║┴¤oę╔å¢Ż¼ū„×ķ╚╦╣żųŪ─▄Ą─ūėŅIė“—ÖCŲ„īW┴Ģį┌▀^╚źĄ─Äū─ĻųąįĮüĒįĮ╩▄ÜgėŁĪŻė╔ė┌┤¾öĄō■╩Ū─┐Ū░┐Ų╝╝ąąśIūŅ¤ßķTĄ─┌ģä▌Ż¼╗∙ė┌┤¾┴┐Ą─öĄō■ÖCŲ„īW┴Ģį┌╠ßŪ░ŅA£y║═ū÷│÷Į©ūhĘĮ├µėąŠ▐┤¾Ą─Øō┴”ĪŻę╗ą®ėąĻPÖCŲ„īW┴Ģ│ŻęŖĄ─└²ūėėąŻ║Netflix╗∙ė┌─ŃęįŪ░┐┤▀^Ą─ļŖė░į┘Įo─Ńū÷│÷ė░Ų¼Ą─═Ų╦]Ż¼╗“š▀üå±R▀dĖ∙ō■─ŃęįŪ░┘I▀^Ą─Ģ°╝«į┘Įo─Ń▀MąąłDĢ°═Ų╦]ĪŻ
╚ń╣¹Žļ┴╦ĮŌĖ³ČÓėąĻPÖCŲ„īW┴ĢĄ─ų¬ūRŻ¼ę¬Å───└’ķ_╩╝─žŻ┐ū„š▀Ą┌ę╗┤╬╚ļķT╩Ūį┌Ėń▒Š╣■Ė∙║Ż═ŌĮ╗┴„Ģr▀x┴╦ę╗ķTėąĻP╚╦╣żųŪ─▄Ą─šn│╠ĪŻ▀@ķTšn│╠Ą─ųvĤ╩ŪĄż¹£┐Ų╝╝┤¾īW(Technical University of Denmark)Ą─æ¬ė├öĄīWęį╝░ėŗ╦ŃÖC┐ŲīW╚½┬ÜĮ╠╩┌Ż¼╦¹Ą─蹊┐ŅIė“ų„ę¬╩Ū▀ē▌ŗīW║═╚╦╣żųŪ─▄ĘĮ├µŻ¼ų„ę¬čąŠ┐ā╚╚▌╩Ū╩╣ė├▀ē▌ŗüĒī”ėŗ╦ŃÖCŅÉ╚╦ąą×ķ(▒╚╚ńėŗäØĪó═Ų└Ēęį╝░å¢Ņ}ĮŌøQĄ╚)▀MąąĮ©─ŻĪŻ▀@ķTšn░³└©└ĒšōĪó║╦ą─Ė┼─Ņ╠Įėæęį╝░ėHūįäė╩ųĮŌøQå¢Ņ}ĪŻū„š▀╦∙╩╣ė├Ą─Į╠▓─╩Ū╚╦╣żųŪ─▄(AI)ŅIė“Ą─ĮøĄõĮ╠▓─ų«ę╗Ż║Peter Norvig’s Artificial Intelligence?—?A Modern ApprOAch(╚╦╣żųŪ─▄—¼F┤·ĘĮĘ©)Ż¼į┌Ųõųą╬ęéāīW┴ĢĄ─ÄūéĆų„Ņ}░³└©Ż║ųŪ─▄agentsĪó═©▀^╦č╦„ĮŌøQå¢Ņ}Īó╔ńĢ■╗»AIĪóAIĄ─š▄īW/╔ńĢ■īW/╬┤üĒĪŻį┌šn│╠Ą─ĮY╬▓Ż¼ū„š▀╩╣ė├║åå╬Ą─╗∙ė┌╦č╦„Ą─agentsüĒĮŌøQ╠ōöMŁhŠ│ųąĄ─é„▌öå¢Ņ}ĪŻ
