1.ę²čį
ļSų°ųŪ─▄╩ųÖC║═Ųõ╦¹ęŲäėįOéõĄ─Ųš╝░Ż¼ęŲäė╗ź┬ōŠW┐ņ╦┘░lš╣Ż¼║Ż┴┐Ą─ęŲäėæ¬ė├(Mobile ApplicationŻ¼App)│╔┴╦ęŲäė╗ź┬ōŠWĄ─ų„ę¬╚ļ┐┌ĪŻĖ∙ō■╚╩┐ą┼┘J╝»łF╣└ėŗŻ¼ĄĮ2016─ĻŻ¼╚½Ū“īóĢ■ėą100ā|▓┐┬ōŠWĄ─ęŲäėįOéõŻ¼ųŪ─▄╩ųÖCĄ─ŠWĮj┴„┴┐īóĢ■╩ŪĮ±╠ņĄ─50▒ČŻ¼Č°Ė³ČÓĄ─ęŲäėįOéõę▓ęŌ╬Čų°Ė³ČÓĄ─ęŲäėæ¬ė├ĪŻ╠O╣¹╣½╦Šė┌2008─Ļ7į┬╩ū┤╬═Ų│÷ęŲäėæ¬ė├╔╠ĄĻAppStoreŻ¼½@Ą├┴╦Š▐┤¾│╔╣”ĪŻ2012─Ļ10į┬Ż¼æ¬ė├öĄ┴┐ęčĮø│¼▀^70╚fŻ¼ų┴2013─Ļ5į┬Ż¼╣┘ĘĮæ¬ė├╔╠ĄĻAppStoreĄ─æ¬ė├Ž┬▌d┴┐╝┤īó═╗ŲŲ500ā|┤╬ĪŻ═¼ĢrŻ¼╚½Ū“ęŲäėæ¬ė├ęÄ─Żę▓į┌╝▒äĪöU┤¾Ż¼╩ųÖCųŲįņ╔╠ĪóļŖą┼▀\ĀI╔╠║═╗ź┬ōŠWĘ■äš╠ß╣®╔╠Ą╚╝Ŗ╝Ŗ═Ų│÷ūį╝║Ą─ęŲäėæ¬ė├╔╠ĄĻŻ¼ęŲäėæ¬ė├ęčĮø│╔×ķęŲäė╗ź┬ōŠW░lš╣Ą─ę╗ĘNą┬─Ż╩ĮĪŻ▒Ē1Įo│÷┴╦ÄūéĆ▒╚▌^ėą┤·▒ĒąįĄ─ęŲäėæ¬ė├╔╠ĄĻĄ─╗∙▒ŠŪķørĪŻŅAėŗ6į┬Ę▌Ż¼Google Play╔╠ĄĻĄ─æ¬ė├öĄ┴┐īó│¼▀^100╚fĪŻ─┐Ū░╚½Ū“ęŲäėæ¬ė├öĄ┴┐Ą─ęÄ─Żį┌░┘╚f╝ēäeŻ¼┼c¼FėąĄ─WebŠWšŠ║═WebŠWĒōöĄ┴┐ęÄ─ŻŽÓ▒╚ļm╚╗▀Ć▒╚▌^ąĪŻ¼Ą½╩ŪŲõ¼Fį┌Ą─öĄ┴┐ęÄ─ŻęčĮø┼c2000─Ļū¾ėęĄ─ŠWšŠ║═ŠWĒōöĄ┴┐ęÄ─ŻŽÓ«öŻ¼▓óŪę▀Ćį┌▓╗öÓį÷╝ėų«ųąĪŻķL╬▓└Ēšō╠ß│÷š▀ĪóĪČ▀BŠĆĪĘĄ─Chris Andersonį°╠ß│÷“Webęč╦└Ż¼╗ź┬ōŠW╚fÜq”Ż¼▒Ē╩ŠļSų°iPhone/iPad╚šØu│╔×ķų„┴„ėŗ╦ŃĮKČ╦Ż¼╚╦éāįĮüĒįĮ┴ĢæTė┌═©▀^ęŲäėæ¬ė├▄ø╝■½@╚Īą┼ŽóĪŻęŲäėæ¬ė├īóųØu│¼▀^×gė[Ų„Ż¼│╔×ķęŲäė╗ź┬ōŠWĄ─ų„ę¬╚ļ┐┌ĪŻ
▒Ē1 ęŲäėæ¬ė├ęÄ─Ż
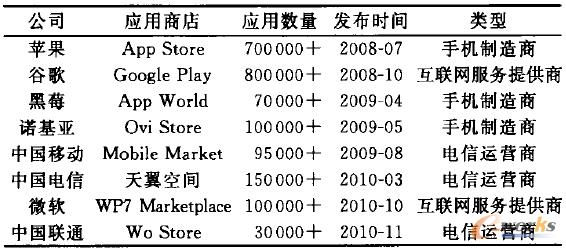
├µī”öĄ░┘╚fĄ─ęŲäėæ¬ė├(╬┤üĒ▀Ćīó└^└mį÷╝ė)Ż¼ė├涚²├µ┼Rų°ę╗éĆ╚šęµć└ųžĄ─╠¶æŻ║╚ń║╬▓┼─▄┐ņ╦┘šęĄĮūį╝║Žļꬥ─Īó▀m║Žūį╝║Ą─æ¬ė├?Č°▒ŖČÓĄ─ęŲäėæ¬ė├ķ_░lš▀ę▓├µ┼Rų°ę╗éĆå¢Ņ}Ż║╚ń║╬░čūį╝║ķ_░lĄ─æ¬ė├═Ų╦]Įoė├æ¶?ė├æ¶┼cæ¬ė├ķ_░lš▀ų«ķgĄ─╣®ąĶ├¼Č▄╚šęµ═╗│÷ĪŻ─┐Ū░ĮŌøQ▀@ę╗├¼Č▄Ą─ĘĮĘ©ų„ę¬ėą3ĘNŻ║
(1)ęŲäėæ¬ė├╔╠ĄĻĪŻį┌ęŲäėæ¬ė├░lš╣Ą─įńŲ┌Ż¼ęŲäėæ¬ė├ų„ę¬│÷¼Fį┌æ¬ė├╔╠ĄĻųąŻ¼╚ń▒Ē1ųą╦∙┴ą│÷Ą─ÄūéĆų„ꬥ─æ¬ė├╔╠ĄĻĪŻ×ķ┴╦▒Ńė┌ė├æ¶×gė[Īó▓ķšęūį╝║╦∙ąĶĄ─ęŲäėæ¬ė├Ż¼Ė„æ¬ė├╔╠ĄĻČ╝ī”öĄō■▀Mąą┴╦ę╗ą®╠Ä└ĒŻ¼░³└©ĘųŅÉĪó╠Ē╝ėś╦║ץ╚ĪŻĄ½╩Ū═©▀^Ęų╬÷░l¼FŻ¼─┐Ū░Ą─ĘųŅÉ┴ŻČ╚▒╚▌^┤ųŻ¼ę╗░Ń░³║¼ā╔éĆīė┤╬ŅÉäeŻ¼┤¾ŅÉöĄ┴┐į┌20éĆū¾ėęŻ¼ė╔ė┌æ¬ė├Ą─┐é¾wöĄ┴┐▒╚▌^┤¾Ż¼╦∙ęįå╬éĆŅÉäeŽ┬Ą─ęŲäėæ¬ė├╚į╚╗▒╚▌^ČÓŻ¼ė├æ¶ę¬Žļ┐ņ╦┘Č©╬╗ĄĮūį╝║ąĶꬥ─ęŲäėæ¬ė├ę└╚╗║▄└¦ļyŻ╗┴Ē═Ō▓╗═¼æ¬ė├╔╠ĄĻĄ─ĘųŅÉĘĮ╩Į╝░ŅÉäe├¹ĘQ▓╗Įyę╗Ż¼Ė„╔╠ĄĻų«ķgæ¬ė├ŅÉäe├¹ĘQāHėą50%ū¾ėę╩Ūę╗ų┬Ą─Ż╗Ė„ęŲäėæ¬ė├╔╠ĄĻ╦∙╠ß╣®Ą─╦č╦„╣”─▄┤¾Č╝╩Ū╗∙ė┌ĻPµIūųŲź┼õĄ─║åå╬╦č╦„Ż¼╦č╦„ĮY╣¹▒╚▌^▓ŅŻ¼¤oĘ©ØMūŃė├æ¶ąĶŪ¾ĪŻ
(2)Ą┌╚²ĘĮęŲäėæ¬ė├╝»│╔ĪŻ×ķ┴╦ĮŌøQęŲäėæ¬ė├╔╠ĄĻ┤µį┌Ą─å¢Ņ}Ż¼│÷¼F┴╦Ą┌╚²ĘĮęŲäėæ¬ė├╝»│╔Ę■äš╠ß╣®╔╠Ż¼Ųõų„ę¬╣żū„ĘĮ╩Į╩ŪÅ─▓╗═¼Ą─æ¬ė├╔╠ĄĻųąūź╚ĪęŲäėæ¬ė├ą┼ŽóŻ¼▓óī”ūź╚ĪĄĮĄ─æ¬ė├ą┼Žó▀Mąą▀Mę╗▓ĮĄ─╠Ä└ĒŻ¼╚ńųžą┬ĘųŅÉĪó╚źųžĪó╠Ē╝ėś╦║ץ╚Ż¼į┌┤╦╗∙ĄA╔Ž╠ß╣®æ¬ė├×gė[Īó╦č╦„╣”─▄ĪŻ
(3)ęŲäėæ¬ė├╦č╦„┼c═Ų╦]ĪŻęŲäėæ¬ė├╦č╦„┼c═Ų╦]╩ŪÄ═ų·ė├æ¶┐ņ╦┘šęĄĮūį╝║╦∙ąĶæ¬ė├Ą─ę╗ĘNėąą¦═ŠÅĮŻ¼─┐Ū░ęčĮøėąę╗ą®ŽÓæ¬Ą─ĮŌøQĘĮ░ĖĪŻ“vėŹė┌2012─Ļ6į┬░l▓╝┴╦║Ż╝{æ¬ė├╦č╦„Ż¼▀@╩Ūę╗┐Ņ╗∙ė┌ęŲäėæ¬ė├╣”─▄ī┘ąį╦č╦„Ą─ę²ŪµĪŻō■“vėŹĮķĮBŻ¼║Ż╝{æ¬ė├╦č╦„╩ŪīŻķT×ķė├æ¶╠ß╣®ęŲäėæ¬ė├╦č╦„Ę■䚥─ųŪ─▄╦č╦„ę²ŪµŻ¼īŻūóė┌App╦č╦„ęį╝░Ė∙ō■╦č╦„ąą×ķĄ─æ¬ė├═Ų╦]Ż¼ų„ę¬ØMūŃė├æ¶ūį╚╗šZčįĄ─╦č╦„ąĶŪ¾ĪŻQuixey╩Ūę╗éĆ═Ļ╚½ūįäė╗»Ą─ęŲäėæ¬ė├“╣”─▄╦č╦„”ę²ŪµŻ¼╦³ęį╬─▒ŠĘų╬÷ĪóšZ┴xĘų╬÷╝╝ąg×ķų„Ż¼╠ß╣®ęŲäėæ¬ė├Ą─£╩┤_╦č╦„ĪŻQuixey▓╗╩Ū║åå╬ĄžĖ∙ō■ė├æ¶Ą─├Ķ╩÷üĒ▀Mąą╦č╦„Ż¼┐╔ęį═©▀^QuixeyČ©┴xĄ─║»öĄ×ķė├æ¶╠ß╣®ęŲäėæ¬ė├╦č╦„║═░l¼FĘ■äšĪŻQuixeyÅ─ęŲäėæ¬ė├╔╠ĄĻĪóšōē»Īó▓®┐═Īó╔ńĢ■╗»├Į¾wŠWšŠ║═─õ├¹Ž¹ŽóüĒį┤ūź╚ĪęŲäėæ¬ė├Ą─ŽÓĻPą┼ŽóŻ¼▓óī”▀@ą®ą┼Žó▀Mąą▀Mę╗▓ĮĄ─│ķ╚ĪĪóĘų╬÷Īó╝»│╔Ż¼Å─Č°╠ß╣®Ė▀┘|┴┐Ą─╣”─▄╦č╦„Ę■äšĪŻ
╔Ž╩÷3ĘNĘĮ╩Įį┌ę╗Č©│╠Č╚╔Ž─▄ē“Ä═ų·ė├æ¶┐ņ╦┘šęĄĮūį╝║╦∙ąĶĄ─ęŲäėæ¬ė├Ż¼Ą½▀Ćėą║▄┤¾Ė─╔Ų║═╠ß╔²Ą─┐šķgĪŻęŲäėæ¬ė├╝»│╔╩ŪĮŌøQ▀@ę╗å¢Ņ}Ą─ėąą¦═ŠÅĮĪŻęŲäėæ¬ė├╝»│╔Ą─ų„ę¬╚╬äš╩Ū蹊┐╚ń║╬░č║Ż┴┐Ą─ęŲäėæ¬ė├╝░ŲõŽÓĻPą┼Žóėąą¦Ąž╝»│╔ŲüĒŻ¼×ķė├æ¶╠ß╣®Ė▀┘|┴┐Ą─╦č╦„Īó░l¼F║══Ų╦]Ę■äšĪŻčąŠ┐ā╚╚▌ų„ę¬░³└©ęŲäėæ¬ė├öĄō■│ķ╚ĪĪó╣”─▄Į©─ŻĪóęŲäėæ¬ė├Ųź┼õĪóęŲäėæ¬ė├╦č╦„┼c═Ų╦]Ą╚ĪŻ
▒Š╬─ų„ę¬ī”ęŲäėæ¬ė├╝»│╔ųą╚¶Ė╔ĻPµI蹊┐å¢Ņ}Ą─蹊┐¼FĀŅ▀MąąĘų╬÷┐éĮYŻ¼▓óųĖ│÷╬┤üĒĄ─ų„ę¬čąŠ┐ĘĮŽ“ĪŻ▒Š╬─Ą┌2╣ØĮķĮBęŲäėæ¬ė├╝»│╔┼cé„ĮyWeböĄō■╝»│╔Ą─«É═¼Ż¼╠ß│÷ęŲäėæ¬ė├╝»│╔╗∙▒Š┐“╝▄Ż╗Ą┌3╣Øī”ęŲäėæ¬ė├öĄō■│ķ╚ĪŽÓĻP╣żū„▀MąąĘų╬÷Ż╗Ą┌4╣Ø║═Ą┌5╣ØĘųäeĮķĮBęŲäėæ¬ė├Ųź┼õ║═ęŲäėæ¬ė├═Ų╦]╝╝ągŻ╗Ą┌6╣ØųĖ│÷╚¶Ė╔╠¶æąį蹊┐å¢Ņ}Ż╗ūŅ║¾ī”▒Š╬─ā╚╚▌▀Mąą┐éĮYĪŻ
ĪĪĪĪ2.ęŲäėæ¬ė├╝»│╔┐“╝▄
