▓╗┐╔ęŖ╦„ę²
┴ą╩ĮöĄō■Äņė╔ė┌ŲõöĄō■Ą─├┐ę╗┴ąČ╝░┤šš▀xō±ąį▀Mąą┼┼ą“Ż¼╦∙ęį▓ó▓╗ąĶꬹą╩ĮöĄō■Äņ└’├µĄ─╦„ę²üĒ£p╔┘IO ║═Ė³┐ņĄ─▓ķšęųĄĄ─Ęų▓╝ŪķørĪŻ╚ńŽ┬łD╦∙╩Š: «ööĄō■Äņł╠ąąę²Ūµ▀Mąąwhere Śl╝■▀^×VĄ─Ģr║“ĪŻų╗ę¬╦³░l¼F╚╬║╬ę╗┴ąĄ─öĄō■▓╗ØMūŃ╠žČ©Śl╝■Ż¼š¹éĆblock Ą─öĄō■Š═Č╝▒╗üGŚēĪŻūŅ║¾│§▓ĮĄ─▀^×Vų╗Ģ■Æ▀├Ķ┐╔─▄ØMūŃŚl╝■Ą─öĄō■ēKĪŻ

(from InfoBright : Blazing Queries Using an Open Source Columnar Database for High Performance Analytics and Reporting )
┴Ē═Ōį┌ęčĮøūx╚Ī┴╦┐╔─▄Ą─öĄō■ēKų«║¾Ż¼ī”ė┌ŅÉ╦Ųage < 65 ╗“ job = ‘Axx’ Ą─Ż¼┴ą╩ĮöĄō■Äņ▓ó▓╗ąĶę¬Æ▀├Ķ═Ļš¹éĆblockŻ¼ę“×ķöĄō■ęčĮø┼┼ą“┴╦ĪŻ╚ń╣¹ūxĄĮĄ┌ę╗éĆage=66 ╗“š▀ Job = ‘Bxx’ Ą─Ģr║“Š═Ģ■═Żų╣Æ▀├Ķ┴╦ĪŻ▀@ŽÓ«ö┼cąą╩ĮöĄō■Äņ╦„ę²└’Ą─ĘČć·Æ▀├ĶĪŻ
öĄō■Ą³┤· (Tuple Iteration)
¼Fį┌Ą─ČÓ║╦CPU ╠ß╣®Ą─L2 ŠÅ┤µį┌Č╠Ģrķgł╠ąą═¼ę╗éĆ║»öĄ║▄ČÓ┤╬Ą─Ģr║“─▄Ė³║├Ą─└¹ė├CPU Ą─Č■╝ēŠÅ┤µ║═ČÓ║╦▓ó░lĄ─╠žąįĪŻČ°ąą╩ĮöĄō■Äņė╔ė┌ŲõöĄō■╗ņį┌ę╗Ųø]Ę©ī”ę╗éĆöĄĮM▀Mąą═¼ę╗éĆ║åå╬║»öĄĄ─š{ė├Ż¼╦∙ęįŲõł╠ąąą¦┬╩ø]ėą┴ą╩ĮöĄō■ÄņĖ▀ĪŻ
ē║┐s╦ŃĘ©
┴ą╩ĮöĄō■Äņė╔ė┌Ųõ├┐ę╗┴ąČ╝╩ŪĘųķ_ā”┤µĄ─ĪŻ╦∙ęį║▄╚▌ęūßśī”├┐ę╗┴ąĄ─╠žš„▀\ė├▓╗═¼Ą─ē║┐s╦ŃĘ©ĪŻ│ŻęŖĄ─┴ą╩ĮöĄō■Äņē║┐s╦ŃĘ©ėąRun Length Encoding Ż¼ Data Dictionary Ż¼ Delta Compression Ż¼ BitMap Index Ż¼ LZO Ż¼ Null Compression Ą╚Ą╚ĪŻĖ∙ō■▓╗═¼Ą─╠žš„▀MąąĄ─ē║┐są¦┬╩Å─10W:1 ĄĮ10:1 ▓╗Ą╚ĪŻČ°ŪęöĄō■įĮ┤¾Ųõē║┐są¦┬╩Ą─╠ß╔²įĮ×ķ├„’@ĪŻ
čė▀t╬’╗»
┴ą╩ĮöĄō■Äņė╔ė┌Ųõ╠ž╩ŌĄ─ł╠ąąę²ŪµŻ¼į┌öĄō■ųąķg▀^│╠▀\╦ŃĄ─Ģr║“ę╗░Ń▓╗ąĶę¬ĮŌē║öĄō■Č°╩ŪęįųĖßś┤·╠µ▀\╦ŃŻ¼ų▒ĄĮūŅ║¾ąĶę¬▌ö│÷═Ļš¹Ą─öĄō■ĢrĪŻ
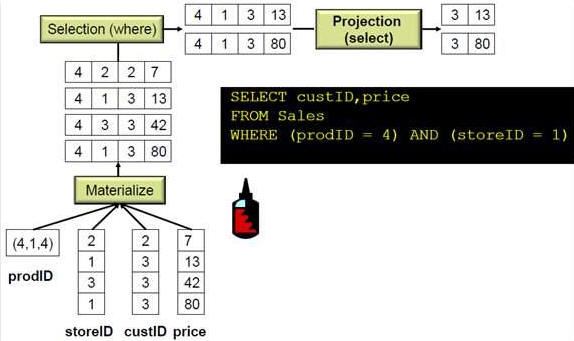
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)
