ĪĪĪĪļSų°╗ź┬ōŠW╝╝ągĄ─░lš╣Ż¼öĄėŅą┼Žóš²į┌│╔ųĖöĄį÷╝ėŻ¼Ė∙ō■Internet Data CenteŻ║░l▓╝Ą─Digital Universeł¾Ėµ’@╩ŠŻ¼į┌╬┤üĒ8─Ļųą╦∙«a╔·Ą─öĄō■┴┐īó▀_ĄĮ40 ZBŻ¼ŽÓ«öė┌├┐╚╦«a╔·5200 GĄ─öĄō■Ż¼╚ń║╬Ė▀ą¦Ąžėŗ╦Ń║═┤µā”▀@ą®║Ż┴┐öĄō■│╔×ķ╗ź┬ōŠWŲ¾śI╦∙ę¬Č°ī”Ą─╠¶æĪŻé„ĮyĄ─┤¾ęÄ─ŻöĄō■╠Ä└Ē┤¾ČÓ▓╔ė├▓óąąėŗ╦ŃĪóŠWĖ±ėŗ╦ŃĪóĘų▓╝╩ĮĖ▀ąį─▄ėŗ╦ŃĄ╚Ż¼║─┘M░║┘FĄ─┤µā”┼cėŗ╦Ń┘Yį┤Ż¼Č°Ūęī”ė┌┤¾ęÄ─ŻöĄō■ėŗ╦Ń╚╬䚥─ėąą¦Ęų┼õ║═öĄō■║Ž└ĒĘųĖŅČ╝ąĶę¬Å═ļsĄ─ŠÄ│╠▓┼┐╔ęįīŹ¼FĪŻ╗∙ė┌HadoopĘų▓╝╩ĮįŲŲĮ┼_Ą─│÷¼F│╔×ķĮŌøQ┤╦ŅÉå¢Ņ}Ą─┴╝║├═ŠÅĮŻ¼▒Š╬─īóį┌ŠC╩÷Hadoop║╦ą─╝╝ągŻ║HDFS║═MapReduce╗∙ĄA╔ŽŻ¼└¹ė├VMware╠ōöMÖC┤ŅĮ©ę╗éĆ╗∙ė┌HadoopĘų▓╝╩Į╝╝ągĄ─Ė▀ą¦ĪóęūöUš╣Ą─įŲöĄō■ėŗ╦Ń┼c┤µā”ŲĮ┼_Ż¼▓ó═©▀^īŹ“ד×ūCĘų▓╝╩Įėŗ╦Ń┼c┤µā”Ą─ā×ä▌ĪŻ
ĪĪĪĪ1ĪóHadoop╝░ŲõŽÓĻP╝╝ąg
ĪĪĪĪHadoop╩Ū▓óąą╝╝ągĪóĘų▓╝╩Į╝╝ąg║═ŠWĖ±ėŗ╦Ń╝╝ąg░lš╣Ą─«a╬’Ż¼╩Ūę╗ĘN×ķ▀mæ¬┤¾ęÄ─ŻöĄō■ėŗ╦Ń║═┤µā”Č°░lš╣ŲüĒĄ──Żą═╝▄śŗĪŻHadoop╩ŪApache╣½╦ŠŲņŽ┬Ą─ę╗éĆĘų▓╝╩Įėŗ╦Ń║═┤µā”Ą─┐“╝▄ŲĮ┼_Ż¼─▄ē“Ė▀ą¦┤µā”┤¾┴┐öĄō■Ż¼Č°Ūę┐╔ęįŠÄīæĘų▓╝╩Įæ¬ė├│╠ą“üĒĘų╬÷ėŗ╦Ń║Ż┴┐öĄō■ĪŻHadoop┐╔į┌┤¾┴┐┴«ārė▓╝■įOéõ╝»╚║ųą▀\ąą│╠ą“Ż¼×ķĖ„æ¬ė├│╠ą“╠ß╣®┐╔┐┐ĘĆČ©Ą─Įė┐┌üĒśŗĮ©Ė▀öUš╣ąį║═Ė▀┐╔┐┐ąąĄ─Ęų▓╝╩ĮŽĄĮyĪŻHadoopŠ▀ėą│╔▒ŠĄ═┴«Īó┐╔┐┐ąįĖ▀Īó╚▌ÕeąįĖ▀ĪóöUš╣ąįÅŖĪóą¦┬╩Ė▀Īó┐╔ęŲų▓ąįÅŖĪó├Ō┘Mķ_į┤Ą─ā׳cĪŻ