─┐Ū░ĻPė┌ęŲäėæ¬ė├╝»│╔Ą─蹊┐╔ą╠Äė┌Ų▓ĮļAČ╬Ż¼Ųõųąį┌ęŲäėæ¬ė├öĄō■│ķ╚ĪĘĮ├µ┤¾Č╝╩Ū╗∙ė┌é„ĮyĄ─WeböĄō■│ķ╚Ī╝╝ągŻ¼Ų½ųžė┌ĮYśŗ╗»ą┼ŽóĄ─│ķ╚ĪŻ¼ī”ė┌ęŲäėæ¬ė├╣”─▄ą┼Žó│ķ╚Ī╝╝ągĄ─蹊┐▀Ć▒╚▌^╔┘Ż╗į┌ęŲäėæ¬ė├╦č╦„┼c═Ų╦]ĘĮ├µėąę╗ą®│§▓Į蹊┐ĪŻ▒Š╣Ø╩ūŽ╚ī”WeböĄō■╝»│╔▀Mąą║åå╬ĮķĮBŻ¼ī”ęŲäėæ¬ė├╝»│╔║═WeböĄō■╝»│╔╝╝ąg▀Mąąī”▒╚Ęų╬÷Ż¼į┌┤╦╗∙ĄA╔ŽĮo│÷ęŲäėæ¬ė├╝»│╔Ą─╗∙▒Š┐“╝▄ĪŻ
ĪĪĪĪ2.1 WeböĄō■╝»│╔
ĻPė┌WeböĄō■╝»│╔Ż¼┤¾┴┐īWš▀ęčĮøū„┴╦ŽĄĮy╔Ņ╚╦Ą─蹊┐Ż¼Ųõųąäó韥╚╚╦ī”Deep WeböĄō■╝»│╔▀Mąą┴╦ŠC╩÷Ż¼╠ß│÷┴╦Deep WeböĄō■╝»│╔┐“╝▄Ż¼░č╝»│╔▀^│╠Ęų│╔┴╦3éĆ─ŻēKŻ║▓ķįāĮė┐┌╔·│╔─ŻēKĪó▓ķįā╠Ä└Ē─ŻēK║═▓ķįāĮY╣¹╠Ä└Ē─ŻēKĪŻŲõųą▓ķįāĮė┐┌╔·│╔─ŻēK░³└©WeböĄō■Äņ░l¼FĪó▓ķįāĮė┐┌─Ż╩Į│ķ╚ĪĪóWeböĄō■ÄņĘųŅÉ║═▓ķįāĮė┐┌╔·│╔4éĆūė─ŻēKŻ╗▓ķįā╠Ä└Ē─ŻēKų„ę¬░³└©WeböĄō■Äņ▀xō±Īó▓ķįā▐DōQĪó▓ķįā╠ßĮ╗3éĆūė─ŻēKŻ╗▓ķįāĮY╣¹╠Ä└Ē─ŻēKų„ę¬░³└©ĮY╣¹│ķ╚ĪĪóĮY╣¹ūóßī║═ĮY╣¹║Ž▓ó3éĆūė─ŻēKĪŻ╬─½IĘųäeī”▓ķįāĮė┐┌─Ż╩Į│ķ╚ĪĪó▓ķįāĮė┐┌Ą─╝»│╔▀Mąą┴╦蹊┐Ż╗╬─½Iī”WeböĄō■ÄņĄ─▀xō±Īó▓ķįā▐DōQŽÓĻP╝╝ąg▀Mąą┴╦Ęų╬÷Ż╗╬─½Iųž³c蹊┐┴╦╗∙ė┌ęĢėXĄ─▓ķįāĮY╣¹│ķ╚ĪĘĮĘ©ĪŻ
▓ķįāĮY╣¹Ą─╠Ä└Ē╩ŪWeböĄō■╝»│╔Ą─║╦ą─╚╬äšĪŻ▓ķįāĮY╣¹╠Ä└ĒĄ─ų„ę¬╚╬äš╩Ū░čüĒūįė┌ČÓéĆWeböĄō■ÄņĄ─«ÉśŗĄ─öĄō■ęįę╗éĆĮyę╗Ą─ą╬╩Įš╣╩ŠĮoė├æ¶Ż¼─┐Ū░Ą─ų„ę¬čąŠ┐╣żū„╝»ųąį┌╚ń║╬┐ņ╦┘£╩┤_ĄžÅ─▓ķįāĮY╣¹Ēō├µ│ķ╚Ī│÷ĮYśŗ╗»Ą─▓ķįāĮY╣¹ĪŻ─┐Ū░Ą─WeböĄō■│ķ╚Īų„ę¬░³└©ęįŽ┬ÄūĘN╝╝ągŻ║Ēō├µ│ķ╚ĪšZčįĪó╗∙ė┌DOMśõĄ─╝╝ągĪó│ķ╚ĪęÄät═Ųī¦╝╝ągĪó╗∙ė┌ęĢėXĄ─│ķ╚ĪĄ╚ĪŻ
ĪĪĪĪ2.2 ęŲäėæ¬ė├╝»│╔┼cWeböĄō■╝»│╔Ą─«É═¼
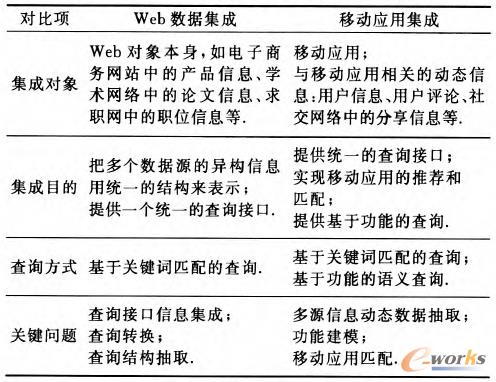
ęŲäėæ¬ė├╝»│╔┼cé„ĮyĄ─WeböĄō■╝»│╔ėąę╗ą®╣▓═¼³cŻ¼╚ńī┘ąįą┼Žó│ķ╚ĪĪóöĄō■╚┌║ŽĄ╚Ż¼ā╔š▀Č╝ąĶę¬Å─ŽÓæ¬Ą─WebĒō├µųą│ķ╚Ī│÷ĮYśŗ╗»Ą─ī┘ąįą┼ŽóŻ¼ī”ė┌▓╗═¼öĄō■į┤Ą─öĄō■ąĶę¬▀MąąŽ¹ųžĪó╚┌║ŽĄ╚ĪŻ╚╗Č°Ż¼┼cWeböĄō■╝»│╔ŽÓ▒╚Ż¼ęŲäėæ¬ė├╝»│╔ę▓ėąŲõ╠ž╩Ōų«╠ÄŻ¼Č■š▀Ą─ų„ę¬ģ^äeęŖ▒Ē2ĪŻ
▒Ē2 WeböĄō■╝»│╔┼cęŲäėæ¬ė├╝»│╔Ą─ī”▒╚
ĪĪĪĪ2.3 ęŲäėæ¬ė├╝»│╔╗∙▒Š┐“╝▄
╬ęéāßśī”ęŲäėæ¬ė├Ą─╠ž³cŻ¼▓óĮY║Ž¼FėąĄ─öĄō■╝»│╔╝╝ągŻ¼╠ß│÷┴╦ęŲäėæ¬ė├╝»│╔┐“╝▄Ż¼╚ńłD1╦∙╩ŠĪŻ
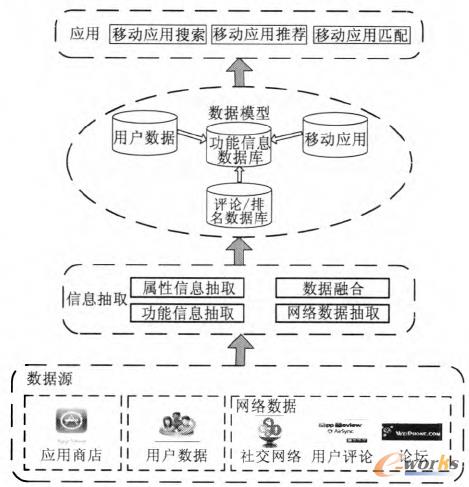
łD1 ęŲäėæ¬ė├╝»│╔┐“╝▄
ęŲäėæ¬ė├╝»│╔ų„ę¬░³└©4éĆīė┤╬Ż║öĄō■į┤Īóą┼Žó│ķ╚ĪĪóöĄō■─Żą═║═æ¬ė├ĪŻŲõųąöĄō■į┤ų„ę¬░³└©▒ŖČÓĄ─ęŲäėæ¬ė├╔╠ĄĻŻ¼ęį╝░┼cęŲäėæ¬ė├ŽÓĻPĄ─Ė„ĘNŠWĮjöĄō■į┤╚ńė├æ¶öĄō■Īó╔ńĮ╗ŠWĮjĪóė├æ¶įušōĪóšōē»ą┼ŽóĄ╚ĪŻęŲäėæ¬ė├╔╠ĄĻų„ę¬░³└©ęŲäėæ¬ė├Ą─╗∙▒Šī┘ąįą┼ŽóŻ¼įō▓┐Ęųą┼ŽóąĶę¬└¹ė├ŽÓæ¬Ą─öĄō■│ķ╚Ī╝╝ągŻ¼Å─ČÓéĆ▓╗═¼Ą─æ¬ė├╔╠ĄĻųą│ķ╚Ī│÷Š▀ėąĮyę╗Ė±╩ĮĄ─ĮYśŗ╗»ą┼ŽóŻ¼▓óĖ∙ō■īŹļHŪķør▀MąąöĄō■Ž¹ųžĪóöĄō■╚┌║ŽĄ╚╠Ä└ĒĪŻ
ęŲäėæ¬ė├▒Š╔ĒĄ─ą┼Žó╩ŪņoæBą┼ŽóŻ¼Č°ė├æ¶öĄō■ų„ę¬╩ŪųĖė├æ¶į┌╩╣ė├æ¬ė├│╠ą“Ą─▀^│╠ųą╦∙«a╔·Ą─ę╗ŽĄ┴ąŽÓĻPöĄō■Ż¼╚ńė├æ¶Ą─░▓čbĪóĖ³ą┬Īóäh│²Üv╩ĘŻ¼ė├æ¶╩╣ė├ĢrķgėøõøŻ¼ė├æ¶į┌æ¬ė├│╠ą“ųąĄ─┘Y┴Žą┼ŽóĄ╚ĪŻ═©▀^▀@ą®ą┼Žó┐╔ęįĘų╬÷ė├æ¶Ą─╩╣ė├┴ĢæTŻ¼┴╦ĮŌė├æ¶Ą─Øōį┌ąĶŪ¾Ż¼Å─Č°×ķė├æ¶╠ß╣®Ė³║├Ą─═Ų╦]Ę■äšĪŻĄ½╩Ū─┐Ū░įō▓┐Ęųą┼Žóę“ļ[╦Įå¢Ņ}Ż¼▓╗╠½╚▌ęūĄ├ĄĮĪŻ
ļSų°Web2.0╝╝ągĄ─░lš╣Ż¼║▄ČÓė├æ¶Č╝┴ĢæTė┌į┌ŠWĮjųąĘųŽĒūį╝║Ą─ŽÓĻPą┼ŽóŻ¼╚ńė├æ¶┐╔ęįį┌Facebookųą┼c║├ėčĘųŽĒūį╝║╦∙╩╣ė├Ą─ęŲäėæ¬ė├│╠ą“┴ą▒ĒĪóūį╝║Ą─╩╣ė├¾w“×ĪóįuārĄ╚Ż╗▀Ćėąę╗ą®ßśī”ęŲäėæ¬ė├Ą─īŻśIšōē»Ż¼┐╔ęį╣®ė├æ¶ų«ķgĮ╗┴„ęŲäėæ¬ė├Ą─╩╣ė├ą┼ŽóĪóī”æ¬ė├Ą─įuārĄ╚Ż¼╚ń▒╚▌^ėą├¹Ą─╩Ū═■õhŠWĪŻÅ─▀@ą®ą┼Žóųą┐╔ęį╚½ĘĮ╬╗┴╦ĮŌęŲäėæ¬ė├Ż¼Ęų╬÷ęŲäėæ¬ė├Ą─┘|┴┐Īóė├涎▓É█│╠Č╚Ą╚Ż¼ī”ė┌╠ßĖ▀Ę■äš┘|┴┐Š▀ėąųžę¬ū„ė├ĪŻ
ą┼Žó│ķ╚Īų„ę¬╩ŪÅ─▒ŖČÓöĄō■į┤ųą░č┼cęŲäėæ¬ė├ŽÓĻPĄ─ą┼Žó│ķ╚Ī│÷üĒŻ¼ų„ę¬░³└©ī┘ąįą┼Žó│ķ╚ĪĪóöĄō■╚┌║ŽĪó╣”─▄ą┼Žó│ķ╚Ī║═ŠWĮjöĄō■│ķ╚ĪĄ╚ĪŻŲõųąī┘ąįą┼Žó│ķ╚Īų„ę¬╩Ū░čęŲäėæ¬ė├ŽÓĻPĄ─ĮYśŗ╗»ą┼Žó│ķ╚Ī│÷üĒŻ¼╚ńæ¬ė├├¹ĘQĪóŅÉäeĪó▀m║ŽÖCą═ĪóārĖ±Ą╚Ż╗öĄō■╚┌║Žų„ę¬ĮŌøQ▓╗═¼öĄō■į┤ųąöĄō■Ą─ø_═╗å¢Ņ}Ż╗ęŲäėæ¬ė├╝»│╔ųąĄ─ī┘ąįą┼Žó│ķ╚Ī╝╝ąg║═öĄō■╚┌║Ž╝╝ąg┼cé„ĮyĄ─WeböĄō■╝»│╔╗∙▒ŠŽÓ═¼ĪŻ╣”─▄ą┼Žó│ķ╚ĪŻ¼ų„꬞ōž¤Å─ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼Žóęį╝░┼cęŲäėæ¬ė├ŽÓĻPĄ─įušōą┼Žóųą│ķ╚Ī│÷æ¬ė├Ą─ų„ę¬╣”─▄Ż¼įō▓┐Ęų╩ŪWeböĄō■╝»│╔ųą╦∙ø]ėą┐╝æ]╗“š▀╩Ūø]ėą▒žę¬┐╝æ]Ą─ā╚╚▌ĪŻŠWĮjöĄō■│ķ╚Īų„ę¬ųĖÅ─┼cęŲäėæ¬ė├ŽÓĻPĄ─Ė„ĘNöĄō■į┤ųą░č╦∙ąĶꬥ─ą┼Žó│ķ╚Ī│÷üĒŻ¼╚ńė├æ¶įušōą┼ŽóĪóęŲäėæ¬ė├Ą─╩╣ė├┼┼├¹Īóė├æ¶Ą─įuĘųą┼ŽóĄ╚Ż¼įō▓┐Ęųų„ę¬ļy³cį┌ė┌ŽÓĻPą┼ŽóĄ─ūRäeęį╝░öĄō■Ą─äėæB╠žąįĪŻ
─Żą═īėų„ę¬╩Ū░čęŲäėæ¬ė├Ą─╗∙▒Šī┘ąįą┼ŽóĪó─▄ū÷╩▓├┤Īóū÷Ą├į§├┤śėĪó╚ń║╬╩╣ė├Īóė├æ¶įuārĄ╚Ė„ĘN▓╗═¼Ą─ą┼Žóęįę╗ĘN║Ž└ĒĄ─ĘĮ╩Į▀MąąĮ©─ŻŻ¼▓óĮ©┴óĖ▀ą¦Ą─╦„ę²Ż¼ęįīŹ¼F┐ņ╦┘║═Ė▀┘|┴┐Ą─╦č╦„Ę■äšęį╝░Ųõ╦¹æ¬ė├ąĶŪ¾ĪŻ
æ¬ė├īėų„ę¬╩Ūį┌ęčĮø╠Ä└Ē║├Ą─ęŲäėæ¬ė├│╠ą“öĄō■ÄņĄ─╗∙ĄA╔Ž╠ß╣®ŽÓæ¬Ą─Ę■䚯¼╚ńęŲäėæ¬ė├╦č╦„ĪóęŲäėæ¬ė├═Ų╦]ĪóęŲäėæ¬ė├Ųź┼õĄ╚ĪŻ
