CRM(┐═æ¶ĻPŽĄ╣▄└Ē)╩Ūę╗éĆ░³└©ų¬ūR═┌Š“Īó╩ął÷ęÄäØĪó┐═æ¶╗źäėĪóĘų╬÷┼cą▐š²Č°čŁŁh▓╗ęčĄ─▀^│╠Ż¼ŲõųąŻ¼ų¬ūR═┌Š“▀^│╠░³└©╩ął÷┤_šJĪó┐═æ¶ģ^Ęųęį╝░┐═æ¶ŅA£yĪŻ┼c─▄ĦüĒ└¹ØÖĄ─┐═æ¶Į©┴ó│ųŠ├Ą─║Žū„ĻPŽĄ╩ŪCRMĄ─║╦ą─Ż¼į┌Į©┴ó▀@ĘN│ųŠ├Ą─║Žū„ĻPŽĄųąŻ¼ŅA£yŲų°┼eūŃ▌pųžĄ─ū„ė├ĪŻŅA£yĘĮĘ©Ą─▀xō±▓╗āH┼cŅA£yī”Ž¾║═─┐ś╦Ą─ąį┘|ėąĻPŻ¼┼c┐╔─▄╩š╝»ĄĮĄ─öĄō■ĀŅørėąĻPŻ¼ę▓┼cŅA£yĄ─ę¬Ū¾║═Śl╝■ėąĻPĪŻ▀xō±║Ž▀mĄ─═┌Š“╝╝ąg║═╣żŠ▀Ż¼ī”ė┌╬┤üĒŽĄĮyĄ─ąį─▄║═┐╔┐┐ąįėąųž┤¾ė░ĒæŻ¼▓╗═¼Ą─╝╝ągĘĮ░Ė«a╔·Ą─ĮY╣¹─Żą═ėą║▄┤¾▓╗═¼Ż¼─Żą═ĮY╣¹Ą─┐╔└ĒĮŌąįę▓┤µį┌║▄┤¾▓Ņ«ÉĪŻ
1 ŅA£y─Żą═Ą─▀xō±ę“╦ž
į┌▀xō±ę╗éĆŅA£y─Żą═Ą─Ģr║“Ż¼ę¬┐╝æ]įSČÓę“╦žĪŻ▀@ą®ę“╦ž░³└©öĄō■─Ż╩ĮĪóŅA£y─┐Ą─ĪóŅA£yŠ½Č╚ĪóŅA£yĄ─ūŅ▀hŲ┌Ž▐Īó▓╔ė├┤╦ŅA£y─Żą═╦∙ꬥ─┘Mė├Ż¼ęį╝░æ¬ė├▀@éĆŅA£y─Żą═Ą─ļyęū│╠Č╚Ą╚ĪŻ
1.1 öĄō■─Ż╩Į(╝┤öĄō■Ą─╠žš„)
į┌▀xō±ę╗éĆŅA£y─Żą═Ą─Ģr║“Ż¼öĄō■─Ż╩Į╩Ūę╗éĆūŅų„ꬥ─ę“╦žĪŻī”═¼ę╗ĘNöĄō■─Ż╩Į┐╔ęįæ¬ė├ÄūéĆ▓╗═¼Ą─ŅA£yĘĮĘ©Ż¼Č°▓╗═¼Ą─ŅA£yĘĮĘ©Č╝ėąĖ„ūį▀mæ¬Ą─öĄō■╠žš„ĪŻ
1.2 ŅA£y─┐Ą─
ŅA£yĄ──┐Ą─Ż¼ę▓Š═╩ŪŅA£yĄ─ĮY╣¹ū÷╩▓├┤ė├ĪŻ
1.3 ŅA£yŠ½Č╚
ŅA£yŠ½Č╚ę¬┐╝æ]3éĆå¢Ņ}Ż║į┌┤_Č©Ą─ŁhŠ│Ž┬Ż¼╩╣ė├─│ę╗ĘNĄõą═Ą─ŅA£y─Żą═─▄ē“▀_ĄĮČÓĖ▀Ą─Š½┤_Č╚Ż╗į┌▀@éĆŁhŠ│Ž┬Ż¼▓╔ė├╩▓├┤śėĄ─ĘĮĘ©─▄ē“╠ßĖ▀ŅA£yŠ½Č╚Ż╗╚ń╣¹┤µį┌╚¶Ė╔ĘN╠ßĖ▀ŅA£yŠ½Č╚Ą─ĘĮĘ©Ż¼╚ń║╬▀xō±ę╗éĆ▀m«öĄ─ĘĮĘ©ĪŻ
1.4 ŅA£yĄ─ūŅ▀hŲ┌Ž▐
