×ķų¦│ų│¼┤¾ŠSČ╚ÖCŲ„īW┴Ģ─Żą═▀\╦ŃŻ¼“vėŹöĄō■ŲĮ┼_▓┐┼cŽŃĖ█┐Ų╝╝┤¾īW║Žū„ķ_░l┴╦├µŽ“ÖCŲ„īW┴ĢĄ─Ęų▓╝╩Įėŗ╦Ń┐“╝▄——Angel 1.0ĪŻ
Angel╩Ū╩╣ė├JavašZčįķ_░lĄ─īŻėąÖCŲ„īW┴Ģėŗ╦ŃŽĄĮyŻ¼ė├æ¶┐╔ęįŽ±ė├SparkŻ¼ MapReduceę╗śėŻ¼ė├╦³üĒ═Ļ│╔ÖCŲ„īW┴ĢĄ──Żą═ė¢ŠÜĪŻAngelęčĮøų¦│ų┴╦SGDĪóADMMā×╗»╦ŃĘ©Ż¼═¼Ģr╬ęéāę▓╠ß╣®┴╦ę╗ą®│Żė├Ą─ÖCŲ„īW┴Ģ─Żą═Ż╗Ą½╩Ū╚ń╣¹ė├æ¶ėąūįČ©┴xąĶŪ¾Ż¼ę▓┐╔ęįį┌╬ęéā╠ß╣®Ą─ūŅā×╗»╦ŃĘ©╔Žīė▒╚▌^╚▌ęūĄžĘŌčb─Żą═ĪŻ
Angelæ¬ė├ŽŃĖ█┐Ų╝╝┤¾īWĄ─Chukonu ū„×ķŠWĮjĮŌøQĘĮ░ĖŻ¼ į┌Ė▀ŠSČ╚ÖCŲ„īW┴ĢĄ─ģóöĄĖ³ą┬▀^│╠ųąŻ¼ėąßśī”ąįĄžĮo£■║¾Ą─ėŗ╦Ń╚╬䚥─ģóöĄé„▀f╠ß╦┘Ż¼š¹¾w╔Ž┐sČ╠ÖCŲ„īW┴Ģ╦ŃĘ©Ą─▀\╦ŃĢrķgĪŻ▀@ę╗äōą┬▓╔ė├┴╦ŽŃĖ█┐Ų╝╝┤¾īWĻÉäPĮ╠╩┌╝░Ųõ蹊┐ąĪĮMķ_░lĄ─┐╔Ėąų¬╔Žīėæ¬ė├Ż©Application-awareŻ®Ą─ŠWĮjā×╗»ĘĮ░ĖŻ¼ęį╝░ŚŅÅŖĮ╠╩┌ŅIī¦Ą─Ą─┤¾ęÄ─ŻÖCŲ„īW┴Ģ蹊┐ĘĮ░ĖĪŻ
┴Ē═ŌŻ¼▒▒Š®┤¾īW┤▐▒¾Į╠╩┌╝░ŲõīW╔·ę▓╣▓═¼ģó┼c┴╦AngelĒŚ─┐Ą─čą░lĪŻ
į┌īŹļHĄ─╔·«a╚╬äšųąŻ¼Angelį┌Ū¦╚f╝ēĄĮā|╝ēĄ─╠žš„ŠĢČ╚Śl╝■Ž┬▀\ąąSGDŻ¼ąį─▄╩Ū│╔╩ņĄ─ķ_į┤ŽĄĮySparkĄ─öĄ▒ČĄĮöĄ╩«▒Č▓╗Ą╚ĪŻAngelęčĮøį┌“vėŹęĢŅl═Ų╦]ĪóÅV³c═©Ą╚Š½£╩═Ų╦]śIäš╔ŽīŹļHæ¬ė├Ż¼─┐Ū░╬ęéāš²į┌öU┤¾į┌“vėŹā╚▓┐Ą─æ¬ė├ĘČć·Ż¼─┐ś╦╩Ūų¦│ų“vėŹĄ╚Ų¾śI╝ē┤¾ęÄ─ŻÖCŲ„īW┴Ģ╚╬äšĪŻ