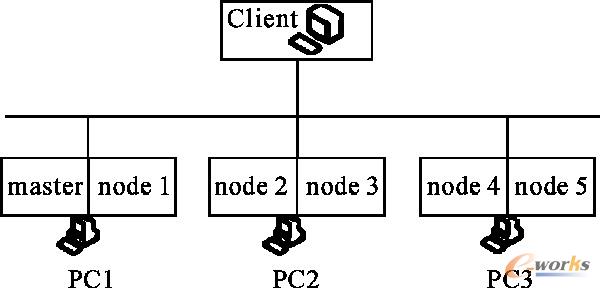
ĪĪĪĪHadoop╝»╚║×ķĄõą═Master/SlaveĪóĮYśŗŻ¼╗∙ė┌HadoopĄ─įŲėŗ╦Ń┼c┤µā”╝▄śŗ─Żą═╚ńłD1╦∙╩ŠĪŻ
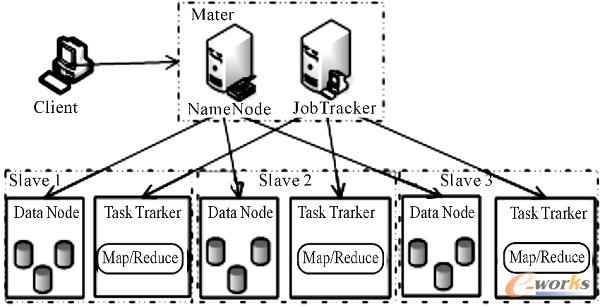
łD 1 ╗∙ė┌HadoopĄ─įŲėŗ╦Ń┼c┤µā”╝▄śŗ─Żą═
ĪĪĪĪ1.1ĪĪHadoopĘų▓╝╩Į╬─╝■ŽĄĮyHDFS
ĪĪĪĪHDFS╩Ūę╗éĆ▀\ąąį┌┤¾┴┐┴«ārė▓╝■ų«╔ŽĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╦³╩ŪHadoopŲĮ┼_Ą─Ąūīė╬─╝■┤µā”ŽĄĮyŻ¼ų„꬞ōž¤öĄō■Ą─╣▄└Ē║═┤µā”Ż¼ī”ė┌┤¾╬─╝■Ą─öĄō■įL墊▀ėą┴╝║├ąį─▄ĪŻHDFS┼cé„ĮyĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŽÓ╦ŲŻ¼Ą½╩Ūę▓┤µį┌ų°ę╗Č©Ą─▓╗═¼Ż¼Š▀ėąė▓╝■╣╩šŽĪó┤¾öĄō■╝»Īó║åå╬ę╗ų┬ąįĪóöĄō■┴„╩ĮįLå¢ĪóęŲäėėŗ╦ŃĄ─▒ŃĮ▌ąįĄ╚╠ž³cĪŻHDFSĄ─╣żū„┴„│╠╝░╝▄śŗ╚ńłD2╦∙╩ŠĪŻ
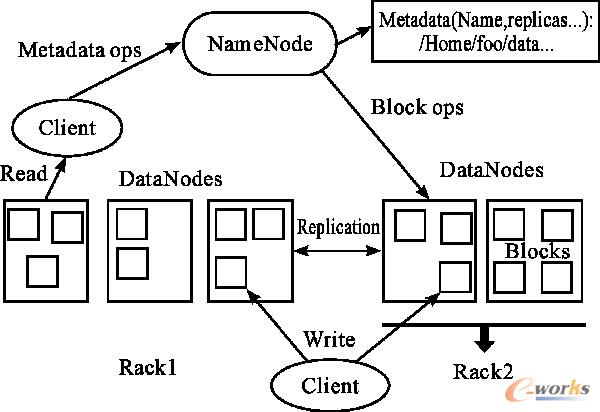
łD 2 HDFSĄ─╣żū„┴„│╠╝░╝▄śŗĮYśŗ
ĪĪĪĪę╗éĆHDFS╝»╚║ųąėąę╗éĆNameNode║═ČÓéĆDataNodeĪŻ╚ńłD2╦∙╩ŠŻ¼NameNode╩Ūųąą─Ę■äšŲ„Ż¼╦³ė├üĒ╣▄└Ē╬─╝■ŽĄĮyĄ─į¬öĄō■ą┼Žóęį╝░┐═æ¶Č╦ī”╬─╝■Ą─ūxīæįLå¢Ż¼ŠSūo╬─╝■ŽĄĮyśõ╝░Ųõūė╣سcŽ┬Ą─╦∙ėą╬─╝■║═─┐õøĪŻ▀@ą®ą┼ŽóęįŠÄ▌ŗ╚šųŠ╬─╝■(Editlog)║═├³├¹┐šķgńRŽ±╬─╝■(FsImage)Ą─ą╬╩Į▒Ż┤µį┌┤┼▒PųąĪŻNameNode▀ĆĢ║Ģrėøõøų°Ė„éĆēK(Block)╦∙į┌Ą─DataNodeą┼ŽóĪŻŲõ╣”─▄ų„ę¬ėąŻ║╣▄└Ēį¬öĄō■║═╬─╝■ēKŻ╗║å╗»į¬öĄō■Ė³ą┬▓┘ū„Ż╗▒O┬Ā║═╠Ä└ĒšłŪ¾ĪŻ