ĪĪĪĪ3.ęŲäėæ¬ė├öĄō■│ķ╚Ī
ęŲäėæ¬ė├öĄō■│ķ╚Ī╩ŪęŲäėæ¬ė├╝»│╔Ą─║╦ą─╚╬äšų«ę╗Ż¼═¼Ģrę▓╩ŪŲõ╦¹╚╬䚥─╗∙ĄAĪŻį┌öĄō■│ķ╚ĪĘĮ├µęčĮøėą┤¾┴┐Ą─蹊┐╣żū„Ż¼░┤šš▓╗═¼Ą─ś╦£╩┐╔ęįĘųŅÉ▓╗═¼Ą─ŅÉäeĪŻ░┤öĄō■üĒį┤▓╗═¼Ż¼┐╔ęįĘų×ķ╗∙ė┌ĘŪĮYśŗ╗»öĄō■(╬─▒Š)Ą─│ķ╚Ī║═╗∙ė┌░ļĮYśŗ╗»öĄō■(WeböĄō■)Ą─│ķ╚ĪŻ╗░┤ššūįäė│╠Č╚▓╗═¼Ż¼┐╔ęįĘų×ķ╩ųäėĪó░ļūįäė║═╚½ūįäėĄ─öĄō■│ķ╚ĪĪŻį┌ęŲäėæ¬ė├╝»│╔ųąŻ¼ī┘ąįą┼Žó│ķ╚Ī║═╣”─▄ą┼Žó│ķ╚Ī╩ŪöĄō■│ķ╚Ī─ŻēKĄ─ų„ę¬─┐ś╦ĪŻī┘ąįą┼Žó│ķ╚Īų„ę¬╩ŪÅ─ęŲäėæ¬ė├╦∙į┌Ą─WebŠWĒōųą░čęŲäėæ¬ė├Ą─├¹ūųĪóŅÉäeĪó├Ķ╩÷Ą╚ą┼Žó│ķ╚Ī│÷üĒŻ¼╣”─▄öĄō■│ķ╚Īų„ę¬╩ŪÅ─ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼ŽóĪóšōē»ą┼Žó╝░ė├æ¶įušōą┼Žóųą░č─▄ē“┤·▒ĒęŲäėæ¬ė├╣”─▄Ą─ų„ę¬Č╠šZĪóŠõūėĄ╚│ķ╚Ī│÷üĒĪŻ
─┐Ū░į┌WeböĄō■│ķ╚ĪĘĮ├µęčĮøėą┴╦┤¾┴┐Ą─蹊┐╣żū„Ż¼ŲõųąäóéźĪó├ŽąĪĘÕĄ╚╚╦Wį┌ĪČDeep WeböĄō■╝»│╔蹊┐ŠC╩÷ĪĘųąī”WeböĄō■│ķ╚Ī╝╝ąg▀Mąą┴╦Üw╝{┐éĮYŻ¼▓ó░┤šš╩╣ė├╝╝ągĄ─▓╗═¼▀Mąą┴╦ĘųŅÉŻ¼ų„ę¬░³└©╗∙ė┌DOMśõĄ─╝╝ągĪó╗∙ė┌─Ż╩ĮĄ─╝╝ągĪóĒō├µ│ķ╚ĪšZčį┤©║═│ķ╚ĪęÄät═Ųī¦╝╝ągĄ╚ĪŻ▓╗▀^╬─½IĘų╬÷Ą─ų„ę¬╩Ū7─ĻęįŪ░Ą─╝╝ągŻ¼╬ęéā▓╗į┘▀Mąąįö╝ÜĮķĮBŻ¼▒Š╣Øų„ę¬ī”Į³Äū─Ļ╠ß│÷Ą─ę╗ą®ą┬Ą─Īó┤·▒ĒąįöĄō■│ķ╚Ī╝╝ąg▀MąąĘų╬÷ĪŻ
D-EEM╩Ūę╗ĘN╗∙ė┌DOMśõĄ─Deep WebīŹ¾w│ķ╚ĪÖCųŲ(DOM-tree based entity extraction mechanism for Deep Web)ĪŻ D-EEM▓╔ė├╗∙ė┌DOMśõĄ─ūįäėīŹ¾w│ķ╚Ī▓▀┬įŻ¼īóīŹ¾w│ķ╚Ī▀^│╠Ęų×ķöĄō■ģ^ė“Č©╬╗║═īŹ¾wģ^ė“Č©╬╗ā╔éĆļAČ╬Ż¼Å─Č°┐╔ęįį┌▒╚▌^Š½┤_Ą─ĘČć·ā╚▀MąąīŹ¾wģ^ė“Ą─Č©╬╗Ż¼┤¾┤¾╠ßĖ▀┴╦īŹ¾w│ķ╚ĪĄ─ą¦┬╩Ż╗┴Ē═ŌŻ¼×ķ┴╦╠ßĖ▀īŹ¾w│ķ╚ĪĄ─£╩┤_ąįŻ¼į┌│ķ╚Ī▀^│╠ųą▀Ć┐╝æ]┴╦DOMśõā╚╬─▒Šā╚╚▌╣سc║═į¬╦ž╣سcĄ─╠žš„ĪŻ╠’ĮĪ韥╚╚╦Īó×ķ┴╦─▄ē“═Ļš¹Ąž╠ß╚ĪDeep WeböĄō■ÄņųąĄ─ėøõøŻ¼╠ß│÷┴╦ę╗ĘN╗∙ė┌īė┤╬śõĄ─öĄō■½@╚Ī╝╝ągĪŻįō╝╝ąg░čWeböĄō■ÄņĮ©─Ż│╔ę╗┐├īė┤╬śõŻ¼▀@śėDeep WeböĄō■Ą─½@╚Īå¢Ņ}Š═┐╔ęį▐D╗»│╔śõĄ─▒ķÜvå¢Ņ}ĪŻŲõ┤╬═©▀^ī┘ąį┼┼ą“║═╗∙ė┌ī┘ąįųĄŽÓĻPČ╚Ą─åó░lęÄätųĖī¦▒ķÜv▀^│╠╠ßĖ▀▒ķÜvą¦┬╩ĪŻīŹ“×ĮY╣¹▒Ē├„įōĘĮĘ©Š▀ėą║▄║├Ą─Ė▓╔w┬╩║═▌^Ė▀Ą─╠ß╚Īą¦┬╩ĪŻOXPathī”XPath▀Mąą┴╦öUš╣Ż¼─▄ē“į┌Į╗╗ź╩ĮĄ─ŠWšŠųąų¦│ųĒō├µī¦║Į║═ĮY╣¹öĄō■Ą─│ķ╚ĪĪŻŲõūŅ┤¾Ą─╠ž³c╩Ū─▄ē“─ŻöMė├æ¶Ą─ąą×ķŻ¼äėæB½@╚ĪĒō├µĄ─CSSī┘ąįą┼ŽóŻ¼▓óŪę├┐┤╬ų╗ąĶ╠Ä└Ē«öŪ░Ą─Ēō├µŻ¼╦∙ęįąĶꬥ─ā╚┤µ┐šķg▒╚▌^ąĪĪŻ
LiuĄ╚╚╦└¦šJ×ķé„ĮyĄ─WeböĄō■│ķ╚Ī╝╝ągļm╚╗─▄ē“╚ĪĄ├▌^║├Ą─│ķ╚Īą¦╣¹Ż¼Ą½╩Ū┤¾ČÓČ╝ę└┘ćė┌WebĒō├µŠÄ│╠šZčįŻ¼ę╗Ą®Ēō├µšZčį░l╔·┴╦Ė─ūāŻ¼│ķ╚Ī╝╝ągę▓Ą├ū÷ŽÓæ¬Ą─Ė─ūāĪŻ×ķ┴╦┐╦Ę■▀@ĘĮ├µĄ─Ž▐ųŲŻ¼LiuĄ╚╚╦ŽĄĮyĘų╬÷┴╦ČÓĘNĮY╣¹Ēō├µĄ─ęĢėX╠žš„Ż¼▓ó╩╣ė├ĮY╣¹ĒōĄ─ęĢėX╠žš„üĒ▀MąąöĄō■ėøõø║═öĄō■ĒŚĄ─│ķ╚Ī╣żū„Ż¼┤╦ĘĮĘ©ūŅ┤¾Ą─╠ž³c╩Ū│ķ╚Ī▀^│╠┼cĒō├µšZčįĘNŅɤoĻPŻ¼▀m║Žį┌ČÓšZĘNŁhŠ│ųąĄ─╩╣ė├ĪŻ
FerraraĄ╚╚╦Å─ę╗éĆą┬Ą─ĮŪČ╚ī”WeböĄō■│ķ╚Ī╝╝ąg║═æ¬ė├▀Mąą┴╦ŠC╩÷ĪŻęį═∙Ą─ŠC╩÷šō╬─ų„ę¬╩ŪÅ─öĄō■│ķ╚Ī╝╝ąg║═╦ŃĘ©Ą─ĮŪČ╚▀MąąĘųŅÉ║═├Ķ╩÷Ż¼Č°FerraraĄ╚╚╦╩ū┤╬Å─æ¬ė├Ą─ĮŪČ╚ī”WeböĄō■│ķ╚Ī╝╝ąg▀Mąą┴╦ĘųŅÉŻ¼╔Ņ╚╦Ęų╬÷┴╦▓╗═¼æ¬ė├ŅIė“ųąWeböĄō■│ķ╚Ī╝╝ągĄ─ŽÓ═¼³c║═▓╗═¼³cĪŻū„š▀ų„ę¬Å─Ų¾śIæ¬ė├║═╔ńĮ╗ŠWĮjæ¬ė├ā╔éĆ┤¾Ą─ŅIė“▀Mąą┴╦Ęų╬÷Ż¼▓óųĖ│÷┴╦▓╗═¼æ¬ė├ŅIė“ųąöĄō■│ķ╚Ī╝╝ąg┤µį┌Ą─╠¶æąįå¢Ņ}ĪŻ
±R░▓ŽŃĄ╚╚╦ßśī”ųžÅ═šZ┴xś╦ūó║═ŪČ╠ūī┘ąįĄ─å¢Ņ}Ż¼╠ß│÷┴╦ę╗ĘN╗∙ė┌ĮY╣¹─Ż╩ĮĄ─Deep WeböĄō■│ķ╚ĪÖCųŲĪŻįōÖCųŲīóöĄō■│ķ╚Ī╣żū„Ęų×ķĮY╣¹─Ż╩Į╔·│╔║═öĄō■│ķ╚Īā╔éĆļAČ╬Ż¼į┌ĮY╣¹─Ż╩Į╔·│╔ļAČ╬▀Mąąī┘ąįšZ┴xś╦ūóŻ¼Å─Č°ĮŌøQ┴╦ųžÅ═šZ┴xś╦ūóå¢Ņ}Ż╗į┌ĮY╣¹─Ż╩ĮĄ─╗∙ĄA╔Ž╠ß│÷┴╦ę╗ĘNą┬Ą─öĄō■│ķ╚ĪĘĮĘ©Ż¼║▄║├ĄžĮŌøQ┴╦ŪČ╠ūī┘ąįå¢Ņ}ĪŻ
ė╔ė┌ęŲäėæ¬ė├öĄō■═∙═∙▒Ē▀_ļSęŌŻ¼Š▀ėą▓╗ęÄĘČąįŻ¼×ķ┴╦Ė─╔ŲęŲäėæ¬ė├Ųź┼õĪó═Ų╦]Ą─ą¦╣¹Ż¼ąĶę¬Å─▀@ą®▓╗ęÄĘČĄ─ĪóČ╠ąĪĄ─ęŲäėæ¬ė├öĄō■ųą│ķ╚Ī│÷Ųõų„Ņ}╗“ĻPµIį~ĪŻZhaoĄ╚╚╦ų„ę¬čąŠ┐╚ń║╬Å─Twitterą┼Žóųą│ķ╚Ī│÷ų„Ņ}ĻPµIČ╠šZĪŻTwitterą┼Žóę╗░ŃČ╝▒╚▌^Č╠Ż¼▓óŪęįļę¶▒╚▌^ČÓŻ¼×ķ┴╦╠ßĖ▀│ķ╚Ī┘|┴┐Ż¼ū„š▀└¹ė├ĻPµIį~┼┼ą“ĪóĻPµIČ╠šZ╔·│╔║═ĻPµIČ╠šZ┼┼ą“3éĆļAČ╬üĒīŹ¼FĪŻį┌ĻPµIį~┼┼ą“ųąŻ¼╗∙ė┌ų„Ņ}├¶Ėąé„▓ź╦ŃĘ©Ż¼ī”ų„Ņ}PageRank╦ŃĘ©▀Mąą┴╦Ė─▀MŻ╗į┌ĻPµIį~┼┼ą“║═ĻPµIČ╠šZ╔·│╔Ą─╗∙ĄA╔ŽŻ¼įOėŗ┴╦ę╗éĆĖ┼┬╩Č╠šZįuĘų║»öĄŻ¼ūŅ║¾└¹ė├įōįuĘų║»öĄī”Č╠šZ▀Mąą┼┼ą“Ż¼╚ĪūŅŪ░├µĄ─╚¶Ė╔éĆČ╠šZū„×ķĻPµIČ╠šZĪŻYuĄ╚╚╦╠ß│÷┴╦ę╗ĘNÅ─╔╠ŲĘįušōųą▀Mąąų„Ņ}│ķ╚ĪĄ─ĘĮĘ©ĪŻū„š▀╩ūŽ╚═©▀^ŅA╠Ä└ĒŻ¼│ķ╚Ī│÷├¹į~╗“├¹į~Č╠šZŻ¼▓ó░č▀@ą®├¹į~║═├¹į~Č╠šZū„×ķ║“▀xų„Ņ}Ż╗╚╗║¾ėŗ╦Ń▀@ą®ų„Ņ}Ą─ŽÓī”į~ŅlŻ¼╚ń╣¹ŽÓī”į~ŅlĄ═ė┌─│éĆĻ@ųĄŻ¼ät▀^×VĄ¶Ż¼▓╗▀Mąą║¾├µĄ─╠Ä└ĒŻ╗ūŅ║¾ßśī”├┐éĆ║“▀xų„Ņ}ėŗ╦ŃŲõĖ─▀MĄ─TF-IDFųĄŻ¼╚ń╣¹Ė─▀MĄ─TF-IDFųĄ┤¾ė┌─│éĆĻ@ųĄŻ¼ätįōų„Ņ}Š═┐╔ęįū„×ķūŅ║¾Ą─ĮY╣¹ĪŻ┴Ē═Ōį┌▀Mąąų„Ņ}│ķ╚ĪĄ─▀^│╠ųąŻ¼×ķ┴╦▀^×VĄ¶╚▀ėÓĄ─ų„Ņ}Ż¼ū„š▀╠ß│÷┴╦ę╗éĆų„Ņ}ų¦│ųČ╚Ż¼╚ń╣¹ų„Ņ}w‘Ą─Ņl┬╩ąĪė┌─│éĆ░³║¼wiĄ─Č╠šZ(wiŻ¼wj)Ą─Ņl┬╩Ż¼ätwiŠ═┐╔ęį▀^×VĄ¶Ż¼ų╗░čwiwjū„×ķę╗éĆ║“▀xų„Ņ}ĪŻ