š¹¾w╝▄śŗ
Angelį┌š¹¾w╝▄śŗ╔Žģó┐╝┴╦╣╚ĖĶĄ─DistBeliefĪŻDistBeilefūŅ│§╩Ū×ķ╔ŅČ╚īW┴ĢČ°įOėŗŻ¼╦³╩╣ė├┴╦ģóöĄĘ■äšŲ„Ż¼ęįĮŌøQŠ▐┤¾─Żą═į┌ė¢ŠÜĢrĄ─Ė³ą┬å¢Ņ}ĪŻģóöĄĘ■äšŲ„═¼śė┐╔ė├ė┌ÖCŲ„īW┴ĢųąĘŪ╔ŅČ╚īW┴ĢĄ──Żą═Ż¼╚ńSGDĪóADMMĪóLBFGSĄ─ā×╗»╦ŃĘ©į┌├µ┼Rį┌├┐▌åĄ³┤·╔Žā|éĆģóöĄĖ³ą┬Ą─ł÷Š░ųąŻ¼ąĶę¬ģóöĄĘų▓╝╩ĮŠÅ┤µüĒ═žš╣ąį─▄ĪŻAngelį┌▀\╦Ńųąų¦│ųBSPĪóSSPĪóASP╚²ĘNėŗ╦Ń─Żą═Ż¼ŲõųąSSP╩Ūė╔┐©─═╗∙├Ę┬Ī┤¾īWEricXingį┌PetuumĒŚ─┐ųą“×ūCĄ─ėŗ╦Ń─Żą═Ż¼─▄į┌ÖCŲ„īW┴ĢĄ─▀@ĘN╠žČ©▀\╦Ńł÷Š░Ž┬╠ß╔²┐sČ╠╩šö┐ĢrķgĪŻŽĄĮyėą╬ÕéĆĮŪ╔½Ż║
MasterŻ║žōž¤┘Yį┤╔Ļšł║═Ęų┼õŻ¼ęį╝░╚╬䚥─╣▄└ĒĪŻ
TaskŻ║žōž¤╚╬䚥─ł╠ąąŻ¼ęįŠĆ│╠Ą─ą╬╩Į┤µį┌ĪŻ
WorkerŻ║¬Ü┴ó▀M│╠▀\ąąė┌YarnĄ─ContainerųąŻ¼╩ŪTaskĄ─ł╠ąą╚▌Ų„ĪŻ
ParameterServerŻ║ļSų°ę╗éĆ╚╬䚥─åóäėČ°╔·│╔Ż¼╚╬äšĮY╩°Č°õNܦŻ¼žōž¤į┌įō╚╬äšė¢ŠÜ▀^│╠ųąĄ─ģóöĄĄ─Ė³ą┬║═┤µā”ĪŻ
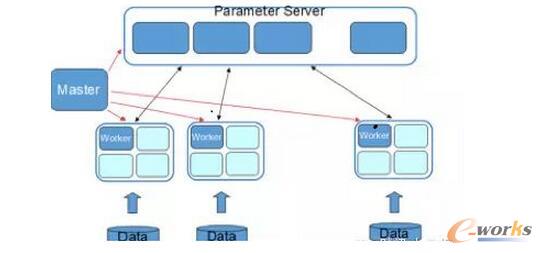
łD1 ParameterServer