ĪĪĪĪDataNode═©│Żį┌╝»╚║ųąę╗éĆ╣سcę╗éĆŻ¼ė├üĒ┤µā”ĪóÖz╦„öĄō■ēKŻ¼Ēææ¬NameNodeŽ┬▀_Ą─äōĮ©ĪóÅ═ųŲĪóäh│²öĄō■ēKĄ─├³┴ŅŻ¼▓óČ©ĢrŽ“NameNode░l╦═“ą─╠°”Ż¼═©▀^ą─╠°ą┼ŽóŽ“NameNodeģRł¾ūį╝║Ą─žō▌dŪķørŻ¼═¼Ģr═©▀^ą─╠°ą┼ŽóüĒĮė╩▄NameNodeŽ┬▀_Ą─ųĖ┴Ņą┼ŽóŻ╗NameNode═©▀^“ą─╠°”ą┼ŽóüĒ┤_Č©DataNode╩Ūʱ╩¦ą¦Ż¼╦³Č©Ģrping├┐éĆDataNodeŻ¼╚ń╣¹į┌ęÄČ©Ą─Ģrķgā╚ø]ėą╩šĄĮDataNodeĄ─Ę┤üŠ═šJ×ķ┤╦╣سc╩¦ą¦Ż¼╚╗║¾ī”š¹éĆŽĄĮy▀Mąąžō▌dš{š¹ĪŻį┌HDFSųąŻ¼├┐éĆ╬─╝■äØĘų│╔ę╗éĆ╗“ČÓéĆblocks(öĄō■ēK)Ęų╔ó┤µā”į┌▓╗═¼Ą─DataNodeųąŻ¼DataNodeų«ķg▀MąąöĄō■ēKĄ─ŽÓ╗źÅ═ųŲČ°ą╬│╔ČÓéĆéõĘ▌ĪŻ
ĪĪĪĪ1.2ĪĪMap/ReduceŠÄ│╠┐“╝▄
ĪĪĪĪMap/Reduce╩ŪHadoopė├üĒ╠Ä└ĒįŲėŗ╦Ńųą║Ż┴┐öĄō■Ą─ŠÄ│╠┐“╝▄Ż¼║åå╬ęūė├Ż¼│╠ą“åTį┌▓╗▒ž┴╦ĮŌĄūīėīŹ¼F╝Ü╣ØĄ─╗∙ĄA╔Ž▒Ń┐╔īæ│÷│╠ą“üĒ╠Ä└Ē║Ż┴┐öĄō■ĪŻ└¹ė├Map/Reduce╝╝ąg┐╔ęįį┌öĄŪ¦▓┐Ę■äšŲ„╔Ž═¼Ģrķ_š╣ÅVĖµśIäš║═ŠWĮj╦č╦„Ą╚╚╬䚯¼▓ó┐╔ęįĘĮ▒ŃĄž╠Ä└ĒTBĪóPBŻ¼╔§ų┴╩ŪEB╝ēĄ─öĄō■ĪŻ
ĪĪĪĪMap/Reduce┐“╝▄ė╔JobTracker║═TaskTrackerĮM│╔ĪŻJobTrackerų╗ėąę╗éĆŻ¼╦³╩Ūų„╣سcŻ¼žōž¤╚╬䚥─Ęų┼õ║═š{Č╚Ż¼╣▄└Ēų°ÄūéĆTaskTrackerŻ╗TaskTrackerę╗éĆ╣سcę╗éĆŻ¼ė├üĒĮė╩▄▓ó╠Ä└ĒJobTracker░lüĒĄ─╚╬äšĪŻ