ĪĪĪĪ4.ęŲäėæ¬ė├Ųź┼õ
ō■╬ęéāš{蹯¼─┐Ū░▀Ćø]ėąĻPė┌ęŲäėæ¬ė├╝»│╔ŽÓĻP╝╝ągĄ─ŽĄĮyąį蹊┐╣żū„Ż¼ļSų°ęŲäėæ¬ė├Ą─Ųš╝░╝░öĄ┴┐Ą─▓╗öÓį÷╝ėŻ¼ī”ė┌ęŲäėæ¬ė├╝»│╔Ą─蹊┐Š▀ėąŪ░š░ąį║═▒žę¬ąįĪŻęŲäėæ¬ė├╝»│╔ųąėą║▄ČÓĻPµIąįå¢Ņ}ąĶę¬čąŠ┐Ż¼╚ńą┼Žó│ķ╚Ī╝╝ągĪóöĄō■╚┌║ŽĪóīŹ¾wūRäeĪóūįäė═Ų╦]Īóæ¬ė├Ųź┼õĄ╚ĪŻČ°ęŲäėæ¬ė├Ųź┼õį┌ęŲäėæ¬ė├╝»│╔ųąŠ▀ėąųžę¬ęŌ┴xŻ¼╩Ūą┼Žó╝»│╔Īó═Ų╦]║═╦č╦„Ą─╗∙ĄAĪŻ╦∙ęįŻ¼─┐Ū░╬ęéāų„ę¬ßśī”ęŲäėæ¬ė├Ųź┼õå¢Ņ}▀MąąčąŠ┐ĪŻ
ĪĪĪĪ4.1 ęŲäėæ¬ė├ī┘ąį╠ž³c
į┌ęŲäėæ¬ė├Ųź┼õ▀^│╠ųąŻ¼╬ęéāų„ę¬╩Ū╗∙ė┌ęŲäėæ¬ė├ī┘ąįüĒėŗ╦ŃŲõŽÓ╦ŲČ╚ĪŻ═©▀^ė^▓ņ╬ęéā░l¼FęŲäėæ¬ė├Ą─├¹ĘQĪó├Ķ╩÷ą┼ŽóČ╝Š▀ėąę╗ą®╠ž³cĪŻ
ęŲäėæ¬ė├├¹ĘQŻ║╣”─▄ŽÓ╦ŲĄ─ęŲäėæ¬ė├├¹ĘQ═∙═∙░³║¼ŽÓ═¼Ą─į~Ż¼╗“š▀░³║¼═¼┴xį~Ż¼ėąą®├¹ĘQųą░³║¼ę╗ą®Å═║Žį~╚ńautolockŻ¼ shake2mutecallŻ¼ėąą®├¹ĘQųąĄ─į~▓╗╩Ūę╗éĆėąą¦Ą─ėóšZå╬į~Ż¼āHāH╩Ūę╗éĆś╦ūR╚ńOkotagŻ¼Barcode ScannerĪŻ
├Ķ╩÷ą┼ŽóĄ─Č╠╬─▒Š╠žąįŻ║├Ķ╩÷ą┼Žó┼cé„ĮyĄ─╬─▒Š╬─Ön▓╗═¼Ż¼ę╗░ŃČ╝▒╚▌^Č╠Ż¼ė╔╚¶Ė╔éĆŠõūėĮM│╔Ż¼┐╔ęįęĢ×ķČ╠╬─▒ŠĪŻę“┤╦Ż¼├Ķ╩÷ą┼Žóųąå╬į~Ą─╣▓¼FĖ┼┬╩▒╚▌^Ą═Ż¼╝┤╩╣╩Ū╣”─▄ŽÓ╦ŲĄ─ęŲäėæ¬ė├Ż¼┐╔─▄Č╝▓╗░³║¼╣▓═¼Ą─į~ģR╗“š▀ŽÓ═¼Ą─į~▒╚▌^╔┘ĪŻė╔┤╦Ą├ĄĮĄ─╬─▒Š╠žš„ŠžĻćŠ═▒╚▌^ŽĪ╩ĶŻ¼╦∙ęįé„ĮyĄ─Ž“┴┐┐šķg─Żą═¤oĘ©║▄║├ĄžĖ∙ō■ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼Žóėŗ╦ŃŲõŽÓ╦ŲČ╚Ż╗┴Ē═ŌŻ¼ō■╬ęéāė^▓ņ░l¼FŻ¼ė╔ė┌ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼Žóę╗░ŃČ╝╩Ūė╔ķ_░lš▀╠ß╣®Ą─Ż¼╦∙ęį├Ķ╩÷ą┼ŽóĄ─ū½īæĘŪ│Ż▓╗ęÄĘČŻ¼═∙═∙░³║¼║▄ČÓĘŪ╣”─▄ąį├Ķ╩÷╗“š▀šf╩Ūįļę¶öĄō■Ż¼╚ńÅVĖµą┼ŽóĪóė├æ¶▓┘ū„ųĖ─ŽĪóŲĮ┼_ę¬Ū¾Ą╚Ż¼▀@ą®ĘŪ╣”─▄ąį├Ķ╩÷ī”ė┌ėŗ╦ŃęŲäėæ¬ė├Ą─ŽÓ╦ŲČ╚Š▀ėą║▄┤¾Ą─žō├µė░ĒæĪŻę“┤╦Ż¼×ķ┴╦╠ßĖ▀ęŲäėæ¬ė├ŽÓ╦ŲČ╚ėŗ╦ŃĄ─£╩┤_ąįŻ¼╬ęéā▒žĒÜĮŌøQŽĪ╩Ķąį║═įļę¶å¢Ņ}ĪŻ
▒Š╣Ø║¾├µĄ─ā╚╚▌ų„ę¬ī”Č╠╬─▒ŠĘų╬÷Ą─ŽÓĻP╝╝ąg║═ā╔ĘNęŲäėæ¬ė├Ųź┼õĘĮĘ©▀MąąĘų╬÷ĪŻ
ĪĪĪĪ4.2 Č╠╬─▒ŠĘų╬÷
─┐Ū░ęčĮøėą║▄ČÓīWš▀ßśī”Č╠╬─▒Š▀Mąą┴╦┤¾┴┐Ą─蹊┐╣żū„Ż¼╚ńČ╠╬─▒ŠĄ─ų„Ņ}░l¼FĪóČ╠╬─▒ŠĄ─ŪķĖąĘų╬÷ĪóČ╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦ŃĪóĘųŅÉĪóŠ█ŅÉĄ╚ĪŻŲõųąČ╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦Ń║═Č╠╬─▒ŠĘųŅÉ╝╝ągī”ęŲäėæ¬ė├Ųź┼õėąųžę¬Ą─ųĖī¦ęŌ┴xŻ¼╦∙ęį▒Š╬─ī”ūŅĮ³ĻPė┌Č╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦Ń║═Č╠╬─▒ŠĘųŅÉ╝╝ągĘĮ├µĄ─蹊┐▀MąąĘų╬÷┐éĮYĪŻ
ĪĪĪĪ4.2.1 Č╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦Ń
Č╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦ŃĄ─ų„ę¬╚╬äš╩Ūė├üĒ┼ąöÓ▓╗═¼Ą─Č╠╬─▒Š├Ķ╩÷ų«ķgĄ─ŽÓ╦Ų│╠Č╚Ż¼Č╠╬─▒ŠĄ─ŽÓ╦ŲČ╚įĮĖ▀Ż¼šf├„Č╠╬─▒Š▒Ē▀_Ą─ęŌ╦╝╗“ė^³cįĮŽÓ╦ŲĪŻČ╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦Ń╩ŪČ╠╬─▒ŠĘų╬÷Ą─╗∙ĄA╣żū„Ż¼╩ŪĘųŅÉĪóŠ█ŅÉ║═ų„Ņ}░l¼FĄ─ųžę¬╝╝ągų«ę╗ĪŻ
╬─½Ių„ę¬╠ß│÷┴╦ę╗ĘN╗∙ė┌Ė┼┬╩ų„Ņ}╔·│╔─Żą═Ą─Č╠╬─▒ŠŽÓ╦ŲČ╚ėŗ╦ŃĘĮĘ©ĪŻ║╦ą─╦╝Žļ╩ŪŻ¼ī”ė┌ā╔éĆ┤²▒╚▌^Ą─Č╠╬─▒ŠČ°čįŻ¼░č╦³éāĘų│╔ā╔▓┐ĘųŻ¼ę╗▓┐Ęų╩ŪŽÓ═¼Ą─å╬į~Ż¼┴Ēę╗▓┐Ęų╩Ū▓╗═¼Ą─å╬į~Ż╗╚╗║¾į┌ę╗éĆĮoČ©Ą─Č╠╬─▒Š╝»║ŽųąŻ¼╗∙ė┌LDA─Żą═Ż¼└¹ė├GibbsSamplingĘĮĘ©šę│÷ļ[║¼ų„Ņ}╝░ų„Ņ}Ą─Ė┼┬╩Ęų▓╝Ż╗ĮėŽ┬üĒį┌░l¼FĄ─ų„Ņ}Ęų▓╝╔Žėŗ╦Ń▓╗═¼å╬į~Ą─ŽÓ╦ŲČ╚Ż╗ūŅ║¾░čā╔š▀ŽÓĮY║Žėŗ╦Ń┐é¾wŽÓ╦ŲČ╚ĪŻįōĘĮĘ©─▄ē“į┌ę╗Č©│╠Č╚╔ŽĮŌøQČ╠╬─▒ŠĄ─ŽĪ╩Ķąįå¢Ņ}Ż¼Ą½╩ŪŲõųąę▓┤µį┌ę╗ą®╠¶æŻ¼╚ńļ[║¼ų„Ņ}Ą─éĆöĄ╚ń║╬┤_Č©Ż¼ŽÓ╦ŲČ╚Ą─ķgųĄ╚ń║╬┼ąöÓĄ╚Ż╗╬─½Ių„ę¬ßśī”Č╠╬─▒ŠĄ─ŽĪ╩Ķąį╠ž³cŻ¼╠ß│÷┴╦ę╗ĘNöU│õČ╠╬─▒Šą┼ŽóĄ─ĘĮĘ©ĪŻī”ė┌├┐ę╗éĆČ╠╬─▒ŠŻ¼śŗįņę╗éĆ▓ķįāŻ¼╠ßĮ╗Įo╦č╦„ę²ŪµŻ¼╚╗║¾└¹ė├╦č╦„ę²ŪµĘĄ╗žĄ─ĮY╣¹üĒ┤·▒ĒČ╠▒ŠŻ¼▀@śėŠ═┐╔ęį┤¾┤¾öU│õČ╠╬─▒ŠĄ─ą┼ŽóŻ¼═¼Ģrū„š▀╠ß│÷┴╦ę╗ĘNŽÓ╦ŲČ╚║╦║»öĄŻ¼ė├üĒėŗ╦ŃČ╠╬─▒Šų«ķgĄ─ŽÓ╦ŲČ╚Ż¼Š▀ėą▌^║├Ą─£╩┤_ąį║═┐╔öUš╣ąįŻ╗╬─½Ių„ę¬╩ŪĮŌøQŠõūėų«ķgĄ─ŽÓ╦ŲČ╚ėŗ╦Ńå¢Ņ}Ż¼é„ĮyĄ─ėŗ╦ŃĘĮĘ©▓╗Š▀ėą▌^║├Ą─öUš╣ąįŻ¼ū„š▀╠ß│÷┴╦ę╗ĘN╗∙ė┌šZ┴xŠWĮj║═ĮyėŗĘų╬÷ŽÓĮY║ŽĄ─ĘĮĘ©Ż¼Š▀ėą▌^║├Ą─ūį▀mæ¬ąįŻ╗╬─½I░čČ╠╬─▒ŠĄ─šZ┴xą┼Žó║═Įyėŗą┼ŽóŽÓĮY║ŽŻ¼╠ß│÷┴╦ę╗ĘNą┬Ą─Č╠╬─▒Š─Żą═ĘĮĘ©ĪŻų„ę¬ėą3éĆ▓Į¾EŻ║╩ūŽ╚╗∙ė┌šZ┴xį~Ąõ╚ńWordNetėŗ╦Ń│÷│§╩╝Ą─į~ŽÓ╦ŲČ╚ŠžĻćŻ╗╚╗║¾ęį┤╦×ķ╗∙ĄAŻ¼ī”į~ŽÓ╦ŲČ╚║═Č╠╬─▒ŠŽÓ╦ŲČ╚▀MąąĄ³┤·ėŗ╦ŃŻ¼ų▒ų┴╩šö┐Ż╗ūŅ║¾└¹ė├Ą├ĄĮĄ─į~ŽÓ╦ŲČ╚ŠžĻćī”įŁüĒĄ─╬─Önę╗į~ŅlŠžĻć▀Mąąą▐š²Ż¼ė│╔õĄĮą┬Ą─Ž“┴┐┐šķgųąŻ¼▓óį┌ą┬Ą─Ž“┴┐┐šķgųą▀MąąČ╠╬─▒ŠŽÓ╦ŲČ╚Ą─ėŗ╦ŃŻ¼īŹ“×▒Ē├„╚ĪĄ├┴╦▌^║├Ą─ą¦╣¹Ż╗╬─½Iī”¼FėąĄ─ŠõūėŽÓ╦ŲČ╚Ą─ėŗ╦ŃĘĮĘ©▀Mąą┴╦Ęų╬÷Ż¼░³└©šZĘ©ŽÓ╦ŲČ╚ĪóšZ┴xŽÓ╦ŲČ╚║═šZė├ŽÓ╦ŲČ╚Ż¼▓ó╠ß│÷ę╗ĘNą┬Ą─╗∙ė┌ĻPµIį~╠ß╚ĪĄ─ŠõūėŽÓ╦ŲČ╚ėŗ╦ŃĘĮĘ©ĪŻ═©▀^ė^▓ņŻ¼▓ó▓╗╩Ū╦∙ėąĄ─į~ī”▒Ē▀_ŠõūėĄ─ęŌ┴xČ╝Ųū„ė├Ż¼╦∙ęįū„š▀Ė∙ō■å╬į~Ą─į~ąįĪóŠõūėšZĘ©ĮYśŗĄ╚╠ß╚Ī│÷ĻPµIį~Ż¼▓óĮo├┐éĆį~┘xėĶ▓╗═¼Ą─ÖÓųžŻ¼į┌┤╦╗∙ĄA╔Ž▀MąąŽÓ╦ŲČ╚Ą─ėŗ╦ŃŻ╗╬─½IÅ─ą┼ŽóÖz╦„Ą─ĮŪČ╚Ż¼ī”Č╠╬─▒ŠĄ─▒Ē╩Š║═ŽÓ╦ŲąįČ╚┴┐▀Mąą┴╦Ęų╬÷Ż¼▓óī”Ė„ĘN▓╗═¼Ą─Č╚┴┐ĘĮĘ©▀Mąą┴╦ī”▒╚Ż¼░³└©╗∙ė┌ūųĄõĄ─ŽÓ╦ŲČ╚Č╚┴┐Īó╗∙ė┌į~Ė╔╗»║═šZčį─Żą═Ą─ŽÓ╦ŲąįČ╚┴┐Ż¼▓óī”Ė„ĘN▓╗═¼Ą─ĘĮĘ©▀Mąą┴╦īŹ“ׯ¼Ęų╬÷┴╦Ė„ĘNĘĮĘ©Ą─ā×ä▌║═▓╗ūŃĪŻ