WorkerGroup×ķę╗éĆ╠ōöMĖ┼─ŅŻ¼ė╔╚¶Ė╔éĆWorkerĮM│╔Ż¼į¬öĄō■ė╔MasterŠSūoĪŻ×ķ─Żą═▓óąą═žš╣Č°┐╝æ]Ż¼į┌ę╗éĆWorkerGroupā╚╦∙ėąWorker▀\ąąĄ─ė¢ŠÜöĄō■Č╝╩Ūę╗śėĄ─ĪŻļm╚╗╬ęéā╠ß╣®┴╦ę╗ą®═©ė├─Żą═Ż¼Ą½▓ó▓╗▒ŻūCČ╝ØMūŃąĶŪ¾Ż¼Č°ė├æ¶ūįČ©┴xĄ──Żą═īŹ¼F┐╔ęįīŹ¼F╬ęéāĄ─═©ė├Įė┐┌Ż¼ą╬╩Į╔ŽĄ╚═¼ė┌MapReduce╗“SparkĪŻ
1Ż®ė├æ¶ėč║├
1. ūįäė╗»öĄō■ŪąĘųŻ║ AngelŽĄĮy×ķė├æ¶╠ß╣®┴╦ūįäėŪąĘųė¢ŠÜöĄō■Ą─╣”─▄Ż¼ĘĮ▒Ńė├æ¶▀MąąöĄō■▓óąą▀\╦ŃŻ║ŽĄĮy─¼šJ╝µ╚▌┴╦Hadoop FSĮė┐┌Ż¼įŁ╩╝ė¢ŠÜśė▒Š┤µā”į┌ų¦│ųHadoop FSĮė┐┌Ą─Ęų▓╝╩Į╬─╝■ŽĄĮy╚ńHDFSĪóTachyonĪŻ
2. žSĖ╗Ą─öĄō■╣▄└ĒŻ║śė▒ŠöĄō■┤µā”į┌Ęų▓╝╩Į╬─╝■ŽĄĮyųąŻ¼ŽĄĮyį┌ėŗ╦ŃŪ░Å─╬─╝■ŽĄĮyūx╚ĪĄĮėŗ╦Ń▀M│╠Ż¼Ę┼į┌ŠÅ┤µį┌ā╚┤µųąęį╝ė╦┘Ą³┤·▀\╦ŃŻ╗╚ń╣¹ā╚┤µųąŠÅ┤µ▓╗Ž┬Ą─öĄō■ätĢ║┤µĄĮ▒ŠĄž┤┼▒PŻ¼▓╗ąĶꬎ“Ęų▓╝╩Į╬─╝■ŽĄĮyį┘┤╬░lŲ═©ėŹšłŪ¾ĪŻ
3. žSĖ╗Ą─ŠĆąį┤·öĄ╝░ā×╗»╦ŃĘ©ÄņŻ║ AngelĖ³╠ß╣®┴╦Ė▀ą¦Ą─Ž“┴┐╝░ŠžĻć▀\╦ŃÄņŻ©ŽĪ╩Ķ/│Ē├▄Ż®Ż¼ĘĮ▒Ń┴╦ė├æ¶ūįė╔▀xō±öĄō■ĪóģóöĄĄ─▒Ē▀_ą╬╩ĮĪŻį┌ā×╗»╦ŃĘ©ĘĮ├µŻ¼AngelęčīŹ¼F┴╦SGDĪóADMMŻ╗─Żą═ĘĮ├µŻ¼ų¦│ų┴╦Latent DirichletAllocation (LDA)ĪóMatrixFactorization (MF)ĪóLogisticRegression (LR) ĪóSupport Vector Machine(SVM) Ą╚ĪŻ