ĪĪĪĪMapReduceßśī”╝»╚║ųąĄ─┤¾ą═öĄō■╝»▀MąąĘų▓╝╩Į▀\╦ŃŻ¼╦³Ą─š¹éĆ┐“╝▄ė╔Map║═Reduce║»öĄĮM│╔Ż¼╠Ä└ĒöĄō■ĢrŽ╚ł╠ąąmapį┘ł╠ąąreduceĪŻŠ▀¾wł╠ąą▀^│╠╚ńłD3╦∙╩ŠĪŻł╠ąąmap║»öĄŪ░Ž╚ī”▌ö╚ļöĄō■▀MąąĘųŲ¼Ż╗╚╗║¾īó▓╗═¼Ą─Ų¼Č╬Ęų┼õĮo▓╗═¼Ą─mapł╠ąąŻ¼map║»öĄ╠Ä└Ēų«║¾ęį(key,value)Ą─ą╬╩Į▌ö│÷Ż╗į┌▀M╚ļreduceļAČ╬Ū░Ż¼map║»öĄŽ╚īóįŁüĒĄ─(key,value)Ęų│╔ČÓĮMųąķgĄ─µIųĄī”į┘░lĮoę╗éĆreducer▀Mąą╠Ä└ĒŻ╗ūŅ║¾reduce║»öĄ║Ž▓ókeyŽÓ═¼Ą─valueŻ¼▓ó▌ö│÷ĮY╣¹ĄĮ┤┼▒P╔ŽĪŻ

łD 3 MapReduceėŗ╦Ń▀^│╠
ĪĪĪĪ2Īó╗∙ė┌HadoopĄ─įŲėŗ╦Ń┼c┤µā”ŲĮ┼_įOėŗ
ĪĪĪĪ─┐Ū░Ż¼ČÓ║╦ėŗ╦ŃÖCĄ─ÅVĘ║╩╣ė├╩╣Ųõį┌┤ŅĮ©Hadoop╝»╚║ŽĄĮyĢrŻ¼ĘųĮoĖ„DataNode╣سcĄ─ČÓéĆ╚╬äšĢ■«a╔·ī”┘Yį┤Ą─ĖéĀÄŻ¼└²╚ńŻ║ā╚┤µĪóCPUĪó▌ö╚ļ▌ö│÷ĦīÆĄ╚Ż¼▀@Ģ■ī¦ų┬Ģ║Ģrė├▓╗ĄĮĄ─┘Yį┤╠Äė┌ķeų├ĀŅæBŻ¼ų┬╩╣ę╗ą®┘Yį┤Ą─└╦┘Męį╝░Ēææ¬ĢrķgĄ─čėķLŻ¼┘Yį┤ķ_õNĄ─į÷╝ėūŅĮKĢ■ī¦ų┬ŽĄĮyąį─▄Ą─ĮĄĄ═ĪŻ×ķĮŌøQ┤╦å¢Ņ}Ż¼▒ŠčąŠ┐╠ß│÷ę╗ĘN╗∙ė┌VMware╠ōöMÖC║═HadoopŽÓĮY║ŽĄ─╝»╚║ŁhŠ│─Żą═Ż¼╚ńłD4╦∙╩ŠŻ¼╝┤į┌ę╗┼_ėŗ╦ŃÖCųą┤ŅĮ©ČÓ┼_╠ōöM▓┘ū„ŽĄĮyŻ¼┤╦ĘNū÷Ę©Ą─ā׳c╩Ū┐╔ęįį÷╝ėDataNode║═TaskTracker╣سcŻ¼Č°Ūę┐╔ęį│õĘų└¹ė├╬’└Ē┘Yį┤Ż¼╠ßĖ▀▀\╦Ń║═┤µā”Ą─ą¦┬╩ĪŻ