ĪĪĪĪ4.2.2 Č╠╬─▒ŠĘųŅÉ
ė╔ė┌╬ó▓®Īóį┌ŠĆšōē»├┐Ģr├┐┐╠Č╝«a╔·┤¾┴┐Ą─öĄō■Ż¼▀@ą®žSĖ╗Ą─öĄō■ę╗ĘĮ├µĮo╚╦éāĦüĒ┴╦Ė³┤¾Ą─▀xō±┐šķgŻ¼Ą½╩Ū├µī”║Ż┴┐ą┼ŽóŻ¼╚╦éā╚ń║╬▀Mąąėą▀xō±Ą─ķåūxģsė÷ĄĮ┴╦Ū░╦∙╬┤ėąĄ─Š▐┤¾╠¶æĪŻę“┤╦ī”ė┌║Ż┴┐Č╠╬─▒ŠĄ─ųžą┬ĮM┐ŚĘų╬÷Š═’@Ą├ĘŪ│Żėą▒žę¬Ż¼ĘųŅÉĘų╬÷╩Ūą┼Žó═┌Š“ųąūŅųžę¬║═ūŅ╗∙▒ŠĄ─╝╝ągų«ę╗ĪŻ
─┐Ū░Č╠╬─▒ŠĄ─ĘųŅÉ╦ŃĘ©ų„ę¬╗∙ė┌ėą▒OČĮīW┴ĢĪŻėą▒OČĮīW┴Ģ▒žĒÜī”ė¢ŠÜśė▒Š▀Mąą╩ų╣żś╦ūóŻ¼▓óŪę×ķ┴╦┤_▒ŻĘųŅÉĄ─┐╔öUš╣ąįŻ¼═∙═∙ąĶ꬜╦ūó┤¾┴┐Ą─śė▒Šū„×ķė¢ŠÜ╝»ĪŻ╚╗Č°┤¾┴┐śė▒ŠĄ─ś╦ūó┘MĢr┘M┴”Ż¼╠žäe╩Ūį┌Č╠╬─▒Š«öųąŻ¼ė╔ė┌Ųõ║Ż┴┐ąįĪó▓╗ęÄĘČąįŻ¼Č╠╬─▒ŠųąĄ─ś╦ūóå¢Ņ}Ė³×ķ═╗│÷ĪŻ
╬─½Ių„ę¬ßśī”Č╠╬─▒ŠĄ─ŽĪ╩Ķąį║═├Ķ╩÷ą┼╠¢╚§Ą─╠ž³cŻ¼╠ß│÷┴╦ę╗ĘN╗∙ė┌╠žš„öUš╣Ą─ųą╬─Č╠╬─▒ŠĘųŅÉĘĮĘ©ĪŻįōĘĮĘ©ų„ę¬└¹ė├ĻP┬ōęÄät═┌Š“╦ŃĘ©═┌Š“ė¢ŠÜ╝»╠žš„ĒŚ║═£yįć╝»╠žš„ĒŚų«ķgĄ─╣▓¼FĻPŽĄŻ¼╚╗║¾└¹ė├Ą├ĄĮĄ─ĻP┬ōęÄätī”£yįć╬─Ön╝»ųąĄ─į~šZ▀Mąą╠žš„öUš╣Ż¼į┌┤╦╗∙ĄA╔Ž▀MąąČ╠╬─▒ŠĘųŅÉŻ╗╬─½Ißśī”Č╠╬─▒ŠĄ─ŽĪ╩Ķąį╠ž³cŻ¼╠ß│÷┴╦┴Ē═Ōę╗ĘNą┬Ą─ĮŌøQĘĮĘ©Ż¼ßśī”├┐ę╗éĆ╠žČ©ŅIė“Ą─ĘųŅÉå¢Ņ}Ż¼╩ūŽ╚▀xō±ę╗éĆūŃē“┤¾ęÄ─ŻĄ─═Ō▓┐öĄō■į┤Ż¼▓óÅ─ųą░l¼FŲõųąĄ─ļ[║¼ų„Ņ}Ż¼ūŅ║¾└¹ė├▀@ą®ļ[║¼ų„Ņ}║═ąĪęÄ─ŻĄ─ś╦ūóė¢ŠÜ╝»▀MąąĘųŅÉŻ╗╬─½IųąųĖ│÷¬Ü┴óų„│╔ĘųĘų╬÷(ICA)į┌║▄ČÓŪķørŽ┬─▄ē“Ė─╔Ų╬─▒ŠĘųŅÉĄ─ą¦╣¹Ż¼Ą½╩Ūė╔ė┌Č╠╬─▒ŠĄ─ŽĪ╩ĶąįŻ¼╦³éāų«ķgŽÓ═¼Ą─į~║▄╔┘Ż¼╦∙ęįų▒Įėį┌Č╠╬─▒Š╔Ž▀Mąą¬Ü┴óų„│╔ĘųĘų╬÷ą¦╣¹▓╗╝čĪŻ╗∙ė┌┤╦Ż¼ū„š▀└¹ė├Øōį┌šZ┴xĘų╬÷(LSA)ī”Č╠╬─▒Š▀MąąöĄō■ŅA╠Ä└ĒŻ¼╚╗║¾į┌┤╦╗∙ĄA╔Žį┘└¹ė├ų„│╔ĘųĘų╬÷Ż¼╚ĪĄ├┴╦▓╗ÕeĄ─ą¦╣¹Ż╗╬─½Ių„ę¬ĮŌøQĄ─╩ŪTwitterŽ¹ŽóĄ─ĘųŅÉå¢Ņ}Ż¼ū„š▀═©▀^ę╗Č©Ą─╦ŃĘ©Ż¼░č├┐éĆTwitterŽ¹Žóė│╔õĄĮūŅŽÓ╦ŲĄ─WikipediaĒō├µ╔ŽŻ¼╚╗║¾└¹ė├┤╦Ēō├µüĒ┤·▒ĒTwitterŽ¹ŽóŻ¼▓ó▀MąąĘųŅÉŻ¼īŹ“×▒Ē├„įōĘĮĘ©▒╚å╬╝āĄ─╗∙ė┌ūųĘ¹┤«ŠÄ▌ŗŠÓļx╗“LSAĄ─ą¦╣¹║├Ż╗ęį═∙Ą─ĘųŅÉ蹊┐ųą├┐ę╗éĆČ╠╬─▒Šų╗┘xėĶę╗éĆŅÉäeŻ¼Č°īŹļH╔ŽŻ¼ę╗éĆ╬─▒Šėą┐╔─▄░³║¼ČÓéĆ▓╗═¼Ą─ų„Ņ}Ż¼╬─½Ių„ę¬čąŠ┐┴╦Č╠╬─▒ŠĄ─ČÓųĄĘųŅÉå¢Ņ}Ż╗×ķ┴╦─▄ē“ī”║Ż┴┐TwitterŽ¹Žó▀Mąąųžą┬ĮM┐ŚŻ¼▒Ńė┌ė├æ¶▀xō±║═×gė[Ż¼╬─½Ißśī”TwitterŽ¹ŽóĄ─╠ž³c╠ß│÷┴╦ę╗éĆą┬Ą─ĘųŅÉĘĮ░ĖĪŻū„š▀╩ūŽ╚═©▀^ė^▓ņ║═Ęų╬÷Ż¼└¹ė├žØ└Ę╦ŃĘ©▀xō±┴╦8éĆ╠žš„Ż¼▓óīó▀@8éĆ╠žš„║═é„ĮyĄ─į~┤³ūėĘĮĘ©▀Mąą┴╦ī”▒╚īŹ“ׯ¼ĮY╣¹▒Ē├„ū„š▀╠ß│÷Ą─ĘĮĘ©Š▀ėą▌^Ė▀Ą─£╩┤_ąįĪŻ
ĪĪĪĪ4.3 ╗∙ė┌WordNetĄ─ęŲäėæ¬ė├Ųź┼õ
įōĘĮĘ©ų„ę¬╩Ū╗∙ė┌ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼Žóėŗ╦ŃŽÓ╦ŲČ╚Ż¼░č├┐ę╗éĆApp┐┤│╔╩Ūę╗éĆė╔├Ķ╩÷ą┼Žó▒Ē╩ŠĄ─╬─ÖnŻ¼└¹ė├é„ĮyĄ─Ž“┴┐┐šķg─Żą═(VSMŻ®Ż╗▀Mąąėŗ╦ŃĪŻ×ķ┴╦ĮŌøQ╬─Önę╗į~ŅlŠžĻćĄ─ŽĪ╩Ķąįå¢Ņ}Ż¼┐╔└¹ė├šZ┴xį~ĄõWordNetüĒöU│õAppĄ─├Ķ╩÷ą┼ŽóĪŻŠ▀¾wīŹ¼F▀^│╠╚ńŽ┬Ż║
a1 Ż¼a2 Ż¼...Ż¼amĘųäe▒Ē╩ŠméĆAppĄ─├Ķ╩÷ą┼ŽóŻ¼├Ķ╩÷ą┼ŽóĮø▀^Ęųį~Īó╚ź│²═Żė├į~║═į~Ė╔╗»Ą╚╠Ä└Ēęį║¾Ż¼╣▓Ą├ĄĮė╔NéĆ▓╗═¼Ą─į~ĮM│╔Ą─╝»║ŽT={t1Ż¼t2Ż¼...Ż¼tn}Ż¼žŁTžŁ=NŻ╗ūŅ║¾Ą├ĄĮ╬─Önį~ŅlŠžĻćWĪŻ

ĪĪĪĪŲõųąŻ¼├┐ę╗ąą┤·▒Ēę╗éĆAppŻ¼├┐ę╗┴ą┤·▒Ēę╗éĆå╬į~Ż¼├┐ę╗į¬╦žwijŻ¼▒Ē╩ŠĄ┌iéĆApp├Ķ╩÷ųąĄ─ÖÓųžŻ¼ėŗ╦ŃĘĮĘ©╚ńŽ┬Ż║
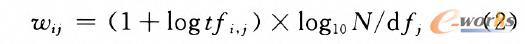
ĪĪĪĪ╚╗║¾╗∙ė┌WordNetŻ¼ėŗ╦Ńį~┼cį~ų«ķgĄ─šZ┴xŽÓ╦ŲČ╚Ż¼Ą├ĄĮį~šZĄ─ŽÓ╦ŲČ╚ŠžĻćQĪŻ
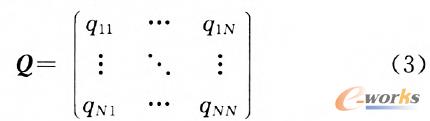
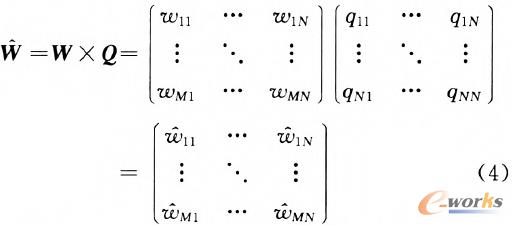
═©▀^╔Ž╩÷▀\╦ŃŻ¼╬─Önę╗į~ŅlŠžĻćĄ─ĘŪ┴Ńį¬╦žį÷ČÓŻ¼ŽĪ╩ĶČ╚ĮĄĄ═ĪŻAppų«ķgĄ─ŽÓ╦ŲČ╚į┌▐DōQ║¾Ą─Ž“┴┐┐šķgųą└¹ė├╩Į(5)▀Mąąėŗ╦ŃĪŻ
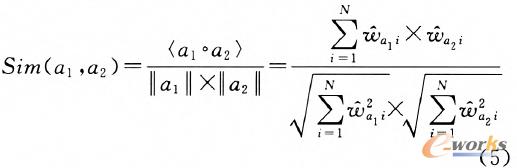
╬ęéā╚╦╣żśŗĮ©┴╦ę╗éĆąĪęÄ─ŻĄ─£yįćöĄō■╝»Ż¼ī”100éĆApp▀Mąą┴╦╚╦╣ż┼ąöÓŻ¼░l¼FŲõųą╣▓ėą89ī”ŽÓ╦ŲĄ─AppŻ¼ī”┤╦Ęųäe└¹ė├VSM─Żą═║═╗∙ė┌WordNetĄ─VSM─Żą═▀Mąąėŗ╦ŃĪŻīŹ“×ĮY╣¹ė├£╩┤_┬╩Īóš┘╗ž┬╩ĪóF-1▀Mąą║Ō┴┐ĪŻ
Å─łD2┐╔ęį┐┤│÷Ż¼└¹ė├šZ┴xį~ĄõWordNet┐╔ęįį÷╝ėAppų«ķgĄ─ŽÓ╦ŲČ╚Ż¼Å─Č°╠ßĖ▀┴╦š┘╗ž┬╩Ż¼Ą½╩Ū£╩┤_┬╩ģs┤¾┤¾Ž┬ĮĄĪŻ═©▀^Ęų╬÷Ż¼£╩┤_┬╩Ž┬ĮĄĄ─ų„ę¬įŁę“╩Ūė╔ė┌App├Ķ╩÷ą┼Žóųą┤µį┌įļę¶öĄō■ĪŻę“┤╦å╬╝ā└¹ė├šZ┴xį~Ąõ¤oĘ©║▄║├ĄžĮŌøQAppĄ─ŽÓ╦ŲČ╚ėŗ╦Ńå¢Ņ}Ż¼▒žĒÜŽļ▐kĘ©Ž¹│²App├Ķ╩÷ųąĄ─įļ궹┼ŽóĪŻ