4. ┐╔▀xō±Ą─ėŗ╦Ń─Żą═Ż║ ŠC╩÷ųą╬ęéā╠ߥĮ┴╦Ż¼AngelĄ─ģóöĄĘ■äšŲ„┐╔ęįų¦│ųBSPŻ¼SSPŻ¼ASPėŗ╦Ń─Żą═ĪŻ
5. Ė³╝Ü┴ŻČ╚Ą─╚▌ÕeŻ║ į┌ŽĄĮyųą╚▌Õeų„ę¬Ęų×ķMasterĄ─╚▌ÕeŻ¼ģóöĄĘ■äšŲ„Ą─╚▌×─Ż¼Worker▀M│╠ā╚Ą─ģóöĄ┐ņššĄ─ŠÅ┤µŻ¼RPCš{ė├Ą─╚▌ÕeĪŻ
6. ėč║├Ą─╚╬äš▀\ąą╝░▒O┐žŻ║ Angelę▓Š▀ėąėč║├Ą─╚╬äš▀\ąąĘĮ╩ĮŻ¼ų¦│ų╗∙ė┌YarnĄ─╚╬äš▀\ąą─Ż╩ĮĪŻ═¼ĢrŻ¼AngelĄ─Web AppĒō├µę▓ĘĮ▒Ń┴╦ė├æ¶▓ķ┐┤╝»╚║▀MČ╚ĪŻ
2Ż®ģóöĄĘ■äšŲ„
į┌īŹļHĄ─╔·«aŁhŠ│ųąŻ¼┐╔ęįų▒ė^Ą─Ėą╩▄ĄĮSparkĄ─Driverå╬³cĖ³ą┬ģóöĄ║═ÅV▓źĄ─Ų┐ŅiŻ¼ļm╚╗┐╔ęį═©▀^ŠĆąį═žš╣üĒ£p╔┘ėŗ╦ŃĢrĄ─║─ĢrŻ¼Ą½╩ŪĦüĒ┴╦╩šö┐ąįŽ┬ĮĄĄ─å¢Ņ}Ż¼═¼ĢrĖ³ć└ųžĄ─╩Ūį┌öĄō■▓󹹥─▀\╦Ń▀^│╠ųąŻ¼ė╔ė┌├┐éĆExecutorČ╝▒Ż│ųę╗éĆ═Ļš¹Ą─ģóöĄ┐ņššŻ¼ŠĆąį═žš╣ĦüĒ┴╦N x ģóöĄ┐ņššĄ─┴„┴┐Ż¼Č°▀@éĆ┴„┴┐╝»ųąĄĮ┴╦Driverę╗éĆ╣سc╔ŽŻĪ
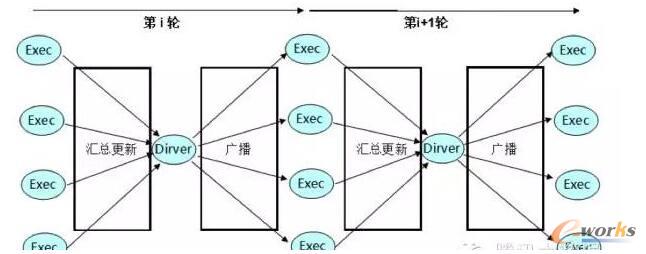
łD2 SparkĄ─Driverå╬³cĖ³ą┬ģóöĄ║═ÅV▓ź
Å─łDųą┐┤ĄĮŻ¼į┌ÖCŲ„īW┴Ģ╚╬äšųąŻ¼Spark╝┤╩╣ėąĖ³ČÓĄ─ÖCŲ„┘Yį┤ę▓¤oĘ©└¹ė├Ż¼ÖCŲ„ų╗į┌╠žČ©▌^╔┘Ą─ęÄ─ŻŽ┬▓┼─▄░lō]ūŅ╝čąį─▄Ż¼Ą½╩Ū▀@éĆūŅ╝čąį─▄ŲõīŹę▓▓ó▓╗└ĒŽļĪŻ