ū„š▀▒Ē╩Š═©▀^▀@ķTšn│╠īWĄĮ┴╦ŽÓ«öČÓĄ─ų¬ūRŻ¼ę▓øQČ©└^└mīW┴Ģ▀@éĆ╠ž╩ŌĄ─šnŅ}ĪŻį┌ĮėŽ┬üĒĄ─ÄūéĆąŪŲ┌Ż¼ū„š▀į┌┼fĮ╔Įģó╝ė┴╦║▄ČÓĻPė┌ÖCŲ„īW┴ĢĪó╔±ĮøŠWĮjĪóöĄō■╝▄śŗĄ─┐Ų╝╝ųvū∙Ż¼╠žäe╩Ūę╗éĆėą║▄ČÓśIā╚ų¬├¹īWš▀ģó╝ėĄ─ÖCŲ„īW┴ĢĢ■ūhĪŻūŅųžę¬Ą─╩ŪŻ¼ū„š▀į┌Udacityųą▀xą▐┴╦ę╗ķT“ÖCŲ„īW┴Ģ╚ļķT”Ą─į┌ŠĆšn│╠Ż¼ūŅĮ³ęčĮø═Ļ│╔īW┴ĢĪŻį┌▒Š╬─ųąŻ¼ū„š▀īóį┌šn│╠ųąīW┴ĢĄĮĄ─ÖCŲ„īW┴Ģ╦ŃĘ©ĘųŽĒĮo┤¾╝ęĪŻ
ÖCŲ„īW┴Ģ╦ŃĘ©┐╔ęįĘų×ķ╚²éĆ┤¾ŅÉŻ║▒OČĮīW┴ĢĪó¤o▒OČĮīW┴ĢĪóÅŖ╗»īW┴ĢĪŻŲõųąŻ║
▒OČĮīW┴Ģī”ė┌ėąś╦║ץ─╠žČ©öĄō■╝»(ė¢ŠÜ╝»)╩ŪĘŪ│Żėąą¦Ą─Ż¼Ą½╩Ū╦³ąĶę¬ī”ė┌Ųõ╦¹Ą─ŠÓļx▀MąąŅA£yĪŻ
¤o▒OČĮīW┴Ģī”ė┌į┌ĮoČ©╬┤ś╦ėøĄ─öĄō■╝»(─┐ś╦ø]ėą╠ßŪ░ųĖČ©)╔Ž░l¼FØōį┌ĻPŽĄ╩ŪĘŪ│Żėąė├Ą─ĪŻ
ÅŖ╗»īW┴ĢĮķė┌▀@ā╔š▀ų«ķg—╦³ßśī”├┐┤╬ŅA£y▓Į¾E(╗“ąąäė)Ģ■ėą─│ĘNą╬╩ĮĄ─Ę┤üŻ¼Ą½╩Ūø]ėą├„┤_Ą─ś╦ėø╗“š▀Õeš`ą┼ŽóĪŻ▒Š╬─ų„ę¬ĮķĮBėąĻP▒OČĮīW┴Ģ║═¤o▒OČĮīW┴ĢĄ─10ĘN╦ŃĘ©ĪŻ
▒OČĮīW┴Ģ
1.øQ▓▀śõ(Decision Trees)Ż║
øQ▓▀śõ╩Ūę╗éĆøQ▓▀ų¦│ų╣żŠ▀Ż¼╦³╩╣ė├śõą╬łD╗“øQ▓▀─Żą═ęį╝░ą“┴ą┐╔─▄ąįĪŻ░³└©Ė„ĘN┼╝╚╗╩┬╝■Ą─║¾╣¹Īó┘Yį┤│╔▒ŠĪó╣”ą¦ĪŻŽ┬łDš╣╩ŠĄ─╩Ū╦³Ą─┤¾Ė┼įŁ└ĒŻ║

łD1 øQ▓▀śõ┤¾Ė┼įŁ└Ē