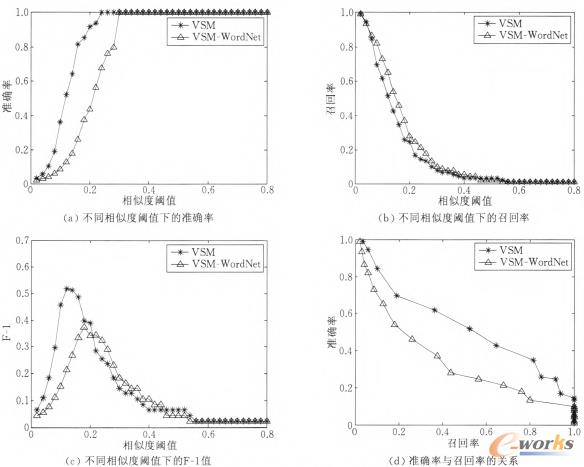
łD2 ╗∙ė┌WordNetĄ─ęŲäėæ¬ė├Ųź┼õ
ĪĪĪĪ4.4 ╗∙ė┌╠žš„į~╠ß╚ĪĄ─ęŲäėæ¬ė├Ųź┼õ
×ķ┴╦Ė─╔ŲęŲäėæ¬ė├Ųź┼õĄ─ą¦╣¹Ż¼ąĶę¬ūRäe│÷App├Ķ╩÷ą┼ŽóųąĄ─╠žš„į~Ż¼▀@ą®╠žš„į~─▄ē“¾w¼FAppĄ─╣”─▄Ż¼Å─Č°░č├Ķ╩÷ą┼ŽóųąĄ─ĘŪ╣”─▄ąįą┼Žó╗“š▀įļę¶öĄō■▀^×VĄ¶ĪŻ═©▀^╔Ņ╚╦ė^▓ņĘų╬÷Ż¼╬ęéā▀xō±5éĆ╠žš„ū„×ķ┼ąöÓę╗éĆį~╩Ūʱ╩Ū╠žš„į~Ą─ę└ō■Ż¼Ęųäe╩ŪtermPOSŻ¼ locInDesŻ¼ isNameTermŻ¼ locRelative-ToNameŻ¼termFreqŻ¼Š▀¾wšf├„╚ń▒Ē3╦∙╩ŠĪŻ
▒Ē3 ╠žš„į~┴ą▒Ē

╬ęéā░č╠žš„į~Ą─┼ąöÓå¢Ņ}┐┤│╔╩Ūę╗éĆĘųŅÉå¢Ņ}Ż¼ų„ę¬═©▀^ęįŽ┬ÄūéĆ▓Į¾EīŹ¼FŻ║(1)ßśī”l00éĆAppĄ─├Ķ╩÷ą┼Žó▀Mąą╩ų╣żś╦ūóŻ¼ę╗╣▓ś╦ūó┴╦2625éĆå╬į~Ż¼╚ń╣¹─│éĆå╬į~į┌ę╗éĆAppųą╩Ū╠žš„į~Ż¼ätś╦ūó×ķ1Ż¼Ę±ätś╦ūó×ķ0Ż╗(2)ėŗ╦Ń│÷├┐éĆå╬į~Ą─╦∙ėąĄ─╠žš„ųĄŻ╗(3)ęį▀@ą®ś╦ūóöĄō■ū„×ķė¢ŠÜ╝»Ż¼Ą├ĄĮę╗éĆĘųŅÉ─Żą═Ż╗(4)└¹ė├įōĘųŅÉ─Żą═╚ź┼ąöÓŲõ╦¹Ą─į~╩Ūʱ╩Ū╠žš„į~ĪŻ
╠žš„į~ĘųŅÉīŹ“×įOų├Ż║į┌2625éĆś╦ūóöĄō■ųą▀xō±2525éĆū„×ķė¢ŠÜ╝»Ż¼100éĆū„×ķ£yįć╝»Ż¼Ęųäe▓╔ė├śŃ╦žžÉ╚~╦╣(Naive Bayesian)║═ų¦│ųŽ“┴┐ÖC(SVM)ĘĮĘ©▀MąąīŹ“ׯ¼ĘųŅÉĮY╣¹╚ń▒Ē4╦∙╩ŠĪŻ
▒Ē4 ĘųŅÉš²┤_┬╩

Å─▒Ē4╬ęéā┐╔ęį┐┤│÷Ż¼śŃ╦žžÉ╚~╦╣ĘųŅÉĄ─š²┤_┬╩▒╚▌^Ą═Ż¼┴Ē═Ō╚ź│²locInDesų«║¾└¹ė├SVMĘųŅÉŻ¼š²┤_┬╩ūŅĖ▀Ż¼ę▓Š═╩ŪšflocInDesī”ė┌╠žš„į~Ą─┼ąöÓŠ▀ėąę╗Č©Ą─žō├µū„ė├Ż¼Ą½ī”ė┌ūŅĮKĄ─AppŽÓ╦ŲČ╚ėŗ╦ŃĮY╣¹Ą─ė░Ēæ▀Ć▓╗┤_Č©Ż¼╦∙ęį╬ęéā▓╔ė├SVMĘĮĘ©Ęųäeį┌╦∙ėą╠žš„║═╚ź│²locInDesęį║¾Ą─ūė╝»╔Ž▀Mąą┴╦īŹ“×ĪŻūŅ║¾ęį╦∙ėąĄ─╠žš„į~×ķŽ“┴┐┐šķgüĒėŗ╦ŃAppĄ─ŽÓ╦ŲČ╚Ż¼īŹ“×ĮY╣¹▒Ē├„Ż¼╚ĪĄ├┴╦▌^║├Ą─ą¦╣¹ĪŻ
Å─łD3┐╔ęį┐┤│÷Ż¼Įø▀^╠žš„į~╠ß╚Īęį║¾Ż¼£╩┤_┬╩║═š┘╗ž┬╩Š∙ėą╦∙╠ßĖ▀Ż¼▓óŪęį┌▓╗┐╝æ]locInDesĄ─ŪķørŽ┬ą¦╣¹Ė³║├Ż¼šf├„å╬į~į┌├Ķ╩÷ųąĄ─╬╗ų├ī”å╬į~╩Ūʱ╩Ū╠žš„į~ø]ėą╠½┤¾žĢ½IŻ¼▓óŪęī”ŽÓ╦ŲČ╚ėŗ╦ŃŠ▀ėąžō├µė░ĒæĪŻ
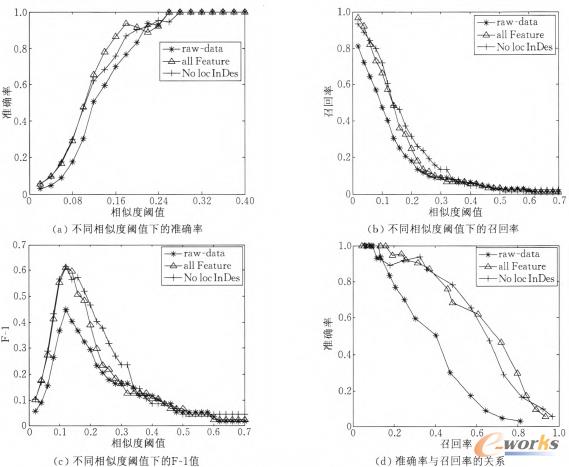
łD3 ╗∙ė┌╠žš„į~╠ß╚ĪĄ─ęŲäėæ¬ė├Ųź┼õ
╔Ž╩÷ā╔ĘNĘĮĘ©Č╝╩Ū╗∙ė┌AppĄ─├Ķ╩÷ą┼Žó▀Mąąėŗ╦ŃĄ─Ż¼ęį║¾īó░čAppĄ─├¹ĘQĪóŅÉäe╝░Ųõ╦¹ŽÓĻPą┼Žóę▓┐╝æ]▀M╚źŻ¼ą¦╣¹┐╔─▄Ģ■Ė³║├ĪŻ
ĪĪĪĪ5.ęŲäėæ¬ė├═Ų╦]┼c╦č╦„
ļSų°ęŲäėæ¬ė├öĄ┴┐Ą─▓╗öÓį÷╝ėŻ¼╚ń║╬Ä═ų·ė├æ¶┐ņ╦┘šęĄĮŽļꬥ─æ¬ė├│╔┴╦ę╗éĆžĮ┤²ĮŌøQĄ─å¢Ņ}Ż¼▓┐ĘųīWš▀ī”ęŲäėæ¬ė├Ą─═Ų╦]╝╝ąg▀Mąą┴╦蹊┐ĪŻShiĄ╚╚╦╩ūŽ╚Ęų╬÷┴╦é„Įy═Ų╦]─Żą═┤µį┌Ą─▓╗ūŃų«╠ÄŻ¼╚ńęįėøæø×ķ╗∙ĄA(Memory-based Models)Ą─ģf═¼▀^×V─Żą═(░³└©ęįė├æ¶×ķ╗∙ĄAĄ─ģf═¼▀^×V║═ęįĒŚ─┐×ķ╗∙ĄAĄ─ģf═¼▀^×V)ī”Įø│Ż│÷¼F╗“▒╚▌^┴„ąąĄ─ĒŚ─┐═Ų╦]ą¦╣¹▒╚▌^║├Ż¼Ą½╩Ūī”ė┌╩╣ė├▓╗╩Ū║▄ŅlĘ▒Ą─ĒŚ─┐═Ų╦]ą¦╣¹▒╚▌^▓ŅŻ╗ļ[šZ┴x─Żą═( Latent Factor Models)Ą─═Ų╦]£╩┤_┬╩▒╚▌^Ą═ĪŻßśī”╔Ž╩÷ā╔ĘN═Ų╦]─Żą═┤µį┌Ą─▓╗ūŃų«╠ÄŻ¼ū„š▀╠ß│÷┴╦ę╗ĘNą┬Ą─═Ų╦]─Żą═—╗∙ė┌ų„│╔ĘųĘų╬÷Ą──Żą═(PCA-based model)ĪŻįō─Żą═╩ūŽ╚└¹ė├ų„│╔ĘųĘų╬÷╝╝ągÅ─öĄō■ųąšęĄĮų„ꬥ─╠žš„Ż¼╚╗║¾į┌ų„ę¬╠žš„Ą─╗∙ĄA╔Žį┘└¹ė├ģf═¼▀^×V─Żą═▀Mąą═Ų╦]ĪŻŲõų„ę¬ā׳c╩Ūī”ė┌▓╗╩Ū║▄┴„ąąĄ─ęŲäėæ¬ė├Š▀ėą▌^║├Ą─═Ų╦]£╩┤_┬╩ĪŻWoerndlĄ╚╚╦ßśī”ęŲäėæ¬ė├╠ß│÷┴╦ę╗ĘN╗∙ė┌ŪķŠ░Ėąų¬Ą─╗ņ║Ž═Ų╦]ŽĄĮyĪŻįō═Ų╦]ŽĄĮyęįé„ĮyĄ─ģf═¼▀^×V╝╝ąg×ķ╗∙ĄAŻ¼░čŪķŠ░ę“╦ž┐╝æ]▀MüĒŻ¼Å─ė├æ¶ĪóĒŚ─┐║═ŪķŠ░3éĆŠSČ╚▀Mąąėŗ╦ŃŻ¼┤¾┤¾╠ßĖ▀┴╦═Ų╦]£╩┤_┬╩ĪŻĄ½╩Ū─┐Ū░┐╝æ]Ą─ŪķŠ░▀Ć▒╚▌^╔┘Ż¼ų„ę¬╩Ūę└ō■Ųõ╦¹ė├æ¶į┌─│éĆ╬╗ų├Ą─ęŲäėæ¬ė├░▓čb║═╩╣ė├Ūķør▀Mąą═Ų╦]Ż¼ęį║¾īó┐╝æ]Ė³ČÓĄ─ŪķŠ░ę“╦žĪŻKaratzoglouĄ╚╚╦ĮY║ŽŪķŠ░ą┼ŽóŻ¼ę▓╠ß│÷┴╦ę╗éĆą┬Ą─ęŲäėæ¬ė├═Ų╦]─Żą═Djinn─Żą═Ż¼įō─Żą═ų„ę¬┐╝æ]╩Ū░čļ[╩ĮĘ┤üöĄō■┐╝æ]▀MüĒŻ¼└¹ė├Åł┴┐ĘųĮŌ╝╝ągī”Djinn─Żą═▀Mąąā×╗»Ż¼īŹ“×ĮY╣¹▒Ē├„Djinn─Żą═Ą─ŲĮŠ∙£╩┤_┬╩(MAP)ę¬▒╚▓╗┐╝æ]ŪķŠ░ą┼ŽóĄ──Żą═Ė▀│÷28%ĪŻYinĄ╚╚╦šJ×ķęŲäėæ¬ė├Ą─═Ų╦]║═Ųõ╦¹ŅIė“Ą─═Ų╦]ėąę╗éĆ▓╗═¼ų«╠Äį┌ė┌Ż║│²┴╦═Ų╦]ė├æ¶Ėą┼d╚żĄ─ęŲäėæ¬ė├═ŌŻ¼▀ĆąĶę¬ßśī”ė├æ¶ęčĮøėąĄ─ęŲäėæ¬ė├═Ų╦]┐╔ęį╠µ┤·Ą─Īóą┬Ą─ęŲäėæ¬ė├ĪŻYinĄ╚╚╦šJ×ķęčėąĄ─ęŲäėæ¬ė├ōĒėąę╗éĆīŹļHØMęŌČ╚ųĄAV(Actual Satisfactory Value)Ż¼ą┬Ą─ęŲäėæ¬ė├ōĒėąę╗éĆ╬³ę²Č╚ųĄTV(Tempting Value)Ż¼ė├æ¶╩ŪʱĖ³ōQ┼fĄ─æ¬ė├Ż¼╚ĪøQė┌AV║═TVĄ─┤¾ąĪĪŻū„š▀ęįė├æ¶Ą─╩╣ė├╚šųŠ×ķ╗∙ĄAöĄō■Ż¼░čAV║═TVū„×ķā╔éĆļ[║¼ģóöĄŻ¼╠ß│÷┴╦ę╗éĆAT─Żą═Ż¼ėŗ╦Ń│÷├┐éĆæ¬ė├Ą─AV║═TVųĄŻ¼▓óįOėŗ┴╦AT┼┼ą“║»öĄĪŻīŹ“×▒Ē├„Ż¼AT─Żą═Ą─═Ų╦]ą¦╣¹▀h║├ė┌é„ĮyĄ─ģf═¼▀^×V╝╝ąg║═ęįā╚╚▌×ķ╗∙ĄAĄ─▀^×V╝╝ągŻ¼╚ń╣¹─▄īóAT─Żą═║═Ųõ╦¹─Żą═ŽÓĮY║ŽŻ¼ą¦╣¹Ģ■Ė³║├ĪŻYanĄ╚╚╦šJ×ķęį═∙Ą─ęŲäėæ¬ė├═Ų╦]ŽĄĮy┤¾Č╝└¹ė├ė├æ¶Ą─Ž┬▌dÜv╩Ę║═ė├æ¶įuārŻ¼īŹļH╔Žė├涎┬▌d┴╦ę╗éĆæ¬ė├Ż¼▓ó▓╗─▄šµš²┤·▒Ēė├æ¶Ż¼Č°ė├æ¶Ą─įuār═∙═∙ėų▒╚▌^ŽĪ╩ĶŻ¼═Ų╦]ą¦╣¹▓╗╝čĪŻę“┤╦╦¹éā░čė├æ¶Ą─╩╣ė├╚šųŠöĄō■║═╗∙ė┌ĒŚ─┐Ą─ģf═¼▀^×V╝╝ągŽÓĮY║ŽŻ¼╠ß│÷┴╦ę╗ĘNéĆąį╗»Ą─ęŲäėæ¬ė├═Ų╦]╝╝ągAppJoyĪŻ ZhuĄ╚╚╦ī”ęŲäėæ¬ė├Ą─ĘųŅÉå¢Ņ}▀Mąą┴╦蹊┐ĪŻ×ķ┴╦╠ßĖ▀ĘųŅÉĄ─£╩┤_ąįŻ¼ū„š▀ī”ęŲäėæ¬ė├Ą─╠žš„ą┼Žó▀Mąą┴╦öUš╣Ż║ę╗╩Ū└¹ė├╦č╦„ę²ŪµüĒöUš╣╬─▒Š╠žš„Ż╗Č■╩ŪÅ─ė├æ¶Ą─╩╣ė├ėøõøųą╠ß╚ĪŪķŠ░╠žš„Ż¼ūŅ║¾░č▀@ą®╠žš„ŠC║ŽŲüĒŻ¼└¹ė├ūŅ┤¾ņž─Żą═ė¢ŠÜ│÷┴╦ę╗éĆęŲäėæ¬ė├ĘųŅÉŲ„ĪŻīŹ“×ĮY╣¹▒Ē├„ŲõĘųŅÉ£╩┤_┬╩ę¬Ė▀ė┌╗∙ė┌į~Ž“┴┐Ą─æ¬ė├ĘųŅÉŲ„(Word Vector based App Classifier)║═╗∙ė┌ļ[║¼ų„Ņ}Ą─æ¬ė├ĘųŅÉŲ„ĪŻ