▓╔ė├ģóöĄĘ■äšŲ„ĘĮ░ĖŻ¼╬ęéā┼cSparkū÷┴╦╚ńŽ┬▒╚▌^Ż║į┌ėą5000╚fŚlė¢ŠÜśė▒ŠĄ─öĄō■╝»╔ŽŻ¼▓╔ė├SGDĮŌĄ─▀ē▌ŗ╗žÜw─Żą═Ż¼╩╣ė├10éĆ╣żū„╣سc(Worker)Ż¼ßśī”▓╗═¼ŠSČ╚Ą─╠žš„ųę╗▀Mąą┴╦├┐▌åĄ³┤·Ģrķg║═š¹¾w╩šö┐ĢrķgĄ─▒╚▌^Ż©▀@└’Angel╩╣ė├Ą─╩ŪBSP─Ż╩ĮŻ®ĪŻ
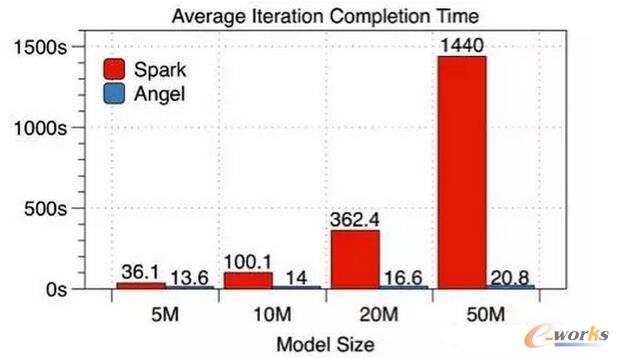
łD3 Average lteration Completion Time
═©▀^öĄō■┐╔ęŖŻ¼─Żą═įĮ┤¾Angelī”▒╚SparkĄ─ā×ä▌Š═įĮ├„’@ĪŻ
3Ż®ā╚┤µā×╗»
į┌▀\╦Ń▀^│╠ųą×ķ£p╔┘ā╚┤µŽ¹║─║═╠ß╔²å╬▀M│╠ā╚▀\╦Ń╩šö┐ąį╩╣ė├┴╦«É▓Į¤oµiĄ─Hogwild! ─Ż╩ĮĪŻ═¼ę╗éĆ▀\╦Ń▀M│╠ųąĄ─NéĆTask╚ń╣¹į┌▀\╦ŃųąČ╝Ė„ūį▒Ż│ųę╗éƬÜ┴óĄ─ģóöĄ┐ņššŻ¼ī”ģóöĄĄ─ā╚┤µķ_õNŠ═N▒ČŻ¼─Żą═ŠSČ╚įĮ┤¾ĢrŽ¹║─įĮ├„’@ŻĪSGDĄ─ā×╗»╦ŃĘ©ųąŻ¼īŹļHł÷Š░ųąŻ¼ė¢ŠÜöĄō■Į^┤¾ČÓöĄŪķørŽ┬╩ŪŽĪ╩ĶĄ─Ż¼ę“┤╦ģóöĄĖ³ą┬ø_═╗Ą─Ė┼┬╩Š═┤¾┤¾ĮĄĄ═┴╦Ż¼╝┤▒Ńø_═╗┴╦╠▌Č╚ę▓▓╗═Ļ╚½╩Ū═∙▓ŅĄ─ĘĮŽ“░lš╣Ż¼«ģŠ╣Č╝╩Ū│»ų°╠▌Č╚Ž┬ĮĄĄ─ĘĮŽ“Ė³ą┬Ą─ĪŻ╬ęéā╩╣ė├┴╦Hogwild!─Ż╩Įų«║¾Ż¼ūīČÓéĆTaskį┌ę╗éĆ▀M│╠ā╚╣▓ŽĒ═¼ę╗éĆģóöĄ┐ņššŻ¼£p╔┘ā╚┤µŽ¹║─▓ó╠ß╔²┴╦╩šö┐╦┘Č╚ĪŻ
4Ż®ŠWĮjā×╗»
╬ęéāėąā╔éĆų„ę¬ā×╗»³cŻ║