łD 4 ╗∙ė┌VMware╠ōöMÖC║═HadoopĮY║ŽĄ──Żą═
ĪĪĪĪ3ĪóīŹ“×ŲĮ┼_┤ŅĮ©
ĪĪĪĪ3. 1ė▓╝■ŁhŠ│┼õų├
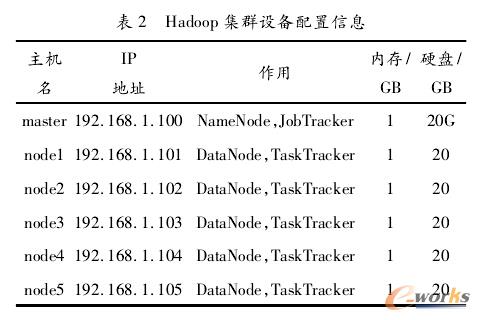
ĪĪĪĪ£╩éõ3┼_ļp║╦ėŗ╦ŃÖCŻ¼▓óĘųäe░▓čb2┼_VMware╠ōöMÖC▄ø╝■Ż¼į┌╠ōöMÖCųąčb╚ļLinux OSŻ¼Å─Č°īó3┼_ėŗ╦ŃÖCöUš╣│╔×ķ6┼_ėŗ╦ŃÖCŻ¼3┼_ėŗ╦ŃÖCŠ▀ėąŽÓ═¼Ą─┼õų├Ż¼┼õų├Š▀¾w╚ń▒Ē1╦∙╩ŠĪŻ

ĪĪĪĪHadoop╝»╚║░³└©1éĆNameNodeĘ■äšŲ„║═5éĆDataNodeį┬╝░äšŲ„Ż¼┼õų├ą┼Žó╚ń▒Ē2╦∙╩ŠĪŻ
ĪĪĪĪ3.2ĪĪHadoopŁhŠ│┤ŅĮ©
ĪĪĪĪHadoopŁhŠ│┤ŅĮ©▀^│╠×ķŻ║┼õų├╝»╚║hosts┴ą▒ĒĪó░▓čbJAVA JDKŽĄĮy▄ø╝■Īó┼õų├ŁhŠ│ūā┴┐Īó╔·│╔ĄŪĻæ├▄ĶĆĪóäōĮ©ė├æ¶Äż╠¢║═Hadoop▓┐╩─┐õø╝░öĄō■─┐õøĪó┼õų├hadoopenv.shŁhŠ│ūā┴┐Īó┼õų├core-site. xmlĪóhdfs-site. xmlĪómapred-site. xmlĪŻ
ĪĪĪĪ┼õų├═Ļ«ģų«║¾▀MąąĖ±╩Į╗»╬─╝■Ż¼├³┴Ņ×ķŻ║
ĪĪĪĪ/opt/modules/hadoop/hadoop-1.0.3/bin/hadoop namenode deformat
ĪĪĪĪ╚╗║¾åóäė╦∙ėą╣سcŻ¼▌ö╚ļ├³┴ŅŻ║startall.shĪŻ═©▀^ĮńČ°▓ķ┐┤╝»╚║╩Ūʱ▓┐╩│╔╣”Ż¼╩ūŽ╚Öz▓ķNameNode║═DataNode╣سc╩Ūʱš²│ŻŻ¼┤“ķ_×gė[Ų„▌ö╚ļŠWųĘŻ║httpŻ║ //masterŻ║ 50070Ż¼╚¶Live Nodesėą6éĆŻ¼šf├„╚½▓┐╣سc│╔╣”åóäėĪŻ╚╗║¾Öz▓ķJobTracker║═TaskTracker╣سcŻ¼▌ö╚ļŠWųĘŻ║httpŻ║ //masterŻ║50030Ż¼╚¶Nodes╣سcėą6éĆšf├„╣سcåóäė│╔╣”ĪŻ