Å─śIäšøQ▓▀Ą─ĮŪČ╚üĒ┐┤Ż¼┤¾▓┐ĘųŪķørŽ┬øQ▓▀śõ╩Ūįu╣└ū„│÷š²┤_Ą─øQČ©Ą─Ė┼┬╩ūŅ▓╗ąĶę¬å¢╩Ū/ʱå¢Ņ}Ą─▐kĘ©ĪŻ╦³─▄ūī─Ńęįę╗éĆĮYśŗ╗»Ą─║═ŽĄĮy╗»Ą─ĘĮ╩ĮüĒ╠Ä└Ē▀@éĆå¢Ņ}Ż¼╚╗║¾Ą├│÷ę╗éĆ║Ž║§▀ē▌ŗĄ─ĮYšōĪŻ
2.śŃ╦žžÉ╚~╦╣ĘųŅÉ(Naive Bayesian classification)Ż║
śŃ╦žžÉ╚~╦╣ĘųŅÉ╩Ūę╗ĘN╩«Ęų║åå╬Ą─ĘųŅÉ╦ŃĘ©Ż¼Įą╦³śŃ╦žžÉ╚~╦╣ĘųŅÉ╩Ūę“×ķ▀@ĘNĘĮĘ©Ą─╦╝ŽļšµĄ─║▄śŃ╦žŻ¼śŃ╦žžÉ╚~╦╣Ą─╦╝Žļ╗∙ĄA╩Ū▀@śėĄ─Ż║ī”ė┌Įo│÷Ą─┤²ĘųŅÉĒŚŻ¼Ū¾ĮŌį┌┤╦ĒŚ│÷¼FĄ─Śl╝■Ž┬Ė„éĆŅÉäe│÷¼FĄ─Ė┼┬╩Ż¼──éĆūŅ┤¾Ż¼Š═šJ×ķ┤╦┤²ĘųŅÉĒŚī┘ė┌──éĆŅÉäeĪŻ
ĪĪĪĪ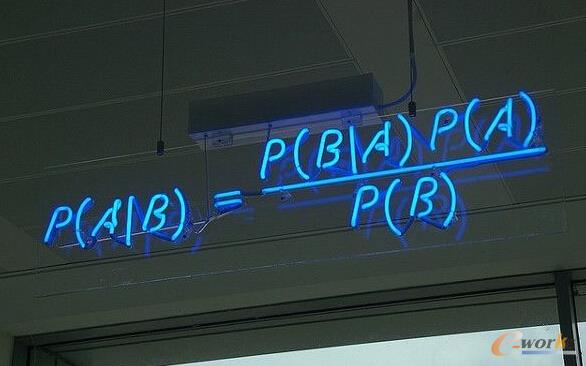
łD2 śŃ╦žžÉ╚~╦╣ĘųŅÉ
╦³Ą─¼FīŹ╩╣ė├└²ūėėąŻ║
īóę╗ĘŌļŖūėÓ]╝■ś╦ėø(╗“š▀▓╗ś╦ėø)×ķ└¼╗°Ó]╝■
īóę╗Ų¬ą┬Ą─╬─š┬ÜwŅÉĄĮ┐Ų╝╝Īóš■ų╬╗“š▀▀\äė
Öz▓ķę╗Č╬╬─▒Š▒Ē▀_Ą─╩ŪĘeśOŪķŠw▀Ć╩ŪŽ¹śOŪķŠw
─ś▓┐ūRäe▄ø╝■
3.ūŅąĪČ■│╦Ę©(Ordinary Least Squares Regression)Ż║
╚ń╣¹─ŃČ«ĮyėŗīWĄ─įÆŻ¼─Ń┐╔─▄ęįŪ░┬Āšf▀^ŠĆąį╗žÜwĪŻūŅąĪČ■│╦Ę©╩Ūę╗ĘNėŗ╦ŃŠĆąį╗žÜwĄ─ĘĮĘ©ĪŻ─Ń┐╔ęį░čŠĆąį╗žÜw«öū÷į┌ę╗ŽĄ┴ąĄ─³cųą«ŗę╗Śl║Ž▀mĄ─ų▒ŠĆĄ─╚╬äšĪŻėą║▄ČÓĘNĘĮĘ©┐╔ęįīŹ¼F▀@éĆŻ¼“ūŅąĪČ■│╦Ę©”╩Ū▀@śėū÷Ą─?—─Ń«ŗę╗ŚlŠĆŻ¼╚╗║¾×ķ├┐éĆöĄō■³c£y┴┐³c┼cŠĆų«ķgĄ─┤╣ų▒ŠÓļxŻ¼▓óīó▀@ą®╚½▓┐ŽÓ╝ėŻ¼ūŅĮKĄ├ĄĮĄ─öM║ŽŠĆīóį┌▀@éĆŽÓ╝ėĄ─┐éŠÓļx╔Ž▒M┐╔─▄ūŅąĪĪŻ