1Ż®▀M│╠ā╚Ą─Task▀\╦Ńų«║¾Ą─ģóöĄĖ³ą┬║Ž▓óų«║¾ŲĮ╗¼Ą─═Ų╦═ĄĮģóöĄĘ■äšŲ„Ė³ą┬Ż¼▀@£p╔┘┴╦Task╦∙į┌ÖCŲ„Ą─╔ŽąąŽ¹║─Ż¼ę▓£p╔┘┴╦ģóöĄĘ■äšŲ„Ą─Ž┬ąąŽ¹║─Ż¼═¼Ģr£p╔┘į┌═Ų╦═Ė³ą┬Ą─▀^│╠ųąĄ─ĘÕųĄŲ┐Ņi┤╬öĄŻ╗
2Ż®ßśī”SSP▀MąąĖ³╔Ņę╗▓ĮĄ─ŠWĮjā×╗»Ż║ė╔ė┌SSP╩Ūę╗ĘN░ļ═¼▓ĮĄ─▀\╦Ńģfš{ÖCųŲŻ¼į┌ėąŽ▐Ą─┤░┐┌▀\ąąė¢ŠÜŻ¼┐ņĄ─╣سc▀_ĄĮ┤░┐┌▀ģŠēĢrŻ¼╚╬䚊═▒žĒÜ═ŻŽ┬üĒĄ╚┤²ūŅ┬²Ą─╣سcĖ³ą┬ūŅą┬Ą─ģóöĄĪŻßśī”▀@ę╗å¢Ņ}Ż¼╬ęéā═©▀^ŠWĮj┴„┴┐Ą─į┘Ęų┼õüĒ╝ė╦┘▌^┬²Ą─╣żū„╣سcĪŻ╬ęéāĮo▌^┬²Ą─╣سcęįĖ³Ė▀Ą─ĦīÆŻ╗ŽÓæ¬Ą─Ż¼┐ņĄ─╣żū„╣سcŠ═ĘųĄ├Ė³╔┘Ą─ĦīÆĪŻ▀@śėę╗üĒŻ¼┐ņĄ─╣سc║═┬²Ą─╣سcĄ─Ą³┤·┤╬öĄĄ─▓ŅŠÓŠ═Ą├ęį┐žųŲŻ¼£p╔┘┴╦┤░┐┌▒╗═╗ŲŲŻ©░l╔·Ą╚┤²Ż®Ą─Ė┼┬╩Ż¼ę▓Š═╩Ū£p╔┘┴╦╣żū„╣سcė╔ė┌SSP┤░┐┌Č°┐šķeĄ╚┤²ĢrķgĪŻ
╚ńŽ┬łD╦∙╩ŠŻ¼į┌1ā|ŠSČ╚ĪóĄ³┤·30▌åĄ─ą¦╣¹įu£yųąŻ¼┐╔ęį┐┤ĄĮChukonu╩╣Ą├└█ĘeĄ─┐šķeĄ╚┤²Ģrķg┤¾Ę∙Č╚£p╔┘Ż¼▀_3.79▒ČĪŻ
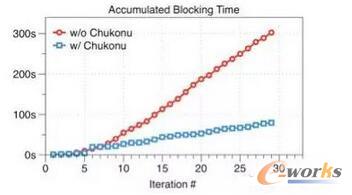
łD4 Chukonu╩╣Ą├└█ĘeĄ─┐šķeĄ╚┤²Ģrķg
Ž┬łDš╣╩ŠĄ─╩Ūā×╗»Ū░║¾Ą─ł╠ąąĢrķgŻ¼ęį5000╚fŠSČ╚Ą──Żą═×ķ└²Ż¼20éĆ╣żū„╣سc║═10éĆģóöĄĘ■äšŲ„Ż¼Staleness=5Ż¼ł╠ąą30▌åĄ³┤·ĪŻ┐╔ęį┐┤│÷Ż¼ķ_åóChukonu║¾ŲĮŠ∙├┐▌åĄ─═Ļ│╔Ģrķgų╗ąĶ7.97├ļŻ¼ŽÓ▒╚ė┌▒╚įŁ╩╝Ą─╚╬äšŲĮŠ∙├┐▌å9.2├ļėą┴╦15%Ą─╠ß╔²ĪŻ