ŅA£yĄ─ūŅ▀hŲ┌Ž▐║═öĄō■─Ż╩Įėąų°├▄ŪąĄ─ĻPŽĄŻ¼▓╗═¼ėŗäØŲ┌Ž▐Ą─ųŲČ©Ż¼░³└©▓╗═¼Ą─öĄō■─Ż╩Į╠žš„ĪŻī”ė┌▓╗═¼Ų┌Ž▐Ą─ŅA£yŻ¼Ė„ĘNę“╦žĄ─ųžę¬│╠Č╚ę▓╩Ū▓╗ę╗śėĄ─ĪŻ╚╬║╬ę╗ĘNŅA£yĘĮĘ©Ą─▀mė├ąįę└┘ćė┌ŅA£yĄ─ūŅ▀hŲ┌Ž▐Ż¼Č°Ūę▀Ć║═ŅA£yŠ½Č╚Īó┘Mė├ęį╝░Ųõ╦¹ę“╦žėąĻPĪŻ
1.5 ŅA£y┘Mė├
░³└©čąŠ┐║═ķ_░l─Żą═Ą─┘Mė├ĪóöĄō■Ą─╩š╝»║═ā”┤µ┘Mė├Ż¼╝░Ę┤Å═æ¬ė├▀@éĆ─Żą═Ą─┘Mė├ĪŻ
2 ŅA£y─Żą═Ą─öĄō■╠ž³c
│Żė├ė┌CRMĄ─ŅA£y─Żą═ėąŻ║╗žÜwŅA£yĪóøQ▓▀śõĪó╔±ĮøŠWĮjĪóŠ█ŅÉ║═ūŅĮ³ÓÅ╝╝ąg╝░ęÄät═Ų└ĒŻ¼Ųõ╦¹Ą─ŅA£y─Żą═(ĘĮĘ©)▀ĆėąĢrķgą“┴ąĘų╬÷Īó▀zé„╦ŃĘ©Īó┤ų▓┌╝»└ĒšōĪó─Ż║²└ĒšōĄ╚Ż¼Č°öĄō■─Ż╩Į╩Ū▀xō±ę╗éĆŅA£y─Żą═ĢrūŅų„ꬥ─ę“╦žŻ¼ę“┤╦Ż¼Ž┬├µ░┤Č©┴┐öĄō■(ųĖė├Č©ŠÓ╗“Č©▒╚│▀Č╚üĒ║Ō┴┐Ą─öĄō■)║═ĘŪČ©┴┐öĄō■(ė├Č©ŅÉ╗“Č©ą“│▀Č╚üĒ║Ō┴┐Ą─öĄō■)üĒ▀Mąąī”─Żą═öĄō■Ą─╗∙▒ŠĘųŅÉŻ¼Ęųäeī”ę╗ą®ŅA£y─Żą═Ą─öĄō■╠ž³c▀MąąĘų╬÷Ż║
2.1 ╗žÜwŅA£y
╗žÜwĘų╬÷Ą─öĄō■╩Ūģ^ķg│▀Č╚(ėųĘQČ©ŠÓ│▀Č╚)Ż¼╦³Ą─ŅA£yųĄ╩Ū▀B└mĄ─ĪŻ
2.2 øQ▓▀śõ
øQ▓▀śõ║▄▀m║Ž╠Ä└ĒĘŪöĄųĄą═öĄō■Ż¼╦³┐╔ęį║▄╚▌ęūĄ─ė├ė┌ĘNŅÉūųČ╬Ż¼Ą½«öĘNŅÉĄ─ųĄ▌^ČÓĄ─Ģr║“Ż¼ą¦╣¹┐╔─▄Ģ■▒╚▌^▓ŅŻ¼╚ń╣¹Ž▐ųŲĘųų”Ą─éĆöĄĪŻøQ▓▀śõĄ─ą¦╣¹▀Ć╩Ū▓╗ÕeĄ─ĪŻøQ▓▀śõŅA£y▀B└mī┘ąįųĄĢrąį─▄▌^▓ŅŻ╗▓╗─▄Ęų╬÷║═ĢrķgėąĻPĄ─ī┘ąįūā┴┐ĪŻ╚¶ė├øQ▓▀śõüĒ▀MąąĘųŅÉŻ¼ąĶę¬▒ŻūCöĄō■Š▀ėą╗ź│Ōąį║══Ļš¹ąįĪŻ
2.3 ╔±ĮøŠWĮj