ĪĪĪĪ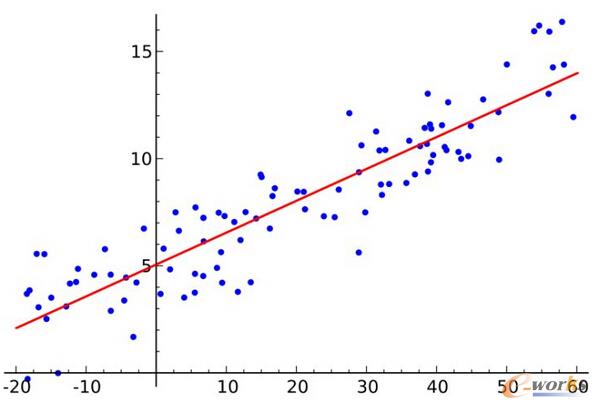
łD3 ūŅąĪČ■│╦Ę©
4.▀ē▌ŗ╗žÜw(Logistic Regression)Ż║
▀ē▌ŗ╗žÜw╩Ūę╗ĘNÅŖ┤¾Ą─ĮyėŗĘĮĘ©Ż¼╦³─▄Į©─Ż│÷ę╗éĆČ■ĒŚĮY╣¹┼cę╗éĆ(╗“ČÓéĆ)ĮŌßīūā┴┐ĪŻ╦³═©▀^╣└╦Ń╩╣ė├▀ē▌ŗ▀\╦ŃĄ─Ė┼┬╩Ż¼£y┴┐ĘųŅÉę└┘ćūā┴┐║═ę╗éĆ(╗“ČÓéĆ)¬Ü┴óĄ─ūā┴┐ų«ķgĄ─ĻPŽĄŻ¼▀@╩Ū└█ĘeĄ─▀ē▌ŗĘų▓╝ŪķørĪŻ
ĪĪĪĪ
łD4 └█ĘeĄ─▀ē▌ŗĘų▓╝Ūķør
┐éĄ─üĒšfŻ¼▀ē▌ŗ╗žÜw┐╔ęįė├ė┌ęįŽ┬ÄūéĆšµīŹæ¬ė├ł÷Š░Ż║
ą┼ė├įuĘų
£y┴┐ĀIõN╗ŅäėĄ─│╔╣”┬╩
ŅA£y─│ę╗«aŲĘĄ─╩š╚ļ
╠žČ©─│ę╗╠ņ╩ŪʱĢ■░l╔·Ąžš
5.ų¦│ųŽ“┴┐ÖC(Support Vector Machine)Ż║
SVM(Support Vector Machine)╩ŪČ■į¬ĘųŅÉ╦ŃĘ©ĪŻĮoČ©ę╗ĮM2ĘNŅÉą═Ą─NŠSĄ─ĄžĘĮ³cŻ¼SVM(Support Vector Machine)«a╔·ę╗éĆ(N – 1)ŠS│¼ŲĮ├µĄĮ▀@ą®³cĘų│╔2ĮMĪŻ╝┘įO─Ńėą2ĘNŅÉą═Ą─³cŻ¼Ūę╦³éā╩ŪŠĆąį┐╔ĘųĄ─ĪŻ SVM(Support Vector Machine)īóšęĄĮę╗Ślų▒ŠĆīó▀@ą®³cĘų│╔2ĘNŅÉą═Ż¼▓óŪę▀@Ślų▒ŠĆĢ■▒M┐╔─▄Ąž▀hļx╦∙ėąĄ─³cĪŻ
į┌ęÄ─ŻĘĮ├µŻ¼─┐Ū░ūŅ┤¾Ą─╩╣ė├ų¦│ųŽ“┴┐ÖCSVM(Support Vector Machine)(į┌▀m«öą▐Ė─Ą─ŪķørŽ┬)Ą─å¢Ņ}╩Ū’@╩ŠÅVĖµŻ¼╚╦ŅÉ╝¶Įė╬╗³cūRäeŻ¼╗∙ė┌łDŽ±Ą─ąįäeÖz£yŻ¼┤¾ęÄ─ŻĄ─łDŽ±ĘųŅÉĄ╚ĪŻ