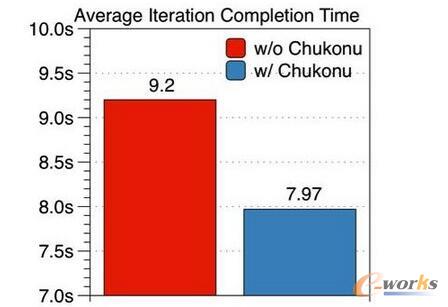
łD5 ā×╗»Ū░║¾Ą─ł╠ąąĢrķg
┴Ē═ŌŻ¼ßśī”ąį╝ė╦┘┬²Ą─╣سc┐╔ęį╩╣┬²Ą─╣سcĖ³┤¾┐╔─▄Ą─½@Ą├ūŅą┬Ą─ģóöĄŻ¼ę“┤╦ī”▒╚įŁ╩╝Ą─SSPėŗ╦Ń─Żą═Ż¼╦ŃĘ©╩šö┐ąįĄ├ĄĮ┴╦╠ß╔²ĪŻŽ┬łD╦∙╩ŠŻ¼═¼śė╩Ūßśī”╬ÕŪ¦╚fŠSČ╚Ą──Żą═į┌SSPŽ┬Ą─ą¦╣¹įu£yŻ¼įŁ╔·Ą─Angel╚╬äšį┌30▌åĄ³┤·║¾Ż©276├ļŻ®loss▀_ĄĮ┴╦0.0697Ż¼Č°ķ_åó┴╦Chukonu║¾Ż¼į┌Ą┌19▌åĄ³┤·Ż©145├ļŻ®Š═ęč▀_ĄĮĖ³Ą═Ą─lossĪŻÅ─▀@ĘN╠žČ©ł÷Š░üĒ┐┤ėąę╗éĆĮėĮ³90%Ą─╩šö┐╦┘Č╚╠ß╔²ĪŻ
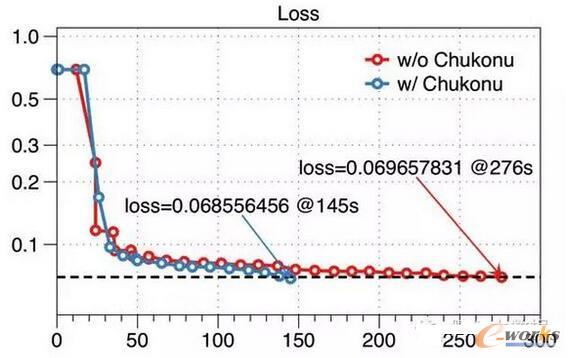
łD6 ĮėĮ³90%Ą─╩šö┐╦┘Č╚
║¾└mėŗäØ
╬┤üĒŻ¼ĒŚ─┐ĮMīóöU┤¾æ¬ė├Ą─ęÄ─ŻŻ¼═¼ĢrŻ¼ĒŚ─┐ĮMęčĮøį┌└^└mčą░lAngelĄ─Ž┬ę╗░µ▒ŠŻ¼Ž┬ę╗éĆ░µ▒ŠĢ■į┌─Żą═▓óąąĘĮ├µū÷ę╗ą®╔Ņ╚ļĄ─ā×╗»ĪŻ┴Ē═ŌŻ¼ĒŚ─┐ĮMš²į┌ėŗäØ░čAngel▀Mąąķ_į┤Ż¼╬ęéāĢ■į┌║¾└m║Ž▀mĄ─ĢrÖC▀Mąą╣½ķ_ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╠¢═ŌŻĪ ┤¾ŠSČ╚ÖCŲ„īW┴Ģę▓ėąėŗ╦Ń┐“╝▄┴╦
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839719855.html