ļSų°ęŲäėæ¬ė├öĄ┴┐Ą─▓╗į÷╝ėŻ¼ęŲäėæ¬ė├╦č╦„īóįĮüĒįĮųžę¬ĪŻęŲäėæ¬ė├╦č╦„┼cé„ĮyĄ─Web╦č╦„ėąŽÓ╦Ųų«╠ÄŻ¼Ą½ę▓ėą╠ž╩Ōų«╠ÄĪŻęŲäėæ¬ė├╦č╦„ī”╦č╦„ĮY╣¹Ą─┘|┴┐ę¬Ū¾Ė³Ė▀Ż¼ąĶę¬ĘĄ╗žūŅ─▄ē“ØMūŃė├æ¶ąĶŪ¾Ą─╔┘öĄæ¬ė├Ż¼Č°▓╗ąĶę¬ĘĄ╗ž┤¾┴┐Ą─ĮY╣¹Ż╗┴Ē═Ōį┌ęŲäėæ¬ė├╦č╦„ųąŻ¼é„ĮyĄ─ęįĻPµIį~×ķ╗∙ĄAĄ─╦č╦„╝╝ąg¤oĘ©ØMūŃą┬Ą─▓ķįāąĶŪ¾Ż¼ę“×ķė├æ¶═∙═∙▓╗─▄ē“£╩┤_Įo│÷æ¬ė├Ą─├¹ĘQŻ¼ų╗─▄┤¾Ė┼Įo│÷æ¬ė├Ą─╣”─▄Īó╠ž³cŻ¼į┌▀@ĘNŪķørŽ┬Ż¼╚ń║╬─▄ē“£╩┤_Ęų╬÷│÷ė├æ¶Ą─▓ķįāęŌłD▓ó╠ß╣®ØMęŌĄ─ĮY╣¹īóūāĄ├ĘŪ│ŻŠ▀ėą╠¶æąįŻ╗ęŲäėæ¬ė├╦č╦„ĮY╣¹Ą─┼┼├¹ę▓ėą╠ž╩Ōų«╠ÄŻ¼│²┴╦┐╝æ]╦č╦„ĮY╣¹┼cė├æ¶▓ķįāų«ķgĄ─ŽÓĻPąįų«═ŌŻ¼▀ĆąĶę¬┐╝æ]æ¬ė├Ą─┘|┴┐Īó╩▄ÜgėŁ│╠Č╚Ą╚Ųõ╦¹ę“╦žĪŻę“┤╦Ż¼╣”─▄╦č╦„╗“š▀╩ŪšZ┴x╦č╦„īó╩ŪĮŌøQęŲäėæ¬ė├╦č╦„Ą─ę╗éĆėąą¦═ŠÅĮĪŻĄ½╩Ū─┐Ū░▀Ćø]ėą▒╚▌^║├Ą─ĮŌøQĘĮ░ĖĪŻ
ĪĪĪĪ6.ęŲäėæ¬ė├╝»│╔├µ┼RĄ─╠¶æ
─┐Ū░Ż¼ĻPė┌ęŲäėæ¬ė├╝»│╔╝╝ągĄ─蹊┐▀Ć╠Äė┌äéäéŲ▓ĮļAČ╬Ż¼▓óŪęė╔ė┌ęŲäėæ¬ė├▒Š╔ĒĄ─╠ž³cŻ¼į┌ęŲäėæ¬ė├╝»│╔ųą┤µį┌ę╗ŽĄ┴ą╠¶æŻ¼ų„ę¬░³└©ČÓį┤ą┼Žó╝»│╔Īó╣”─▄ą┼Žó│ķ╚Ī║═Į©─ŻĪóęŲäėæ¬ė├Ųź┼õ║═ęŲäėæ¬ė├┼┼├¹Ą╚ĪŻ
ĪĪĪĪ6.1 ČÓį┤ą┼Žó╝»│╔
ęŲäėæ¬ė├╝»│╔Ą─öĄō■ī”Ž¾│²┴╦ęŲäėæ¬ė├Ą─╗∙▒Šī┘ąįų«═ŌŻ¼▀Ć░³└©┼cęŲäėæ¬ė├ŽÓĻPĄ─Ųõ╦¹äėæBą┼ŽóŻ║ė├æ¶ą┼ŽóĪóė├æ¶įušōĪó╔ńĮ╗ŠWĮjųąĄ─ĘųŽĒą┼ŽóĄ╚ĪŻ▀@ą®ą┼Žóī”Ė─╔ŲęŲäėæ¬ė├Ą─╦č╦„║══Ų╦]ą¦╣¹Š▀ėąųžę¬ū„ė├ĪŻ╚╗Č°▀@ą®ą┼Žó═∙═∙┤µį┌ė┌▓╗═¼Ą─öĄō■į┤ųąŻ¼╚ńęŲäėæ¬ė├Ą─╗∙▒Šī┘ąįą┼Žó┤¾Č╝┤µį┌ė┌Ė„┤¾æ¬ė├╔╠ĄĻ╗“š▀▓┐ĘųęŲäėæ¬ė├╝»│╔ŠWšŠŻ¼Č°ŽÓĻPĄ─ė├æ¶įušōĪó╔ńĮ╗ŠWĮjĘųŽĒą┼ŽóĄ╚ät┤µį┌ė┌Ųõ╦¹ŠWšŠųąŻ¼▓╗═¼Ą─öĄō■į┤Š▀ėą▓╗═¼Ą─Ēō├µĮYśŗŻ¼╚ń║╬įOėŗŠ▀ėąūį▀mæ¬─▄┴”Ą─│ķ╚ĪĘĮĘ©╩Ūę╗éĆŠ▐┤¾Ą─╠¶æĪŻŲõ┤╬ęŲäėæ¬ė├ŽÓĻPĄ─öĄō■į┤┤¾Č╝Š▀ėąWeb2.0Ą─╠žš„Ż¼╦∙ęįöĄō■į┤ųąĒō├µĄ─ĮYśŗĮø│ŻĢ■░l╔·ūā╗»Ż¼╚ń║╬╩╣Ą├öĄō■│ķ╚ĪĘĮĘ©į┌Ēō├µĮYśŗ░l╔·ūā╗»Ģr╚į─▄ē“└^└m╣żū„ę▓╩Ūę╗éĆųžę¬Ą─蹊┐ā╚╚▌ĪŻĻPė┌ČÓį┤ą┼ŽóĄ─╝»│╔Ż¼▓┐ĘųīWš▀ęčĮøū÷┴╦蹊┐ĪŻSpiegelĄ╚╚╦║═SzomszoŻ║Ą╚╚╦×ķ┴╦Ė─╔ŲļŖė░═Ų╦]ą¦╣¹Ż¼ćLįćīóIMDB║═NetflixĄ─öĄō■▀Mąą╝»│╔ĪŻIMDB╩Ūę╗éĆį┌ŠĆĄ─ļŖė░ą┼Žó╣▓ŽĒŠWšŠŻ¼╦³į╩įSė├æ¶ī”ė░Ų¼╠Ē╝ėś╦║ׯ¼üĒ├Ķ╩÷ė░Ų¼Ą─č▌åTą┼ŽóĪóŪķ╣ØĪó╣╩╩┬Ąž³cĄ╚ĪŻNetFlix╩Ūę╗éĆį┌ŠĆęĢŅlūŌ┘UŠWšŠŻ¼ė├æ¶┐╔ęįī”┐┤▀^Ą─ęĢŅl┤“ĘųĪŻSpiegelĄ╚╚╦║═SZOITISZOŻ║Ą╚╚╦īóIMDBĄ─ś╦║׹┼Žó║═NetflixĄ─┤“Ęųą┼Žó▀Mąą╝»│╔Ż¼┤¾┤¾╠ßĖ▀┴╦═Ų╦]Ą─ą¦╣¹ĪŻ
ĪĪĪĪ6.2 ╣”─▄ą┼Žó│ķ╚Ī┼cĮ©─Ż
╣”─▄ą┼Žó│ķ╚Īę▓╩Ūę╗éĆśOŠ▀╠¶æąįĄ─å¢Ņ}Ż¼ī”ęŲäėæ¬ė├Ą─╦č╦„ą¦╣¹Š▀ėąųžę¬ė░ĒæĪŻé„ĮyĄ─WeböĄō■│ķ╚Ī╝╝ąg┐╔ęįÅ─░ļĮYśŗ╗»öĄō■ųą│ķ╚Ī│÷┼cæ¬ė├ŽÓĻPĄ─ī┘ąįą┼ŽóŻ¼╚ń├¹ĘQĪóŅÉäeĪó├Ķ╩÷ĪóārĖ±Ą╚Ż╗Ą½╩ŪęŲäėæ¬ė├Ą─╣”─▄ąįą┼ŽóĖ³×ķųžę¬Ż¼▒╚╚ńæ¬ė├─▄īŹ¼F──ą®╣”─▄?ū÷Ą├į§├┤śė?╚ń║╬╩╣ė├Ą╚?▀@ą®╣”─▄ąįą┼Žó╩Ū╣”─▄╦č╦„Ą─╗∙ĄAŻ¼ī”╠ßĖ▀╣”─▄╦č╦„Ą─┘|┴┐ų┴ĻPųžę¬ĪŻ╚╗Č°Ż¼╣”─▄ąįą┼Žó═∙═∙ļ[▓žį┌ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼ŽóĪóė├æ¶įušōĄ╚ĘŪĮYśŗ╗»ą┼ŽóųąŻ¼é„ĮyĄ─WeböĄō■│ķ╚Ī╝╝ąg¤oĘ©Å─ĘŪĮYśŗ╗»ą┼Žóųą│ķ╚ĪŽÓæ¬Ą─ĮYśŗ╗»ą┼ŽóĪŻļm╚╗ęčĮøėąę╗ą®ūį╚╗šZčį╠Ä└ĒĄ─ŽÓĻP╝╝ąg┐╔ęįÅ─ĘŪĮYśŗ╗»ą┼Žóųą▀Mąąą┼Žó╠ß╚ĪŻ¼Ą½╩Ū▀Ć▓╗─▄ų▒Įėæ¬ė├ė┌┤╦Ż¼ų„ę¬įŁę“į┌ė┌ęŲäėæ¬ė├Ą─├Ķ╩÷ą┼Žóęį╝░ŽÓĻPė├æ¶įušōĄ╚Š▀ėąūį╝║Ą─╠ž³cŻ¼╚ń╬─▒ŠČ╠ąĪĪóšZĘ©▓╗ęÄätĄ╚ĪŻ
ęŲäėæ¬ė├╝»│╔Ą─ų„ę¬─┐Ą─ų«ę╗Š═╩Ū╠ß╣®Ė▀┘|┴┐Ą─╦č╦„Ę■䚯¼╩╣ė├æ¶─▄ē“Ą├ĄĮšµš²ØMūŃīŹļHąĶŪ¾Ą─ĮY╣¹ĪŻęŲäėæ¬ė├╦č╦„║═é„Įy╦č╦„Ą─ūŅ┤¾ģ^äeį┌ė┌Ż║é„Įy╦č╦„ų„ę¬╩ŪęįĻPµIį~Ųź┼õ×ķų„Ż¼Č°ĻPµIį~Ųź┼õį┌ęŲäėæ¬ė├╦č╦„ųąą¦╣¹ĘŪ│Ż▓╗║├Ż¼─┐Ū░Äū┤¾ęŲäėæ¬ė├╔╠ĄĻ╠ß╣®Ą─╦č╦„╣”─▄Č╝▓╗─▄┴Ņ╚╦ØMęŌĪŻ─┐Ū░ęčėą║▄ČÓ╣½╦Š╔µūŃApp╦č╦„╩ął÷Ż¼╚ń╠ß╣®╣”─▄╦č╦„Ą─App╦č╦„ę²ŪµQuixeyŻ¼░┘Č╚ę▓═Ų│÷┴╦App╦č╦„ŲĮ┼_ĪŻĄ½╩Ū─┐Ū░Ė„╣½╦Š╦∙▓╔ė├Ą─App╦č╦„╝╝ąg▓óø]ėąī”═Ō╣½▓╝Ż¼īWągĮńĻPė┌App╦č╦„▀Ćø]ėąŽÓĻPĄ─蹊┐ĪŻ╚╦éāį┌╦č╦„æ¬ė├Ģr═∙═∙▓╗ų¬Ą└Ųõ£╩┤_├¹ūųŻ¼ŽŻ═¹╦č╦„│÷─▄ē“═Ļ│╔─│ĘN╚╬äšĪóŠ▀éõ─│ĘN╣”─▄Ą─▄ø╝■Ż¼╚ńė^┐┤NBA▒╚┘ÉĪóęĢŅlŠÄ▌ŗĪóīżšęūŅĮ³Ą─│¼╩ąĄ╚Ż¼ßśī”▀@ą®▓ķįāŻ¼é„Įy╦č╦„¤oĘ©╠ß╣®║▄║├Ą─ĮY╣¹ĪŻ╣”─▄Į©─Ż╩ŪĮŌøQ▀@ę╗å¢Ņ}Ą─║╦ą─ĪŻ