ĪĪĪĪ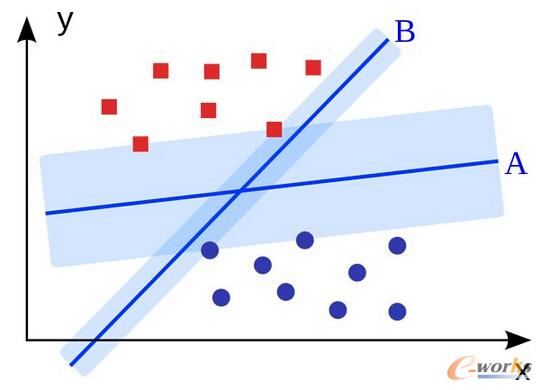
łD5 ╗∙ė┌łDŽ±Ą─ąįäeÖz£yŻ¼┤¾ęÄ─ŻĄ─łDŽ±ĘųŅÉ
6.ĮM║ŽĘĮĘ©(Ensemble methods)Ż║
ĮM║ŽĘĮĘ©╩ŪīW┴Ģ╦ŃĘ©Ż¼╦³śŗĮ©ę╗ŽĄ┴ąĘųŅÉŻ¼╚╗║¾═©▀^▓╔╚Ī╝ėÖÓ═ČŲ▒ŅA£yĄ─ĘĮ╩ĮüĒī”ą┬Ą─öĄō■³c▀MąąĘųŅÉĪŻįŁ╩╝Ą─╝»│╔ĘĮĘ©╩ŪžÉ╚~╦╣ŲĮŠ∙Ę©Ż¼Ą½ūŅĮ³Ą─╦ŃĘ©░³└©ī”Ųõ╝mÕe▌ö│÷ŠÄ┤aĪó╠ū┤³Īó╝ė╦┘Ą╚ĪŻ
─Ū├┤ĮM║ŽĘĮĘ©╚ń║╬▀\ąąĄ──žŻ┐×ķ╩▓├┤šf╦³éā▒╚Ųõ╦¹Ą──Żą═ę¬ā׹ѯ┐ę“×ķŻ║
╦³éāīóŲ½▓ŅŲĮŠ∙┴╦Ż║╚ń╣¹─Ńīó├±ų„³h┼╔Ą─├±ęŌš{▓ķ║═╣▓║═³hĄ─├±ęŌš{▓ķ░lį┌ę╗ŲŲĮŠ∙╗»Ż¼─Ū├┤─ŃīóĄ├ĄĮę╗éĆŠ∙║ŌĄ─ĮY╣¹Ż¼Ūę▓╗Ų½Ž“╚╬║╬ę╗ĘĮĪŻ
╦³éā£p╔┘┴╦▓Ņ«ÉŻ║ę╗Čč─Żą═Ą─┐éĮYęŌęŖø]ėąę╗éĆ─Żą═Ą─å╬ę╗ęŌęŖ─Ū├┤ÓąļsĪŻį┌Į╚┌ŅIė“Ż¼▀@Š═╩Ū╦∙ų^Ą─ČÓį¬╗»?—?ėąįSČÓ╣╔Ų▒ĮM║Ž▒╚ę╗éĆå╬¬ÜĄ─╣╔Ų▒Ą─▓╗┤_Č©ąįĖ³╔┘Ż¼▀@ę▓×ķ╩▓├┤─ŃĄ──Żą═į┌öĄō■ČÓĄ─ŪķørŽ┬Ģ■Ė³║├Ą─įŁę“ĪŻ
╦³éā▓╗╠½┐╔─▄▀^Č╚öM║ŽŻ║╚ń╣¹─Ńėąø]ėą▀^Č╚öM║ŽĄ─¬Ü┴ó─Żą═Ż¼─Ń═©▀^ę╗éĆ║åå╬Ą─ĘĮ╩Į(ŲĮŠ∙Ż¼╝ėÖÓŲĮŠ∙Ż¼▀ē▌ŗ╗žÜw)ī”├┐éƬÜ┴ó─Żą═Ą─ŅA£y▀MąąĮY║ŽŻ¼▀@śėĄ─įÆ▓╗╠½┐╔─▄Ģ■│÷¼F▀^Č╚öM║ŽĄ─ŪķørĪŻ
ĪĪĪĪ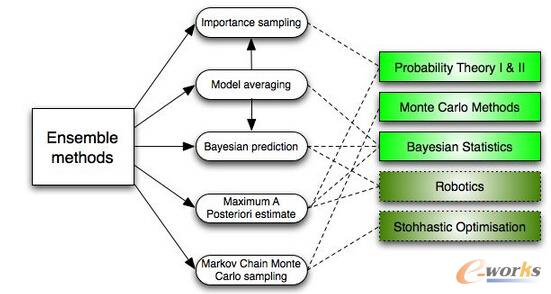
łD6 ▀^Č╚öM║Ž
¤o▒OČĮīW┴Ģ
7.Š█ŅÉ╦ŃĘ©(Clustering Algorithms)Ż║