ĪĪĪĪ4ĪóīŹ“×ā╚╚▌╝░ĮY╣¹Ęų╬÷
ĪĪĪĪį┌▓┐╩║├Ą─HadoopįŲöĄō■ėŗ╦Ń┼c┤µā”ŲĮ┼_╔Ž▀MąąīŹ“×üĒ“×ūC╗∙ė┌Ęų▓╝╩ĮöĄō■ėŗ╦Ń║═┤µā”Ą─ĘĮĘ©į┌öĄō■ėŗ╦Ń║═┤µā”╔Ž┤µį┌ā×ä▌ĪŻ
ĪĪĪĪ1)īŹ“×ę╗Ż║▀\ąąHadoopūįĦĄ─├╔╠ž┐©┬ÕŪ¾PI│╠ą““×ūC╗∙ė┌HadoopĘų▓╝╩ĮįŲėŗ╦ŃĄ─Ė▀ą¦ąįĪŻėŗ╦Ń╚╬äšįO×ķ10éĆŻ¼ėŗ╦Ń┴┐×ķ10Ą─3 Īó4Īó5 Īó6┤╬ĘĮĪŻ
ĪĪĪĪŁhŠ│ę╗Ż║å╬ÖCŪķørŽ┬▀\ąąŻ╗
ĪĪĪĪŁhŠ│Č■Ż║3┼_╬’└ĒÖC┤ŅĮ©Ą─╝»╚║ŽĄĮyųą▀\ąąŻ╗
ĪĪĪĪŁhŠ│╚²Ż║6┼_╠ōöMÖC┤ŅĮ©Ą─╝»╚║ŽĄĮyųą▀\ąąĪŻ╝»╚║ŁhŠ│▀\ąą╚šųŠ╚ńłD5╦∙╩ŠĪŻ
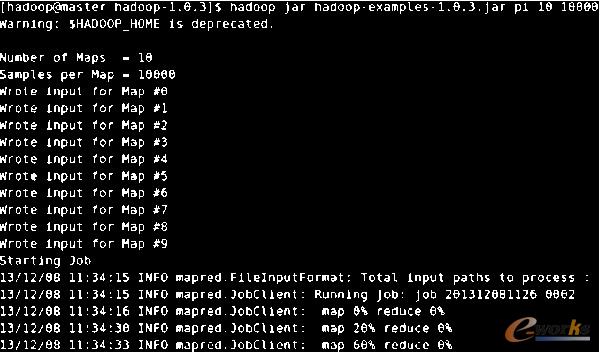
łD 5 ├╔╠ž┐©┬ÕŪ¾PI│╠ą“▀\ąą╚šųŠ
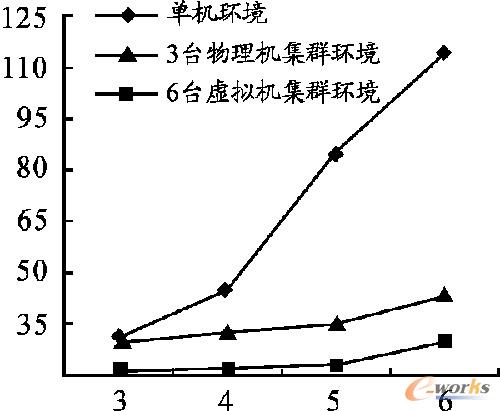
ĪĪĪĪ├┐ĮMīŹ“×▀\ąą5┤╬Ū¾╦∙ąĶĢrķgĄ─ŲĮŠ∙ųĄŻ¼ėŗ╦Ńł╠ąąĢrķgĮY╣¹╚ńłD6╦∙╩ŠŻ¼┐v▌S×ķĢrķg/sŻ¼ÖM▌S╩Ūėŗ╦Ń┴┐/┤╬ĘĮĪŻÅ─łD6ųą┐╔ęį┐┤│÷å╬ÖCŁhŠ│Ž┬Ą─▀\╦ŃĢrķg▀h▀h┤¾ė┌Ęų▓╝╩ĮŽĄĮyŽ┬Ą─▀\╦ŃĢrķgŻ¼Č°Ūę╝»╚║ŽĄĮyųąĄ─╣سcįĮČÓėŗ╦Ń╦┘Č╚įĮ┐ņĪŻ
ĪĪĪĪ2)īŹ“×Č■Ż║═©▀^▀\ąąėŅĘ¹Įyėŗ│╠ą“(wordcounter.jar)£yįć╗∙ė┌HadoopĘų▓╝╩ĮįŲöĄō■ūxīæĄ─Ė▀ą¦ąįüĒ“×ūCŲõ┤µā”ąį─▄ĪŻėą4ĮMöĄō■Ż¼┤¾ąĪĘųäe×ķ400MBĪó600MBĪó1GB║═1.5GBĪŻ
ĪĪĪĪ▒ŠĮMīŹ“×įOų├HadoopēK┤¾ąĪ×ķ16M─¼šJŪķørŽ┬╩Ū64 M ) ,╚▀ėÓéõĘ▌ģóöĄįOų├×ķ3(─¼šJųĄ)Ż¼īŹ“ףhŠ│═¼īŹ“×ę╗Ż¼│╠ą“▀\ąą5┤╬Ż¼ėøõøĢrķg▓óėŗ╦ŃŲĮŠ∙ųĄŻ¼▀\ąą╚šųŠ╚ńłD7╦∙╩ŠĪŻ