┐╔ė├ė┌ĘųŅÉĪóŅA£yĪó╣└ųĄ║═Š█ŅÉŻ¼ę╗░Ń▀mė├ė┌ĮYśŗ╗»öĄō■ĪŻ«ö▌ö╚ļ×ķöĄųĄūųČ╬ĢrŻ¼╔±Įøį¬ŠWĮjīó╦∙ėą▌ö╚ļ▐D╗»ĄĮ0Ī½1ų«ķgŻ╗«ö▌ö╚ļ╩ŪĘNŅÉūųČ╬ĢrŻ¼╔±Įøį¬ŠWĮj┐╔ęįīóĘNŅÉūųČ╬▐D╗»│╔öĄųĄūųČ╬Ż¼Ą½▀@śėŠ═ĮoĘNŅÉūųČ╬ÅŖ╝ė┴╦ę╗éĆŽ╚║¾┤╬ą“Ż╗Č°«öėøõøųąĄ─ūųČ╬║▄ČÓųŌĪŻ╔±Įøį¬ŠWĮję▓Ģ■╩▄Ųõė░ĒæŻ╗«öėąČÓéĆę└┘ćūā┴┐Ģr╔±Įøį¬ŠWĮj╩ŪūŅ╝čĄ─▀xō±Ż╗═¼ĢrŻ¼╔±Įøį¬ŠWĮjī”ĢrķgĒśą“Ą─öĄō■Ą─╠Ä└Ē─▄┴”▒╚▌^║├ĪŻī”ĘŪŠĆąįĪóėąįļ궥─Å═ļsöĄō■Ęų╬÷ą¦╣¹┴╝║├Ż╗─▄╠Ä└ĒęÄ─Ż▌^┤¾Ą─öĄō■ÄņŻ╗─▄ŅA£y▀B└möĄō■Ż¼ĘųŅÉ╗“Š█ŅÉļx╔óöĄō■Ż╗─▄╠Ä└Ēėąįļę¶╗“ī┘ąįųĄėą╚▒╩¦Ą─öĄō■ĪŻ╔±ĮøŠWĮj╠žäe▀m║Ž─Ūą®─Ż║²Īó▓╗ć└├▄Īó▓╗═Ļš¹Ą─ų¬ūR(öĄō■)×ķ╠žš„Ą─Ż¼╗“─Ūą®╚▒╔┘ŪÕ╬·Ą─Ęų╬÷öĄō■Ą─öĄīW╦ŃĘ©Ą─å¢Ņ}ĪŻ
2.4 Š█ŅÉĘų╬÷
╩╣ė├Š█ŅÉĘų╬÷Ģrūā┴┐┐╔ęį╩Ū▀B└m╗“ĘųŅÉūā┴┐Ż¼ī”├┐éĆš{▓ķī”Ž¾Ą─öĄō■欫ö╩Ū═Ļš¹Ą─ĪŻį┌┐╔─▄Ą─ŪķørŽ┬Ż¼▒M┴┐▒▄├Ōė├╠µ┤·ųĄ╠Ņča╚▒╩¦ųĄŻ¼╝┤╩╣▀@¤oĘ©▒▄├ŌŻ¼ę▓欫öęŌūRĄĮ▀@Ģ■ė░ĒæĮY╣¹Ż¼ę“×ķ▀@śė╦∙ū÷Ą─īŹļH╔Ž╩Ūį┌ŠÄįņöĄō■ĪŻŠ█ŅÉĘų╬÷ųąöĄō■ĮYśŗ×ķöĄō■ŠžĻć║═▓Ņ«ÉČ╚ŠžĻćŻ¼öĄō■ŅÉą═░³└©ģ^ķgś╦Č╚ūā┴┐(IntervalĪ¬scaled variables)ĪóČ■į¬ūā┴┐(Binary variables)Īóś╦ĘQą═Ż¼ą“öĄą═║═▒╚└²ą═ūā┴┐(Nominal ordinalŻ¼Ż¼and ratio variables)ęį╝░╗ņ║ŽŅÉą═ūā┴┐(Variables of mixed types)4ĘNĪŻ
2.5 ūŅĮ³ÓÅ╝╝ąg
▀mė├ė┌ĘŪČ©┴┐öĄō■Ż¼─▄╠Ä└ĒĘųŅÉą═öĄō■Ż¼öĄūųą═öĄō■║═ūųĘ¹ą═öĄō■ĪŻ
2.6 ęÄät═Ų└Ē
ĘŪČ©┴┐öĄō■Ż¼▀mė┌╠Ä└Ē┤¾ą═öĄō■ĪŻ