é„ĮyĄ─ąą╩ĮöĄō■Äņ▀\╦ŃŻ¼ į┌▀\╦ŃĄ─ę╗ķ_╩╝Š═ĮŌē║┐s╦∙ėąöĄō■Ż¼╚╗║¾ł╠ąą║¾├µĄ─▀^×VŻ¼═Čė░Ż¼▀BĮėŻ¼Š█║Ž▓┘ū„
Č°┴ą╩ĮöĄō■ÄņĄ─ł╠ąąėŗäØģs╩Ū▀@śėĄ─ĪŻ
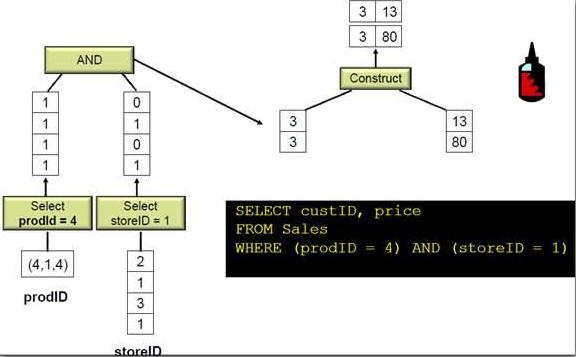
(from McKnight : Columnar Database : Data Does the Twist and Analytics Shout)
į┌š¹éĆėŗ╦Ń▀^│╠ųąŻ¼ ¤ošō▀^×VŻ¼═Čė░Ż¼▀BĮėŻ¼Š█║Ž▓┘ū„Ż¼┴ą╩ĮöĄō■ÄņČ╝▓╗ĮŌē║öĄō■ų▒ĄĮūŅ║¾öĄō■▓┼▀ĆįŁįŁ╩╝öĄō■ųĄĪŻ▀@śėū÷Ą─║├╠Äėą£p╔┘CPU Ž¹║─Ż¼£p╔┘ā╚┤µŽ¹║─Ż¼£p╔┘ŠWĮjé„▌öŽ¹║─Ż¼£p╔┘ūŅ║¾ā”┤µĄ─ąĶę¬ĪŻ
┴ą╩ĮöĄō■Äņā×╚▒³c
┴ą╩ĮöĄō■ÄņÅ─ę╗ķ_╩╝Š═╩Ū├µŽ“┤¾öĄō■ŁhŠ│Ž┬öĄō■é}ÄņĄ─öĄō■Ęų╬÷Č°«a╔·Ż¼╦³Ė·ąą╩ĮöĄō■ÄņŽÓ▒╚«ö╚╗ę▓ėąę╗ą®Ū░╠ߌl╝■║═ā×╚▒³cĪŻ
┴ą╩ĮöĄō■Äņā׳cŻ║
·śOĖ▀Ą─čb▌d╦┘Č╚ (ūŅĖ▀┐╔ęįĄ╚ė┌╦∙ėąė▓▒PIO Ą─┐é║═Ż¼╗∙▒Š╩ŪśOŽ▐┴╦)
·▀m║Ž┤¾┴┐Ą─öĄō■Č°▓╗╩ŪąĪöĄō■
·īŹĢr╝ė▌döĄō■āHŽ▐ė┌į÷╝ė(äh│²║═Ė³ą┬ąĶę¬ĮŌē║┐sBlock ╚╗║¾ėŗ╦Ń╚╗║¾ųžą┬ē║┐sā”┤µ)
·Ė▀ą¦Ą─ē║┐s┬╩Ż¼▓╗āH╣Ø╩Īā”┤µ┐šķgę▓╣Ø╩Īėŗ╦Ńā╚┤µ║═CPUĪŻ
·ĘŪ│Ż▀m║Žū÷Š█║Ž▓┘ū„ĪŻ
╚▒³cŻ║
·▓╗▀m║ŽÆ▀├ĶąĪ┴┐öĄō■
·▓╗▀m║ŽļSÖCĄ─Ė³ą┬
·┼·┴┐Ė³ą┬ŪķørĖ„«ÉŻ¼ėąĄ─ā×╗»Ą─▒╚▌^║├Ą─┴ą╩ĮöĄō■Äņ(▒╚╚ńVertica)▒Ē¼F▒╚▌^║├Ż¼ėąą®ø]ėąßśī”Ė³ą┬Ą─öĄō■Äņ▒Ē¼F▒╚▌^▓ŅĪŻ
·▓╗▀m║Žū÷║¼ėąäh│²║═Ė³ą┬Ą─īŹĢr▓┘ū„ĪŻ
│ŻęŖš`ģ^
ę╗éĆ│ŻęŖĄ─š`ģ^šJ×ķ╚ń╣¹├┐┤╬Æ▀├Ķ▌^ČÓąą╗“š▀╚½┴ą╚½▒ĒÆ▀├ĶĄ─Ģr║“Ż¼ąą╩ĮöĄō■Äņ▒╚┴ą╩ĮöĄō■ÄņĖ³ėąā×ä▌ĪŻ╩┬īŹ╔Ž▀@ų╗╩Ūąą╩ĮöĄō■ÄņšJūR╔ŽĄ─ę╗éĆš`ģ^Ż¼╝┤šJ×ķ┴ą╩ĮöĄō■ÄņĄ─ų„ę¬ā×ä▌į┌ė┌Ųõ┴ąĘųķ_ā”┤µŻ¼Č°║÷┬į┴╦┴ą╩ĮöĄō■Äņ╔Ž├µ╠ߥĮĄ─Ųõ╦¹Äū┤¾╠žš„Ż¼▀@éĆ▓┼╩Ū┴ą╩ĮöĄō■ÄņĖ▀ąį─▄Ą─║╦ą─ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║£\╬÷┴ą╩ĮöĄō■ÄņĄ─╠ž³c
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/1083936334.html