╣”─▄Į©─ŻĄ─ų„ę¬─┐Ą─╩Ū╠ß╣®Ė▀┘|┴┐Ą─╦č╦„Ę■䚯¼─▄ē“īŹ¼F╗∙ė┌╣”─▄Ą─╦č╦„ĪŻį┌öĄō■│ķ╚ĪļAČ╬Ż¼═©▀^Ė„ĘN│ķ╚Ī╝╝ągŻ¼Ą├ĄĮ┴╦ęŲäėæ¬ė├Ą─╗∙▒Šī┘ąįą┼ŽóĪó╣”─▄ą┼ŽóĪóįušōą┼Žóęį╝░ė├æ¶öĄō■Ż¼╣”─▄Į©─Żų„ę¬╩Ūęį╣”─▄×ķ║╦ą─Ż¼įOėŗę╗ĘN║Ž▀mĄ─öĄō■─Żą═Ż¼░č╔Ž╩÷Ė„ĘNą┼Žó▀Mąąėąą¦Ą─▒Ē╩ŠĪóĮM┐Ś┼c┤µā”Ż¼öĄō■┐šķg╝╝ąg║═šZ┴xŠW╝╝ąg╩Ū╣”─▄Į©─Ż┐╔ęįĮĶĶb║═ģó┐╝Ą─ā╔éĆ╝╝ągŻ╗═¼ĢrŻ¼×ķ┴╦╠ßĖ▀╦č╦„Ą─ą¦┬╩Ż¼▒žĒÜĖ∙ō■ą┬Ą─öĄō■─Żą═Ą─╠ž³cįOėŗĖ▀ą¦Ą─╦„ę²▓▀┬įĪŻ
ĪĪĪĪ6.3 ęŲäėæ¬ė├Ųź┼õ
ęŲäėæ¬ė├Ųź┼õų„ę¬╩Ūė├üĒ┼ąöÓā╔éĆæ¬ė├│╠ą“į┌╣”─▄╔Ž╩ŪʱŽÓ╦ŲŻ¼╩ŪīŹ¼FęŲäėæ¬ė├▀węŲĪóęŲäėæ¬ė├═Ų╦]Ą─╗∙ĄAŻ¼╩Ūę╗éĆųžę¬Ą─蹊┐ā╚╚▌Ż¼ėą║▄ČÓĄ─æ¬ė├ł÷Š░ĪŻ
ęŲäėæ¬ė├Ųź┼õ┼cīŹ¾wūRäeŠ▀ėąę╗Č©Ą─ŽÓ╦ŲąįĪŻīŹ¾wūRäeų„ę¬ė├üĒ┼ąöÓā╔éĆ▓╗═¼Ą─öĄō■ėøõø╩Ūʱ┤·▒Ē═¼ę╗éĆīŹ¾wŻ¼─┐Ū░ęčĮøėą┤¾┴┐Ą─ŽÓĻP蹊┐╣żū„ĪŻ░┤šš╦∙╩╣ė├Ą─╝╝ąg▓╗═¼┐╔ęįĘų×ķęįŽ┬ÄūŅÉŻ║Ė┼┬╩Ųź┼õ─Żą═Īó▒OČĮ║═░ļ▒OČĮīW┴ĢĘĮĘ©Īóų„äėīW┴Ģ╝╝ągĪó╗∙ė┌ŠÓļxĄ─╝╝ągĪó╗∙ė┌ęÄätĄ─ĘĮĘ©║═¤o▒OČĮīW┴ĢĄ─ĘĮĘ©ĪŻīŹ¾wūRäeų„ę¬╩Ū╗∙ė┌īŹ¾wĄ─ī┘ąįą┼Žó▀MąąŽÓ╦ŲČ╚▒╚▌^Ż¼Č°ęŲäėæ¬ė├Ųź┼õ▀^│╠ųąŻ¼│²┴╦┐╝æ]ī┘ąįą┼ŽóĄ─ŽÓ╦ŲČ╚ų«═ŌŻ¼æ¬ė├│╠ą“Ą─╣”─▄ŽÓ╦ŲČ╚Ė³×ķųžę¬Ż¼╦∙ęįé„ĮyĄ─īŹ¾wūRäe╝╝ąg▓ó▓╗─▄ų▒Įėæ¬ė├ė┌ęŲäėæ¬ė├Ųź┼õĪŻ
╩ūŽ╚Ż¼ī┘ąį▀xō±╩ŪęŲäėæ¬ė├Ųź┼õĄ─╩ūę¬╚╬äšĪŻ├┐éĆæ¬ė├Č╝ėą║▄ČÓī┘ąįą┼ŽóŻ¼╚ń├¹ĘQĪóŅÉäeĪóÖCą═ĪóārĖ±Īó╣”─▄├Ķ╩÷Ą╚Ż¼╚╗Č°▓ó▓╗╩Ū╦∙ėąĄ─ī┘ąįČ╝ī”æ¬ė├Ųź┼õŲš²├µū„ė├Ż¼╦∙ęįąĶę¬Å─▒ŖČÓĄ─ī┘ąįųą▀x│÷─▄Ę┤ė│æ¬ė├╣”─▄ŽÓ╦ŲąįĄ─ī┘ąįŻ╗
Ųõ┤╬Ż¼Č╠╬─▒ŠĄ─ŽÓ╦ŲČ╚ėŗ╦Ńę▓╩Ūę╗éĆśOŠ▀╠¶æąįĄ─蹊┐ā╚╚▌ĪŻ─┐Ū░ęčĮøėąę╗ą®čąŠ┐š▀ī”ŠWĮjČ╠╬─▒Š▀Mąą┴╦ę╗ą®čąŠ┐Ż¼░³└©╗∙ė┌šZ┴xĄ─ĘĮĘ©Īó╗∙ė┌Ė┼┬╩ų„Ņ}─Żą═Ą─ĘĮĘ©Īó╗∙ė┌╠žš„öUš╣Ą─ĘĮĘ©Ą╚CzarĪŻĄ½╩Ū▀@ą®ĘĮĘ©▓óø]ėą┐╝æ]ęŲäėæ¬ė├├Ķ╩÷ą┼ŽóĄ─╠žČ©▒Ē▀_ĘĮ╩ĮŻ¼╦∙ęį¤oĘ©╚ĪĄ├▌^║├Ą─ėŗ╦Ńą¦╣¹ĪŻ
┴Ē═ŌŻ¼į┌▀MąąęŲäėæ¬ė├Ųź┼õĄ─▀^│╠ųąŻ¼│²┴╦┐╝æ]æ¬ė├▒Š╔ĒĄ─╣”─▄ŽÓ╦Ųąįų«═ŌŻ¼═∙═∙▀ĆąĶę¬┐╝æ]ė├æ¶Ą─╩╣ė├┴ĢæTĪóéĆ╚╦É█║├Ą╚ą┼ŽóŻ╗═¼Ģr▀ĆąĶę¬┐╝æ]æ¬ė├┼cė├æ¶ęčėąĄ─æ¬ė├ų«ķgĄ─ŽÓ╗źģfū„ĻPŽĄŻ¼æ¬ė├▒╦┤╦ų«ķgĄ─ŽÓ╗źė░ĒæĄ╚ĪŻÅ─Č°×ķė├æ¶╠ß╣®Ė³╝ėųŪ─▄║══Ļ╔ŲĄ─Ę■äšĪŻ
ĪĪĪĪ6.4 ęŲäėæ¬ė├┼┼├¹
į┌ęŲäėæ¬ė├╝»│╔ŽĄĮyųąŻ¼ūŅĮKĄ──┐Ą─╩Ū×ķė├æ¶╠ß╣®ęŲäėæ¬ė├Ą─╦č╦„║══Ų╦]Ę■䚯¼ę“┤╦ęŲäėæ¬ė├Ą─┼┼├¹ę▓╩Ūę╗éĆųžę¬Ą─蹊┐å¢Ņ}ĪŻæ¬ė├Ą─┼┼├¹│²┴╦┐╝æ]┼c▓ķįāĻPµIį~Ą─Ųź┼õ│╠Č╚ų«═ŌŻ¼▀ĆąĶę¬┐╝æ]Ųõ╦¹ŽÓĻPą┼ŽóŻ¼╚ńė├æ¶Ą─Ų½║├Īóė├æ¶▓ķįāęŌłDĄ╚Ż¼ąĶę¬īó▀@ą®ą┼ŽóŠC║Ž┐╝æ]Ż¼įOėŗę╗éĆ║Ž└Ēėąą¦Ą─┼┼├¹║»öĄĪŻ═¼Ģrė╔ė┌ŠWĮją┼ŽóŠ▀ėąĢrūāąįŻ¼¼Fį┌▒╗ė├涎▓É█Ą─æ¬ė├Ż¼ļSų°ĢrķgĄ─═ŲęŲ┐╔─▄ūāĄ├▓╗─Ū├┤╩▄╚╦Ž▓É█Ż¼æ¬ė├Ą─┼┼├¹┐╔─▄ę▓Ģ■ļSĢrķg░l╔·ūā╗»Ż¼╦∙ęį╚ń║╬ī”▀@ą®ą┼Žó▀MąąäėæBĄ─Ė³ą┬ŠSūoŻ¼ę▓╩Ūę╗éĆŅHŠ▀╠¶æąįĄ─å¢Ņ}ĪŻ
ĪĪĪĪ6.5 ęŲäėæ¬ė├ā╚öĄō■╝»│╔┼c╦č╦„
─┐Ū░▒Š╬─ųą╦∙ĻPūóĄ─╝»│╔ī”Ž¾ų„ę¬╩ŪęŲäėæ¬ė├Ą─ī┘ąįą┼Žóęį╝░Ųõ╦¹ŽÓĻPą┼ŽóŻ¼╚ńė├æ¶įušōĪó╔ńĮ╗ŠWĮjĘųŽĒą┼ŽóĄ╚Ż¼▀@ą®┐╔ęįšJ×ķ╩ŪęŲäėæ¬ė├Ą─═Ōį┌ą┼ŽóĪŻ╚╗Č°Ż¼ī”ė┌ė├æ¶üĒųvŻ¼ęŲäėæ¬ė├ā╚▓┐╦∙░³║¼Ą─ā╚╚▌Ė³žSĖ╗ĪóārųĄĖ³┤¾ĪŻ╚ń╣¹─▄ē“░č▒ŖČÓęŲäėæ¬ė├ā╚▓┐Ą─ą┼Žóėąą¦Ąž╝»│╔ŲüĒŻ¼×ķė├æ¶╠ß╣®Įyę╗Ą─╦č╦„Ę■䚯¼ī”ė├æ¶īóŠ▀ėąųžę¬Ą─ęŌ┴xĪŻ┼cé„ĮyĄ─ŠWĒōöĄō■ŽÓ▒╚Ż¼ęŲäėæ¬ė├ā╚▓┐ą┼ŽóĄ─╝»│╔┼c╦č╦„Š▀ėąę╗ą®ą┬Ą─╠¶æĪŻą┼Žó½@╚Ī▒╚▌^└¦ļyŻ║ęŲäėæ¬ė├ā╚Ą─ą┼Žó═∙═∙▒╗░³╔Ž┴╦═ŌÜżŻ¼¤oĘ©╩╣ė├é„ĮyĄ─╦č╦„┼└Žx╝╝ągų▒Įėūź╚ĪŻ╗öĄō■Ė±╩ĮĄ─«ÉśŗąįŻ║▓╗═¼Ą─ęŲäėæ¬ė├Ż¼Ųõā╚▓┐Ą─öĄō■Ė±╩Į═∙═∙▓╗ę╗śėŻ¼▓óŪę┤µį┌┤¾┴┐Ą─įļę¶öĄō■Ż¼ŲõöĄō■│ķ╚ĪĘĮ╩Į┼cŠWĒōöĄō■│ķ╚ĪŽÓ▒╚Ė³×ķÅ═ļsĪŻ
ĪĪĪĪ7.ĮY╩°šZ
─┐Ū░ęŲäė╗ź┬ōŠWĄ─┴„┴┐┐ņ╦┘į÷╝ėŻ¼╬┤üĒ▒žīó│¼▀^é„Įy╗ź┬ōŠWŻ¼Č°ęŲäėæ¬ė├ųØu│╔×ķęŲäė╗ź┬ōŠWĄ─ų„ę¬Įė╚╦ĘĮ╩ĮĪŻ×ķ┴╦ĀÄŖZė├æ¶Ż¼ļŖą┼▀\ĀI╔╠Īó╩ųÖCųŲįņ╔╠Īó╗ź┬ōŠWĘ■äš╠ß╣®╔╠ęį╝░Ė„éĆ▓╗═¼Ą─Ų¾śI╝Ŗ╝Ŗ═Ų│÷ūį╝║Ą─ęŲäėæ¬ė├Ż¼ęŲäėæ¬ė├öĄ┴┐│╩¼F▒¼š©╩Įį÷ķLĪŻ╚╗Č°ļSų°ęŲäėæ¬ė├öĄ┴┐Ą─▓╗öÓį÷╝ėŻ¼ĮoęŲäėæ¬ė├Ą─╦č╦„║══Ų╦]ĦüĒ┴╦║▄┤¾Ą─└¦ļyĪŻęŲäėæ¬ė├╝»│╔╩ŪĖ─╔ŲęŲäėæ¬ė├╦č╦„║══Ų╦]ą¦╣¹Ą─ę╗éĆėąą¦═ŠÅĮĪŻ─┐Ū░ĻPė┌ęŲäėæ¬ė├╝»│╔Ż¼īWągĮń▀Ćø]ėąķ_š╣ŽĄĮy╔Ņ╚╦Ą─蹊┐ĪŻ▒Š╬─╠ß│÷┴╦ęŲäėæ¬ė├╝»│╔Ą─╗∙▒Š┐“╝▄Ż¼ī”ŲõųąĄ─ĻPµI╝╝ąg╚ńöĄō■│ķ╚ĪĪóęŲäėæ¬ė├Ųź┼õĪóęŲäėæ¬ė├═Ų╦]Ą╚▀Mąą┴╦Ęų╬÷Ż¼ī”¼FėąĄ─╣żū„▀Mąą┴╦Üw╝{┐éĮYŻ╗ūŅ║¾ųĖ│÷┴╦ęŲäėæ¬ė├╝»│╔ųąĄ─╚¶Ė╔╠¶æąįå¢Ņ}ĪŻ╬┤üĒęŲäėæ¬ė├Ą─öĄ┴┐īó│ų└mį÷╝ėŻ¼│╔×ķ╚╦éā½@╚Īą┼ŽóĄ─ų„ę¬═ŠÅĮŻ¼╚╗Č°ŲõöĄ┴┐Ą─į÷╝ėę▓▒žīóĦüĒę╗ŽĄ┴ą╠¶æŻ¼ėą║▄ČÓå¢Ņ}ųĄĄ├蹊┐ĪŻ╬ęéāī”ęŲäėæ¬ė├Ą─╝»│╔ĪóŲź┼õĪó═Ų╦]Ą╚╝╝ąg▀Mąą┴╦Ęų╬÷Ż¼ŽŻ═¹─▄×ķŽÓĻP蹊┐╚╦åT╠ß╣®ģó┐╝ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ęŲäėæ¬ė├╝»│╔Ż║┐“╝▄Īó╝╝ąg┼c╠¶æ
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839613327.html