Š█ŅÉ╩Ūę╗ĘNŠ█╝»ī”Ž¾Ą─╚╬䚯¼└²╚ńŻ║ŽÓ▒╚Ųõ╦¹▓╗═¼Ą─ĮMį┌═¼ę╗ĮM(╝»╚║)Ą─ī”Ž¾▒╦┤╦Ė³×ķŽÓ╦ŲĪŻ
├┐éĆŠ█ŅÉ╦ŃĘ©Č╝╩Ū▓╗═¼Ą─Ż¼▒╚╚ńšfėąęįŽ┬ÄūĘNŻ║
╗∙ė┌┘|ą─Ą─╦ŃĘ©
╗∙ė┌▀BĮėĄ─╦ŃĘ©
╗∙ė┌├▄Č╚Ą─╦ŃĘ©
┐╔─▄ąį
ŠSČ╚┐s£p
╔±ĮøŠWĮj/╔ŅČ╚īW┴Ģ
ĪĪĪĪ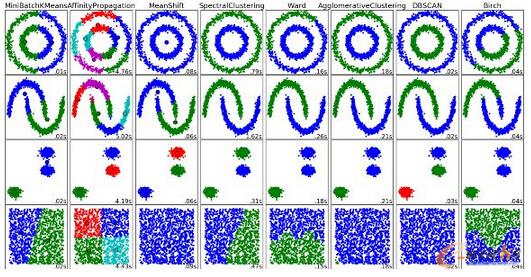
łD7 Š█ŅÉ╦ŃĘ©
8.ų„│╔ĘųĘų╬÷(Principal Component AnalysisŻ¼PCA)Ż║
═©▀^š²Į╗ūāōQīóę╗ĮM┐╔─▄┤µį┌ŽÓĻPąįĄ─ūā┴┐▐DōQ×ķę╗ĮMŠĆąį▓╗ŽÓĻPĄ─ūā┴┐Ż¼▐DōQ║¾Ą─▀@ĮMūā┴┐Įąų„│╔ĘųĪŻ
ę╗ą®ų„│╔ĘųĘų╬÷PCA│╠ą“Ą─æ¬ė├░³└©ē║┐sĪó║å╗»öĄō■Īó┐╔ęĢ╗»ĪŻūóęŌŻ¼ī”ė┌▀xō±╩Ūʱ╩╣ė├ų„│╔ĘųĘų╬÷ŅIė“ų¬ūR╩ŪĘŪ│Żųžę¬Ą─ĪŻ«ööĄō■╩ŪÓąļsĄ─Ģr║“(╦∙ėąĄ─ĮM╝■Ą─ų„│╔ĘųĘų╬÷ėąŽÓ«öĖ▀Ą─ĘĮ▓Ņ)Ż¼╦³╩Ū▓╗▀m║ŽĄ─ĪŻ
ĪĪĪĪ
łD8 ų„│╔ĘųĘų╬÷
9. Ųµ«ÉųĄĘųĮŌ(Singular Value Decomposition)Ż║
į┌ŠĆąį┤·öĄųąŻ¼SVD╩Ūę╗éĆĘŪ│ŻÅ═ļsŠžĻćĄ─ę“öĄĘųĮŌĪŻī”ė┌ę╗éĆĮoČ©Ą─m×nŠžĻćMŻ¼┤µį┌ę╗éĆĘųĮŌŻ¼M = UΣVŻ¼Ųõųąu║═v╩Ūå╬ę╗ŠžĻćŻ¼Σ╩Ūī”ĮŪŠžĻćĪŻ
ų„│╔ĘųĘų╬÷PCAŲõ╩ŪŲµ«ÉųĄĘųĮŌSVDĄ─║åå╬æ¬ė├ĪŻį┌ėŗ╦ŃÖCęĢėXŅIė“Ż¼Ą┌ę╗╚╦─śūRäe╦ŃĘ©Ż¼▀\ė├ų„│╔ĘųĘų╬÷PCAŲõ╩ŪŲµ«ÉųĄĘųĮŌSVDüĒ┤·▒Ē├µ┐ūū„×ķę╗éĆŠĆąįĮM║ŽĄ─“╠žš„─ś”Ż¼▓óī”Ųõū÷ĮĄŠSŻ¼╚╗║¾═©▀^║åå╬Ą─ĘĮĘ©Ųź┼õ║Ž▀mĄ─╔ĒĘ▌Ż╗ļm╚╗¼F┤·ĘĮĘ©Ė³Å═ļsŻ¼Ą½╩ŪįSČÓ╚╦╚į╚╗ę└┐┐ŅÉ╦ŲĄ─╝╝ągĪŻ