2.7 Ģrķgą“┴ąĘų╬÷
Ģrķgą“┴ąĘų╬÷į┌╠Ä└Ē║═ĢrķgŠ▀ėąŽÓĻPąįĄ─ŪķørĢrėą¬Ü╠žĄ─ā×ä▌Ż¼ė├ė┌╠Ä└Ēėąą“ļSÖCūā┴┐╗“š▀ėąą“öĄō■Ż¼▓óŪęė^£yųĄų«ķg▓╗¬Ü┴óĪŻ
2.8 ▀zé„╦ŃĘ©
┐╔ė├ė┌ĘųŅÉ║═ŅA£yŻ¼┐╔ęįĮŌøQĘŪŠĆąįĪóČÓūā┴┐ĪóĘŪ▀B└mĪóĘŪ┐╔ī¦┐šķg╔ŽĄ─ā×╗»å¢Ņ}ĪŻį┌╦∙Ū¾å¢Ņ}×ķĘŪ▀B└mĪóČÓĘÕęį╝░ėąįļ궥─ŪķørŽ┬Ż¼▀zé„╦ŃĘ©Ą─ā×ä▌Ė³╝ė├„’@Ż¼╦³─▄ęį║▄┤¾Ą─Ė┼┬╩╩šö┐ĄĮūŅā×ĮŌ╗“ØMęŌĮŌŻ¼Š▀ėą▌^║├Ą─╚½Šų╩šö┐ąįĪŻ
2.9 ─Ż║²╝»
«öŠ½┤_▌ö╚ļ▓╗┐╔─▄╗“╠½░║┘FĢrŻ¼─Ż║²ŽĄĮyŠ═┐╔ęįū„×ķę╗ĘNÅŖėą┴”Ą──Żą═ĘĮĘ©ĪŻ
2.10 ┤ų▓┌╝»└Ēšō
┤ų▓┌╝»└Ēšō╩Ūę╗ĘN蹊┐▓╗═Ļš¹öĄō■Īó▓╗┤_Č©ų¬ūRĄ─▒Ē▀_ĪóīW┴Ģ╝░Üw╝{Ą─öĄīWĘĮĘ©ĪŻ╦³×ķĘų╬÷▓╗Š½┤_öĄō■Īó═Ų└Ē║══┌Š“öĄō■å¢Ą─ĻPŽĄĪó░l¼FØōį┌Ą─ų¬ūR╠ß╣®┴╦ąąų«ėąą¦Ą─╣żŠ▀ĪŻ╦³ęįĖ„ĘNĖ³ĮėĮ³╚╦éāī”╩┬╬’Ą─├Ķ╩÷ĘĮ╩ĮĄ─Č©ąįĪóČ©ę╔╗“╗ņ║Žą┼Žó×ķ▌ö╚ļŻ¼▌ö╚ļ┐šķg║═▌ö│÷┐šķg╩Ū═©▀^║åå╬Ą─øQ▓▀▒Ē║å╗»Ą├ĄĮĄ─ĪŻ
3 ŅA£y─Żą═Ą─įuār
▓╗═¼Ą──Żą═ėąŲõĖ„ūį▀mė├Ą─ł÷║ŽŻ¼ę“┤╦į┌▓╗═¼Ą─ŅA£yå¢Ņ}ųąę¬Ė∙ō■Š▀¾wĄ─Ūķør║═─Żą═Ą─╠ž³cüĒ▀xō±ŅA£y─Żą═ĪŻ
╚ń╣¹ŅA£yĄ─ĮY╣¹╩Ūė├ė┌ŠÄųŲėŗäØ╗“ū÷ŠC║ŽøQ▓▀Ż¼└Ēšō╔ŽšfŻ¼▒╚▌^└ĒŽļĄ─▐kĘ©╩Ū▓╔ė├ČÓūā┴┐ŅA£y─Żą═ĪŻ╚ń╣¹ę¬ŅA£yĄ─ī”Ž¾║▄ČÓŻ¼▓╔ė├å╬ūā┴┐Ą─ŅA£yĘĮĘ©▒╚▌^Ūą║ŽīŹļHĪŻ