łD 7 ūųĘ¹Įyėŗ│╠ą“▀\ąą╚šųŠ
ĪĪĪĪ▀\ąąĮY╣¹╚ńłD8╦∙╩ŠŻ¼┐v▌S×ķł╠ąąĢrķg/sŻ¼ÖM▌S×ķöĄō■┴┐/MBĪŻÅ─łD8ųą┐╔ęįĄ├│÷å╬ÖCŁhŠ│Ž┬Ą─öĄō■ūxīæ╦┘Č╚├„’@Ą═ė┌Ęų▓╝╩ĮŁhŠ│Ž┬Ą─╦┘Č╚Ż¼Č°Ūę╣سcįĮČÓūxīæ╦┘Č╚įĮ┐ņĪŻ
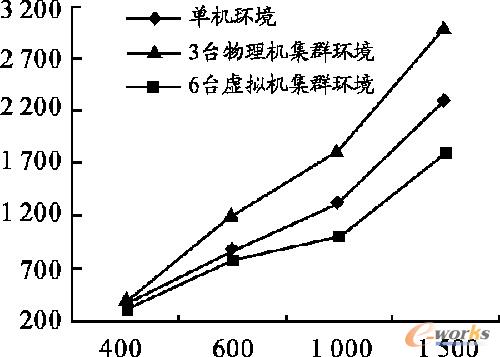
łD 8 ūųĘ¹Įyėŗ│╠ą“į┌3ĘNŁhŠ│ųąĄ─ąį─▄ī”▒╚
ĪĪĪĪ┐╔ęį┐┤│÷Ż¼┼cé„ĮyöĄō■ėŗ╦Ń┼cūxīæĘĮ╩ĮŽÓ▒╚Ż¼▒Š╬─╠ß│÷Ą─į┌╠ōöM╗»ŁhŠ│Ž┬┤ŅĮ©Ą─╗∙ė┌HadoopĘų▓╝╩Į╝╝ągĄ─įŲėŗ╦Ń┼c┤µā”ŲĮ┼_Ż¼ėąą¦Ąž╠ßĖ▀┴╦║Ż┴┐öĄō■Ęų╬÷┼cūxīæĄ─╦┘Č╚║═ą¦┬╩Ż╗Č°Ūę└¹ė├╠ōöM╗»╝╝ąg┤ŅĮ©Ą─╝»╚║▒╚╬’└ĒÖC╝»╚║ą¦┬╩Ė³Ė▀Ż¼╦┘Č╚Ė³┐ņŻ¼Å─Č°┤¾┤¾╠ßĖ▀┴╦┘Yį┤Ą─└¹ė├┬╩ĪŻ
ĪĪĪĪ5ĪóĮY╩°šZ
ĪĪĪĪ▒Š╬─═©▀^ī”HadoopĘų▓╝╩Į╬─╝■ŽĄĮyHDFSĪó MapReduceŠÄ│╠┐“╝▄▀MąąčąŠ┐Ż¼└¹ė├VMware╠ōöMÖC┤ŅĮ©╗∙ė┌HadoopĄ─įŲöĄō■ėŗ╦Ń┼c┤µā”ŲĮ┼_Ż¼▓ó═©▀^īŹ“ד×ūCŲõŽÓī”ė┌é„ĮyöĄō■╠Ä└ĒĘĮ╩ĮŠ▀ėąĖ▀ą¦Īó┐ņ╦┘Ą─╠ž³cŻ¼ØMūŃįŲėŗ╦ŃŅIė“Ą─ŽÓĻPąĶŪ¾Ż╗Č°Ūę═©▀^æ¬ė├╠ōöM╗»╝╝ągüĒöUš╣╣سcöĄ┴┐Ż¼╝╚╠ßĖ▀┴╦▀\ąąą¦┬╩ėų╠ßĖ▀┴╦ė▓╝■┘Yį┤Ą─└¹ė├┬╩Ż¼×ķĮ±║¾įŲėŗ╦ŃĄ─蹊┐ĘĮŽ“┤“Ž┬┴╦╗∙ĄAĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌HadoopĄ─įŲėŗ╦Ń┼c┤µā”ŲĮ┼_蹊┐┼cīŹ¼F
▒Š╬─ŠWųĘŻ║http://m.guhuozai8.cn/html/consultation/10839716289.html