ĪĪĪĪ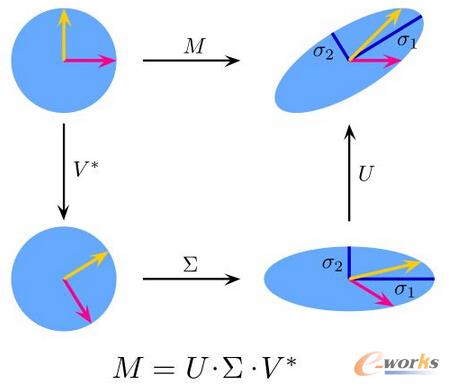
łD9 Ųµ«ÉųĄĘųĮŌ
10.¬Ü┴ó│╔ĘųĘų╬÷(Independent Component Analysis)Ż║
¬Ü┴ó│╔ĘųĘų╬÷(Independent Component AnalysisŻ¼ICA)╩Ūę╗ĘNĮę╩Šśŗų■ļSÖCūā┴┐Īó╝╝ąg£y┴┐Īóą┼╠¢Ą╚ļ[▓žę“╦žĄ─Įyėŗ╝╝ągĪŻICAČ©┴x┴╦╦∙ė^▓ņĄĮĄ─ČÓūā┴┐öĄō■╔·│╔─Żą═Ż¼▀@═©│Ż╩ŪĮoČ©×ķę╗éĆ┤¾ą═öĄō■ÄņĄ─śė▒ŠĪŻį┌įō─Żą═ųąŻ¼öĄō■ūā┴┐▒╗╝┘Č©×ķę╗ą®╬┤ų¬Øōūā┴┐Ą─ŠĆąį╗ņ║ŽŻ¼═¼Ģr╗ņ║ŽŽĄĮyę▓╚į╚╗╬┤ų¬ĪŻØōūā┴┐▒╗╝┘Č©╩ŪĘŪĖ▀╦╣║═ŽÓ╗ź¬Ü┴óĄ─Ż¼╦³éā▒╗ĘQ×ķ╦∙ė^▓ņĄĮĄ─öĄō■Ą─¬Ü┴óĘų┴┐ĪŻ
ĪĪĪĪ
łD10 ¬Ü┴ó│╔ĘųĘų╬÷
ICA┼cPCA╩ŪŽÓĻPĄ─Ż¼Ą½╦³Ė³ÅŖ┤¾ĪŻį┌▀@ą®ĮøĄõĄ─ĘĮĘ©═Ļ╚½╩¦öĪĄ─Ģr║“Ż¼ICA─▄ē“šęĄĮį┤Ņ^Ą─Øōį┌ę“╦žĪŻ╦³Ą─æ¬ė├░³└©öĄūųłDŽ±Īó╬─ÖnöĄō■ÄņĪóĮøØ·ųĖś╦║═ą─└Ē£yįćĪŻ
═©▀^ęį╔ŽĮķĮBŻ¼ŽÓą┼┤¾▓┐Ęų╚╦ī”ė┌ÖCŲ„īW┴ĢĄ─╦ŃĘ©Č╝ėąę╗Č©Ą─┴╦ĮŌĪŻ╚ń╣¹ī”▀@ĘĮ├µĖą┼d╚żĄ─įÆŻ¼┐╔ęįĮėų°▀\ė├─Ń└ĒĮŌĄ─╦ŃĘ©╚źäōįņÖCŲ„īW┴Ģæ¬ė├Ż¼×ķ╩└ĮńĖ„ĄžĄ─╚╦éāäōįņĖ³║├Ą─╔·╗ŅŚl╝■ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ÖCŲ„īW┴ĢŻ¼─ŃąĶę¬ų¬Ą└Ą─╩«éĆ╦ŃĘ©
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839719859.html