ę╗░ŃŪķørŽ┬ĪŻųĖöĄŲĮ╗¼ĘĮĘ©║═ūį╗žÜwĪ¬Ī¬ęŲäėŲĮŠ∙ĘĮĘ©Ą─ŅA£yŠ½Č╚Č╝▒╚▌^Ė▀Ż¼ųĖöĄŲĮ╗¼ĘĮĘ©ė├ė┌Č╠Ų┌ŅA£y─▄ē“Ą├ĄĮ┴╝║├Ą─ą¦╣¹Ż¼─▄ē“▀_ĄĮūŅ┤¾Ą─Š½┤_Č╚ĪŻūį╗žÜwĪ¬Ī¬ęŲäėŲĮŠ∙ĘĮĘ©Ą─╦ŃĘ©▒╚▌^Å═ļsŻ¼╦³Ą─ā׳c╩Ū┐╔ęįÅ──Żą═ųą╝ėęį▀xō±Ż¼Č°▓╗▒žŠųŽ▐ė┌ę╗éĆ╠žČ©Ą──Żą═Ż¼╚▒³c╩Ūį┌▀xō±─Żą═ĢrąĶꬊ▀ėą▒╚▌^žSĖ╗Ą─Įø“×║═Š½═©▀@ĘNĘĮĘ©Ą─╚╦ĪŻ
å╬ūā┴┐╗žÜw║═ČÓūā╠║╗žÜw─Żą═Ą─ŅA£yŲ┌Ž▐▒╚ųĖöĄŲĮ╗¼ĘĮĘ©Ė³▀hę╗ą®Ż¼┐╔ė├ė┌ųąŲ┌ŅA£yĪŻ╦³Ą─┴Ēę╗éĆā׳c╩Ū─▄ē“Ę┤ė│ā╔éĆ╗“ā╔éĆęį╔Žūā┴┐ų«ķgĄ─ŽÓ╗źĻPŽĄŻ¼─▄ē“═©▀^ī”ę╗éĆūā┴┐Ą─ŅA£y┴ó╝┤Ą├ĄĮ┴Ēę╗éĆūā┴┐Ą─ŅA£yųĄĪŻį┌Į©┴óČÓūā┴┐╗žÜw─Żą═ĢrŻ¼▓╔ė├ų▓Į╗žÜwĘĮĘ©Š▀ėą┴╝║├Ą─ĮY╣¹Ż¼╦³─▄╠▐│²▓╗ųžę¬Ą─ę“╦žŻ¼Å─Č°╩╣╗žÜw─Żą═▒M┐╔─▄Ąž║åå╬ĪŻ
ėŗ┴┐ĮøØ·─Żą══©│Żė├ū„ŠC║ŽąįŅA£yŻ¼╦³Ą─ā׳c╩Ūī”╚╬║╬å╬ę╗ĘĮ│╠Ą─ūįūā┴┐ų«ķgĄ─ŽÓ╗źĻPŽĄŻ¼┐╔ęį░³└©į┌Ųõ╦¹ĘĮ│╠╩ĮųąŻ¼╦³éāĄ─öĄųĄ┐╔ęį═¼Ģr┤_Č©ĪŻĖ∙ō■ęį╔ŽĄ─Ęų╬÷Ż¼┐╔ęį└¹ė├īė┤╬Ęų╬÷Ę©üĒ▀Mąąī”ŅA£y─Żą═Ą─▀xō±ĪŻīė┤╬ĮYśŗ─Żą═ęŖłD1ĪŻ
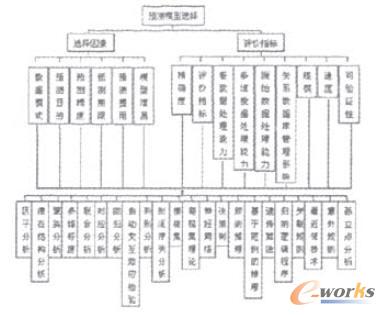
łD1 īė┤╬ĮYśŗ─Żą═
į┌īŹ█`ųąŻ¼ėąĢr─Żą═ķgĄ─▓Ņäe║▄ąĪŻ¼▀xō±ūŅ║├Ą──Żą═Ż¼╩Ūį┌─ŻöMŚl╝■Ž┬ī”║“▀x─Żą═▀Mąą“×ūCŻ¼─ŻöMą¦╣¹ūŅ║├Ą─Š═╩ŪūŅāץ──Żą═Ż╗į┌ĘĮĘ©╔ŽŻ¼ėąĢrąĶ═¼Ģræ¬ė├ÄūĘNĘĮĘ©Ż¼╚ńę“ūėĘų╬÷═∙═∙║═╗žÜwĘų╬÷╗“Š█ŅÉĘų╬÷ę╗Ų╩╣ė├Ż¼Š█ŅÉĘų╬÷║═┼ąäeĘų╬÷ĮY║Ž╩╣ė├Ą╚ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║CRMŅA£y─Żą═Ą─įuār┼c▀xō±
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/solutions/1401936257.html